
-
Ceph 对象存储深度解析系列 第二部分:RGW 数据路径、分片和自动化
简介
在本深度解析的第一部分中,我们剖析了 Ceph RGW 内部的高性能请求路径。我们涵盖了其无状态前端、基础 RADOS 存储池以及关键的桶索引,揭示了动态分片如何使单个桶内的对象列表实现几乎无限的可扩展性。
我们确立了 RGW 如何大规模高效地定位和列出对象。现在,我们将焦点从索引转移到对象本身以及管理它们的更广泛系统。在本次深度解析的第二部分中,我们将通过检查 RGW 元数据布局来探索控制平面。然后,我们将揭示 S3 对象如何使用 head/tail 数据模型进行物理存储,并以对关键后台进程(垃圾回收和生命周期管理)的审视作为总结,这些进程实现了数据治理的自动化。
RGW 元数据布局:控制平面的蓝图
就像单个 S3 对象的数据精心组织在 RADOS 中一样,整个 RGW 系统的状态、其用户、桶和策略也持久存储在专用的 RADOS 存储池中。这种设计是 RGW 守护进程无状态特性的基础;所有控制平面信息都存在于集群本身,而不是网关上。这些元数据主要存放在
.rgw.meta存储池中,而垃圾回收和生命周期管理等过程的操作日志则存放在.rgw.log存储池中。这些元数据对象以内部二进制格式存储。因此,使用
radosgw-admin命令行工具进行管理和交互至关重要。此实用程序可以可靠地将二进制记录解码为人类可读的 JSON,并确保任何修改都安全执行。注意:切勿尝试使用
rados工具直接修改.rgw.meta存储池中的对象。关键元数据类别
.rgw.meta存储池使用 RADOS 命名空间在逻辑上分离不同类型的信息。当你查询元数据时,你会遇到几个顶级类别:-
user:存储 S3 用户记录,包括访问密钥、功能、使用配额和联系信息,包括电子邮件。 -
bucket:高级命名桶记录。这包含基本信息,包括桶所有者、其放置策略(它属于哪个区域)和各种标志。 -
bucket.instance:表示桶的具体物理实例。此记录跟踪桶的唯一 ID、索引的分片计数、版本控制状态和创建时间戳。单个桶名称在其生命周期中可以有多个实例,例如当它被删除和重新创建时。 -
roles:包含策略评估引擎用于授予临时凭证的 STS(安全令牌服务)和 IAM 角色定义。 -
group:定义用户组,可用于管理操作或策略管理。 -
topic:存储 S3 桶事件通知的配置。 -
otp:保存用于多因素身份验证的一次性密码凭证。 -
account:如果启用了 Swift API,则用于 Swift 帐户元数据。
使用 radosgw-admin 检查元数据
radosgw-admin工具提供了一种安全且结构化的方式来探索此控制平面数据。首先,您可以列出所有可用的元数据类别:$ radosgw-admin metadata list [ "user", "bucket", "bucket.instance", "roles", ... ] $ radosgw-admin metadata list account [ "RGW42603947660038067", "RGW46950437120753278", "RGW40572530565246530", "RGW66892093834478914", "RGW63384910224424377", "RGW94705908964376531", "RGW25531238860968914" ]
接下来,列出某个类别中的特定键,例如
bucket或bucket.instance:# 列出所有桶名称 $ radosgw-admin metadata list bucket | grep bucket1 "bucket1", # 列出所有具体的桶实例 $ radosgw-admin metadata list bucket.instance | grep bucket1 "bucket1:7fb0a3df-9553-4a76-938d-d23711e67677.34162.1",
最后,这里是一个使用其键检索和解码特定记录的示例。将输出通过管道传输到
jq以便格式化 JSON 输出以提高可读性:# 按名称获取桶元数据 $ radosgw-admin metadata get bucket:bucket1 | jq . # 按 UID 获取用户记录 $ radosgw-admin metadata get user:my-user-id | jq .
值得一提的是,
radosgw-admin通过特定的 CLI 参数使我们能够直接与这些元数据进行交互,从而大大简化了我们的工作。例如:radosgw-admin user、radosgw-admin account、radosgw-admin bucket等。将元数据链接到使用情况
为了弥合抽象元数据与实际使用之间的差距,
radosgw-admin提供了聚合这些信息的命令:# 获取桶的详细统计信息,包括其分片计数、对象计数和大小 $ radosgw-admin bucket stats --bucket <BUCKET_NAME> | jq . # 获取单个对象的完整元数据,正如 RGW 所见 $ radosgw-admin object stat --bucket <BUCKET_NAME> --object <OBJECT_KEY> | jq .
这个
object stat命令非常方便,因为它显示了特定 S3 对象的清单、放置信息和所有系统属性,从网关的角度提供了完整的视图。RGW 数据布局: Head/Tail 对象模型
一个逻辑 S3 对象通常由多个物理 RADOS 对象组成。RGW 采用灵活的 head/tail 对象模型,可以针对各种文件大小和复杂操作(包括 Multipart 上传 (MPU))进行优化。
与任何 S3 对象关联的主要 RADOS 对象是头对象。它的 RADOS 对象名称通常由桶的内部标记与对象键连接而成,并用下划线分隔,例如
<bucket_marker>_<object_key>。头对象有两个主要目的。首先,它是所有对象级元数据的权威存储,包括 ACL、HTTP 内容类型、ETag 和任何用户定义的元数据。这些信息以 RADOS 扩展属性 (xattrs) 的形式高效存储在头对象上。其次,对于小对象(默认情况下,最大可配置为rgw_max_chunk_size的对象),S3 对象的整个数据负载直接存储在头对象的数据部分。这是一个关键的性能优化,因为它允许数据及其相关元数据在单个原子 RADOS 操作中写入集群,从而最大程度地减少小文件工作负载的 I/O 放大和延迟。对于超出此内联数据大小的对象,头对象的数据负载用于存储清单。此清单是一种元数据结构,描述了对象其余数据在集群中的物理布局。它包含其他 RADOS 对象的有序列表,这些对象称为尾对象,它们保存了其余的数据块。清单中的每个条目都指定了尾对象的名称、其大小以及其在完整 S3 对象中的逻辑偏移量。
如果对象大小超过
rgw_max_chunk_size(默认值:4MB),数据将分条存储在多个 RADOS 对象中:一个头对象(仅包含元数据/清单)和一个或多个尾对象(包含大量数据)。我们可以检索默认的分条大小,它控制着数据拆分何时发生:
$ ceph config get mon rgw_obj_stripe_size 4194304
此输出确认默认的 RGW 对象分条大小为 4,194,304 字节 (4MB)。
客户端定义的分块大小与 RGW 内部条带大小 (
rgw_obj_stripe_size) 之间的交互可能导致创建特定命名的尾对象。如果客户端上传的分块(例如 5 MiB)大于 RGW 条带大小(例如 4 MiB),RGW 将自动将该分块分条到多个 RADOS 对象。例如,如果使用 MPU,它可能会创建一个以__multipart为前缀的 4 MiB 对象,并创建一个以__shadow为前缀的 1 MiB 对象来保存剩余部分。这些只是名称遵循特定约定的尾对象,并且两者都将在最终清单中正确引用。在这里,我们观察一个大文件的头对象:
$ aws --endpoint=http://ceph-node02:8080 s3 cp awscliv2.zip s3://bucket1/bigfile $ aws --endpoint=http://ceph-node02:8080 s3 ls s3://bucket1/bigfile 2022-12-20 15:10:16 20971520 bigfile $ rados -p default.rgw.buckets.data ls | grep bigfile$ 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1_bigfile
这是
bigfile的头对象。它包含对象的 xattrs 元数据,包括user.rgw.manifest,其中列出了所有尾对象的位置。头对象将其元数据高效地存储为扩展属性:
$ rados -p default.rgw.buckets.data listxattr 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1_bigfile user.rgw.acl user.rgw.content_type user.rgw.etag user.rgw.idtag user.rgw.manifest user.rgw.pg_ver user.rgw.source_zone user.rgw.tail_tag user.rgw.x-amz-content-sha256 user.rgw.x-amz-date
列出的扩展属性 (xattr) 确认头对象存储了关键的对象元数据,特别是
user.rgw.manifest,它描述了大型对象的数据负载如何拆分为尾对象。radosgw-admin object stat命令可以通过 RGW 元数据显示对象的清单分条/分块:$ radosgw-admin object stat --bucket BUCKET --object OBJECT | jq .我们示例中的尾对象:
# rados -p default.rgw.buckets.data ls | grep shadow_bigfile 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__shadow_bigfile.2~E_PYNwiBq0la0EuZcCOY30KgmRrf1pV.1_1 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__shadow_bigfile.2~E_PYNwiBq0la0EuZcCOY30KgmRrf1pV.2_1
尾对象通常包含 4MB 的数据块:
default.rgw.buckets.data/7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__shadow_bigfile.2_E_PYNwiBq0la0EuZcCOY30KgmRrf1pV.1_1 mtime 2022-12-20T15:10:16.000000-0500, size 4194304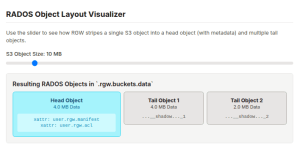
S3 Multipart 上传:原子提交操作
S3 Multipart 上传 (MPU) 功能旨在通过将大对象分成可以独立并行上传的小部分来高效上传大对象。RGW 将此优雅地实现为元数据提交操作。
工作流程包括三个关键步骤:
-
Multipart 上传初始化:发送请求以获取唯一的上传 ID。
-
部分上传:使用上传 ID 和唯一的部件 ID 上传单个部件。每个部件都存储为独立的临时 RADOS 对象。如果部件大小超过 RGW 分条大小(默认 4MB),它将在内部进行分段。
-
Multipart 上传完成(原子提交):当所有部件上传完毕后,客户端发送完成请求。RGW 避免了昂贵的数据复制。相反,它会创建最终的头对象,并使用指向构成部件的临时 RADOS 对象的指针填充其内部清单。这使得完成操作几乎是瞬时的。
这种设计使得从集群的角度来看,大型对象上传的完成几乎是瞬时发生的。在这种情况下,头对象本身不包含用户数据,这就是为什么低级工具会报告其大小为 0 字节;其有效载荷是清单,而不是对象内容。
RADOS 中的 MPU 结构
当文件以块(例如 5MB 块)上传,且 RGW 条带宽度为 4 MiB 时,RGW 会处理内部拆分:它取前 4 MiB 创建一个“Multipart”RADOS 对象,然后取剩余的 1 MiB 创建一个“影子”尾部 RADOS 对象。
让我们通过一个例子来验证。我们将客户端分块大小设置为 5 MiB,并上传一个 20 MiB 的文件:
$ aws configure set default.s3.multipart_chunksize 5MB $ aws --endpoint=http://ceph-node02:8080 s3 cp text.txt s3://bucket1/5chuncks
我们向 RGW 发送 5 MiB 的分块,而 RGW 的分条宽度为 4 MiB,这意味着 RGW 将首先取出 4 MiB 并创建一个“多部分”RADOS 对象,然后创建一个 1 MiB 的“影子”RADOS 尾对象。
$ rados -p default.rgw.buckets.data ls | grep 5chuncks 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__shadow_5chuncks.2_r3yyxqL2hYs5DW32L9UXR3uawF4VEKL.2_1 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__multipart_5chuncks.2_r3yyxqL2hYs5DW32L9UXR3uawF4VEKL.2 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__shadow_5chuncks.2_r3yyxqL2hYs5DW32L9UXR3uawF4VEKL.3_1 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__shadow_5chuncks.2_r3yyxqL2hYs5DW32L9UXR3uawF4VEKL.4_1 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__multipart_5chuncks.2_r3yyxqL2hYs5DW32L9UXR3uawF4VEKL.4 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__shadow_5chuncks.2_r3yyxqL2hYs5DW32L9UXR3uawF4VEKL.1_1 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__multipart_5chuncks.2_r3yyxqL2hYs5DW32L9UXR3uawF4VEKL.3 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1_5chuncks 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__multipart_5chuncks.2_r3yyxqL2hYs5DW32L9UXR3uawF4VEKL.1
输出显示了各种组件的创建,包括最终的头对象(…
_5chuncks),以及与分条部分对应的多个多部分和影子对象。这些对象的大小验证演示了 RGW 的拆分逻辑:多部分头 RADOS 对象为 4 MiB,尾部(影子)RADOS 对象为 1 MiB。
# 检查主要 4MB 块的大小 $ rados -p default.rgw.buckets.data stat 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__multipart_5chuncks.2_r3yyxqL2hYs5DW32L9UXR3uawF4VEKL.2 default.rgw.buckets.data/7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__multipart_5chuncks.2_r3yyxqL2hYs5DW32L9UXR3uawF4VEKL.2 mtime 2022-12-21T03:07:49.000000-0500, size 4194304 # 检查剩余 1MB 块的大小 $ rados -p default.rgw.buckets.data stat 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__shadow_5chuncks.2_r3yyxqL2hYs5DW32L9UXR3uawF4VEKL.2_1 default.rgw.buckets.data/7fb0a3df-9553-4a76-938d-d23711e67677.34162.1__shadow_5chuncks.2_r3yyxqL2hYs5DW32L9UXR3uawF4VEKL.2_1 mtime 2022-12-21T03:07:49.000000-0500, size 1048576
这些部分不会在 RADOS 中组装或合并:这是它们的最终状态。
最后,完成的 S3 对象的头 RADOS 对象仅包含元数据清单,这就是为什么它在 RADOS 级别报告大小为零字节的原因:
$ rados -p default.rgw.buckets.data stat 7fb0a3df-9553-4a76-938d-d23711e67677.34162.1_5chuncks default.rgw.buckets.data/7fb0a3df-9553-4a76-938d-d23711e67677.34162.1_5chuncks mtime 2022-12-21T03:07:49.000000-0500, size 0
有关 Multipart 上传的更多信息,请参阅 AWS Multipart 上传(https://docs.aws.com/AmazonS3/latest/userguide/mpuoverview.html)。
异步垃圾回收器 (GC)
当客户端删除 S3 对象或覆盖它们时,底层的 RADOS 对象不会立即删除。对象删除的主要功能是更新桶索引(如果版本控制处于活动状态,则放置删除标记)。一旦 S3 对象从索引中删除,其底层的 RADOS 对象就会有效地“孤立”。
这些孤立的 RADOS 对象随后被插入到垃圾回收 (GC) 队列中。垃圾回收器是 RGW 中一个关键的后台进程,负责异步回收这些已删除对象所占用的存储空间。这种设计确保客户端的
DELETE请求能够快速返回,而无需等待物理清除数据块的缓慢过程。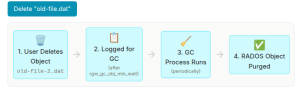
对于对象流失率高(创建和删除频繁)的工作负载,GC 进程可能会滞后,导致可回收空间堆积。为了解决这个问题,管理员可以调整几个关键参数,使 GC 更具侵略性:
-
rgw_gc_obj_min_wait:删除对象符合回收条件之前的最短等待时间。缩短此时间(默认 2 小时)可加快空间回收。 -
rgw_gc_max_concurrent_io:GC 线程可以发出的并行 RADOS 删除操作的数量。将其从默认值10增加允许 GC 同时处理更多对象,但代价是集群上的后台 I/O 会更高。 -
rgw_gc_processor_period:GC 处理周期的间隔。值越低意味着 GC 线程运行频率越高。 -
rgw_gc_max_trim_chunk:单批处理的日志条目数量。
我们可以使用以下命令列出所有计划删除的对象:
$ radosgw-admin gc list $ radosgw-admin gc list --include-all
默认情况下,Ceph 在 GC 周期之间等待 2 小时。要手动运行 GC 删除过程,请执行:
$ radosgw-admin gc process --include-all可以执行此命令来强制垃圾回收器手动处理其积压的工作,确保快速回收空间,而无需等待下一个计划运行。
注意:在正在运行的集群中,
rgw_gc_max_objs选项绝不应修改其默认值。此值仅应在部署 RGW 之前修改(如果需要)。另请注意:
radosgw-admin可以接受--bypass-gc选项来立即删除底层存储,但我们强烈建议 不要 传递此选项。具有大量 S3 对象流失的部署,也可能会发现部署一组专用 RGW 守护进程只处理 GC 事件,并在面向客户端的守护进程中禁用 GC 事件的价值。
生命周期 (LC) 管理
生命周期 (LC) 管理引擎根据应用于桶的用户定义策略自动化数据管理。这些策略由根据对象年龄或其他标准触发操作的规则组成。常见的操作包括
Expiration(删除对象)和Transition(将对象移动到不同的存储类别)。生命周期转换可以在集群内任意存储类别(层)之间定义,或转换为外部 S3 兼容端点,其中包括 AWS、IBM Cloud 或 S3 磁带端点: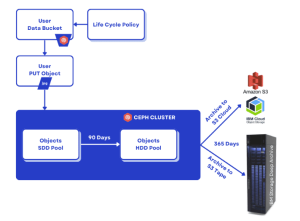
您可以使用精细过滤器在 RGW 中优化 S3 生命周期过期:
-
当前与非当前对象版本
-
过期删除标记 (
ExpiredObjectDeleteMarker) -
自动中止未完成的 Multipart 上传 (
AbortIncompleteMultipartUpload) -
通过
NewerNoncurrentVersions限制保留的旧版本 -
使用
ObjectSizeGreaterThan和ObjectSizeLessThan按对象大小范围定义规则
这些过滤器与 S3 标签的使用相结合,可以以令人难以置信的粒度大规模控制清理行为。
LC 引擎实现为一组多线程工作进程。这些工作进程定期扫描集群中的桶索引。对于它们遇到的每个对象,它们都会根据桶的生命周期策略评估其属性。如果满足规则的条件,则执行相应的操作。
Expiration操作实际上会触发标准删除,删除对象的索引条目并将其数据排队等待 GC。Transition操作涉及将对象的数据复制到目标存储池(可以是不同的介质层甚至是远程云层),然后更新对象的元数据以反映其新位置。为了跨大型集群进行扩展,LC 引擎的并行性是可调的:-
rgw_lc_max_worker:这控制主工作线程的数量,这些线程并行处理多个桶索引分片。对于具有大量桶的集群,应增加此值。 -
rgw_lc_max_wp_worker:这定义了每个工作池中的子线程数量,这些线程并行处理单个分片中的对象。对于具有少量桶但每个桶包含大量 S3 对象的集群,应增加此值。
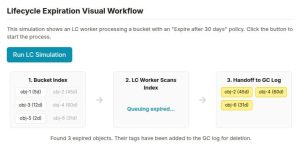
以下是一个
radosgw-admin命令,列出了集群中配置的 LC 作业:$ radosgw-admin lc list | jq . [ { "bucket": ":ingest:fcabdf4a-86f2-452f-a13f-e0902685c655.47553.1", "shard": "lc.0", "started": "Sat, 11 Oct 2025 11:20:59 GMT", "status": "COMPLETE" }, { "bucket": ":tierbucket:fcabdf4a-86f2-452f-a13f-e0902685c655.323278.10", "shard": "lc.3", "started": "Sat, 11 Oct 2025 11:20:56 GMT", "status": "COMPLETE" }, ]
我们可以使用以下形式的命令获取特定桶的信息。此规则使用带有 k/v
processed:true的对象标签作为过滤器,以使早于一天的对象过期。$ # radosgw-admin lc get --bucket ingest { "prefix_map": { "": { "status": true, "dm_expiration": false, "expiration": 1, "noncur_expiration": 0, "mp_expiration": 0, "obj_tags": { "tagset": { "processed": "true" } }, "transitions": {}, "noncur_transitions": {} } }, "rule_map": [ { "id": "Delete objects that are older than 24 hours", "rule": { "id": "Delete objects that are older than 24 hours", "prefix": "", "status": "Enabled", "expiration": { "days": "1", "date": "" }, "noncur_expiration": { "days": "", "date": "" }, "mp_expiration": { "days": "", "date": "" }, "filter": { "prefix": "", "obj_tags": { "tagset": { "processed": "true" } } }, "transitions": {}, "noncur_transitions": {}, "dm_expiration": false } } ] }
结论
在这次分为两部分的深度解析中,我们深入探讨了 Ceph RGW 的核心架构支柱。从高性能前端和桶索引分片的复杂机制,到优雅的 head/tail 数据布局以及自动化的后台进程,我们现在对 RGW 如何实现其卓越的可伸缩性和灵活性有了全面、端到端的理解。
理解架构只是第一步。要真正掌握 Ceph RGW,我们必须学习如何在复杂的实际环境中进行调优、保护和操作。
-
云和安全管理服务商


