
-
Ceph 对象存储深度解析系列 第一部分:RGW 核心基础
导言:无状态的强大引擎
Ceph 对象网关 (RGW) 远不止一个代理;它是一个高级抽象层,在底层的可靠自治分布式对象存储 (RADOS) 之上无缝提供 Amazon S3 和 OpenStack Swift RESTful API。对于存储架构师来说,RGW 至关重要,因为它将标准的 HTTP 对象操作请求转换为直接针对集群执行的本地 RADOS 操作。这使得为流行云对象存储生态系统构建的应用程序无需修改即可利用 Ceph 集群作为其存储后端。
RGW 设计的基本原则是其无状态特性。这一关键的架构决策是其大规模横向扩展能力和高可用性的基石。由于 RGW 守护进程不维护与客户端会话相关的任何持久状态,因此只需在标准负载均衡器后面部署更多 RGW 实例,即可实现接近线性的性能扩展。任何单个 RGW 守护进程的故障都不是关键事件,因为负载均衡器可以将客户端流量重定向到其余健康的实例,从而使最终用户对中断无感知。所有关键状态,包括用户元数据、桶定义、ACL 和对象数据,都持久存储在 RADOS 集群中的指定存储池中。
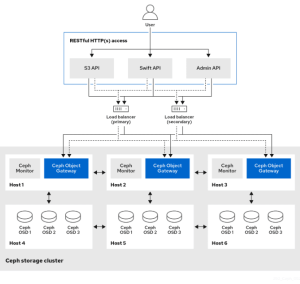
在本次深度解析的第一部分中,我们将深入研究 RGW 的前端组件、存放其内部元数据的专用 RADOS 存储池,以及实现高性能对象操作的桶索引和分片的关键机制。
RGW 前端
传入 RGW 守护进程的客户端请求会经过多个内部层,首先是处理初始 HTTP 连接的前端 Web 服务器。RGW 历来支持两种主要嵌入式前端:传统的默认选项 Civetweb,以及现代、高性能的默认选项 Beast。
Civetweb 基于同步的“每连接一线程”模型运行。相比之下,Beast 是一个基于 Boost.Asio C++ 库构建的现代前端,它采用异步、事件驱动的 I/O 模型。Beast 不会为每个连接分配一个线程,而是使用一个小的 worker 线程池来并发处理数千个连接。这种模型在 CPU 和内存利用率方面效率显著更高,因为线程不会因等待 I/O 而阻塞,并且每个连接的内存开销也大大减少。从 Civetweb 到 Beast 的架构转变直接响应了现代云原生应用程序的需求,这些应用程序通常会生成高并发、高 IOPS 的工作负载。
前端配置实践
使用 cephadm 部署或修改 RGW 服务时,可以直接在服务规范文件中指定前端类型及其设置。Beast 是 RGW 前端的默认且推荐选项:
service_type: rgw sService_id: myrealm.myzone spec: rgw_realm: myrealm rgw_zone: myzone ssl: true rgw_frontend_port: 1234 rgw_frontend_type: beast rgw_frontend_ssl_certificate: ...
此 YAML 片段说明了 cephadm 如何部署 RGW 服务,指定域 (realm) 和区域 (zone),启用 SSL 终止,并显式将
rgw_frontend_type设置为 TCP 端口 1234 上的beast。理解 RGW RADOS 存储池
为了使 RGW 作为真正无状态的组件运行,所有关键信息、用户数据、元数据和日志都必须持久存储在 RADOS 层中。这种持久性是通过一组专门的、专用的 RADOS 存储池来实现的。
RGW 的多存储池架构是一个充分考虑后的设计选择,它允许用户将不同类别的数据物理上分离到不同的硬件层,从而实现性能和成本的高度优化平衡。例如,对延迟敏感的元数据和日志可以放置在由 SSD 介质支持的快速副本池上。同时,容量密集型对象负载可以驻留在由较慢、更具成本效益的 HDD 或越来越多地采用 QLC 级 SSD 支持的纠删码池上。NVMe SSD 优于传统的 SAS/SATA SSD,因为它们提供了面向未来的兼容性、更好的密度和更高的性价比。NVMe 服务器的成本实际上可能低于 SATA 服务器。
关键 RGW 存储池及其用途
存储池名称后缀 用途 典型数据保护 推荐介质 .rgw.root 存储全局 RGW 配置(域、区域组、区域) 副本 SSD .rgw.control 内部 RGW 守护进程协调 副本 SSD .rgw.meta 用户和桶元数据 副本 SSD .rgw.log 操作和复制日志 副本 SSD .rgw.buckets.index 桶对象列表 (omaps)。对性能至关重要 副本 SSD .rgw.buckets.data 主要对象数据负载 纠删码 TLC/QLC SSD, HDD .rgw.buckets.non-ec 辅助存储池,用于与纠删码不兼容的操作 副本 SSD / HDD 当 RGW 服务首次尝试操作不存在的 RADOS 存储池时,它将使用配置选项
osd_pool_default_pg_num和osd_pool_default_pgp_num的值创建该存储池。这些默认值足以满足某些存储池的需求,但其他存储池(特别是那些在placement_pools中列出的桶索引和数据存储池)将需要额外调整。请注意,当启用 PG 自动缩放器时,它将自动调整这些存储池的放置组值,并为.index存储池增加BIAS,以便它们分配到的 PG 数量超过其聚合数据所指示的通常数量。为了使自动缩放器与 RGW 存储池的群集更好地配合,我们建议将以下值从其默认值提高:# ceph config set global mon_target_pg_per_osd 300 # ceph config set global mon_max_pg_per_osd 600
特定于 RGW 区域的存储池名称遵循
zone-name.pool-name的命名约定。例如,名为us-east的区域将拥有以下存储池:.rgw.root us-east.rgw.control us-east.rgw.meta us-east.rgw.log us-east.rgw.buckets.index us-east.rgw.buckets.data
这些存储池的结构对于理解 RGW 的操作机制至关重要。许多逻辑存储池通过主 RADOS 存储池内的 RADOS 命名空间(例如,
default.rgw.log)进行整合。我们可以使用以下形式的命令列出 RADOS 命名空间。这里我们可以看到
rgw.meta pool如何包含三个不同的 RADOS 命名空间:# rados ls -p default.rgw.meta --all | awk '{ print $1 }' | sort -u root users.keys users.uid
当查询 RGW 区域配置时,会暴露带有其命名空间的存储池:
$ radosgw-admin zone get --rgw-zone default { "id": "d9c4f708-5598-4c44-9d36-849552a08c4d", "name": "default", "domain_root": "default.rgw.meta:root", "control_pool": "default.rgw.control", "gc_pool": "default.rgw.log:gc", "lc_pool": "default.rgw.log:lc", "log_pool": "default.rgw.log", "intent_log_pool": "default.rgw.log:intent", "usage_log_pool": "default.rgw.log:usage", "roles_pool": "default.rgw.meta:roles", "reshard_pool": "default.rgw.log:reshard", "user_keys_pool": "default.rgw.meta:users.keys", "user_email_pool": "default.rgw.meta:users.email", "user_swift_pool": "default.rgw.meta:users.swift", "user_uid_pool": "default.rgw.meta:users.uid", "otp_pool": "default.rgw.otp", ... "placement_pools": [ { "key": "default-placement", "val": { "index_pool": "default.rgw.buckets.index", "storage_classes": { "STANDARD": { "data_pool": "default.rgw.buckets.data" } }, "data_extra_pool": "default.rgw.buckets.non-ec", "index_type": 0 } } ], "realm_id": "", "notif_pool": "default.rgw.log:notif" }
这个 JSON 输出详细描述了默认区域的配置。请注意,许多不同的逻辑功能(GC、LC、使用日志)都映射到 RADOS 存储池
default.rgw.log,但使用 RADOS 命名空间(例如default.rgw.log:gc)进行了分离。桶索引和分片的详细概述
列出桶内容的能力是对象存储的基础。RGW 使用一种称为桶索引的专用结构来实现这一点,该结构负责列出桶内容、维护版本化操作的日志、存储配额元数据,并作为多区域同步的日志。
桶索引和 OMAP
桶索引依赖于 RADOS 对象的一个特殊功能,称为对象映射 (OMAP)。OMAP 是与 RADOS 对象关联的键值存储,概念上类似于 POSIX 文件中的扩展属性。对于每个桶,RGW 会在
.rgw.buckets.index存储池中创建一个或多个专用索引对象。该桶中对象的列表信息存储在这些索引对象的 OMAP 中。至关重要的是,桶索引的性能完全依赖于底层的键值数据库:OMAP 物理存储在 OSD 的 DB 分区中的 RocksDB 数据库中。这要求像
`default.rgw.buckets.index这样的索引池目前必须使用副本数据保护方案,因为 OMAP 操作与纠删码池不兼容。为 OSD 的 DB 分区投资快速闪存设备(SSD,理想情况下是 NVMe)对于桶列表性能至关重要。RGW 索引池可以选择一个 CRUSH 规则,将其放置在纯 SSD OSD 上,或者放置在将 DB 卸载到 SSD 的混合 OSD 上。由于 OMAP 纯粹位于给定 OSD 的 DB 部分,因此两种策略都足够。调优索引池以提高性能
虽然 OSD DB 的快速存储至关重要,但桶索引在集群中的分布同样重要。这由索引池的放置组 (PG) 数量控制。PG 调优不当是导致列表性能不佳的常见原因,尤其是在大型集群中。
放置组 (PG) 数量和并行性
每个 PG 都映射到一组 OSD,其中一个充当主 OSD。当 RGW 执行桶列表时,它会向许多不同的桶索引分片对象的 OMAP 发送并行读取请求。索引池的 PG 数量越高,这些分片就分布在更多的主要 OSD 上。这增加了列表操作的并行性,因为更多的物理设备可以并发地处理 I/O 请求。PG 数量过低会导致瓶颈,即许多请求集中到少数 OSD 上,这些 OSD 随后会饱和。
我们建议每个索引池至少有一个 PG 用于其所在的每个 OSD。当使用 PG 自动缩放器时,索引池应自动具有 4 的 BIAS 值,以便它们接收更多的 PG。请参阅上文关于中央配置设置的建议,以允许自动缩放器为索引池提供足够的 PG。
可视化桶索引日志
首先,我们确认桶索引池的存在和池 ID:
$ ceph osd lspools | grep default.rgw.buckets.index 6 default.rgw.buckets.index
这里我们看到 ID 为
6的 RADOS 存储池是default区域的专用索引存储池。现在,让我们获取一个桶名称作为示例:
bucket1:$ radosgw-admin bucket list | grep bucket1 "bucket1",
接下来,我们可以使用
radosgw-admin检查default区域中特定桶bucket1的索引条目:$ radosgw-admin bi list --bucket bucket1 [ { "type": "plain", "idx": "hosts5", "entry": { "name": "hosts5", "instance": "", "ver": { "pool": 16, "epoch": 3 }, "locator": "", "exists": "true", "meta": { "category": 1, "size": 4066, "mtime": "2022-12-14T16:27:02.562603Z", "etag": "71ad37de1d442f5ee2597a28fe07461e", "storage_class": "", "owner": "test", "owner_display_name": "test", "content_type": "", "accounted_size": 4066, "user_data": "", "appendable": "false" }, "tag": "_iDrB7rnO7jqyyQ2po8bwqE0vL_Al6ZH", "flags": 0, "pending_map": [], "versioned_epoch": 0 } } ]
radosgw-admin bi list输出显示了 S3 对象 (hosts5) 存储的元数据,包括大小、修改时间 (mtime) 和 ETag。实现系统可扩展性的关键机制:桶分片
当桶索引变得非常庞大时,会出现一个显著的性能问题。如果桶的索引存储在一个 RADOS 对象中,则一次只能执行一个操作。这种序列化限制了并行性,并可能成为高吞吐量写入工作负载的严重瓶颈。
为了规避这一限制,RGW 采用了桶索引分片。这种机制将桶索引分成多个部分,每个分片存储在索引池中一个独立的 RADOS 对象上。当写入对象时,更新将根据对象名称的哈希值定向到特定的分片。这允许在不同的放置组 (PG) 和 OSD 上并发执行多个操作,从而提高整体可伸缩性。分片数量应为质数,可通过
bucket_index_max_shards配置选项进行配置(默认为11)。我们可以使用radosgw-admin bucket stats命令获取有关桶和对象的元数据信息,例如分片数量、桶使用情况、配额、版本控制、对象锁定、所有者等。$ radosgw-admin bucket stats --bucket bucket1 | grep shards "num_shards": 11,
默认区域的桶索引池:
$ ceph osd lspools | grep default.rgw.buckets.index 6 default.rgw.buckets.index
我们可以通过视觉确认这些分片作为独立的 OMAP RADOS 对象存在:
$ rados -p default.rgw.buckets.index ls .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.9 .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.0 .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.10 .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.1 .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.7 .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.8 .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.2 .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.6 .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.5 .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.4 .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.3
这里列出的每个
.dirRADOS 对象都是一个独立的桶索引分片。在此示例中,可以看到 11 个分片,与每个桶的默认分片数量匹配。在创建桶时,初始分片数量由区域组级别的
bucket_index_max_shards选项设置,并用于所有桶。如果特定桶需要不同的分片数量,则可以更改它。注意:我们建议每个桶索引分片最多包含 102,400 个 S3 对象。
我们可以使用 stats 命令获取桶的标记:
$ radosgw-admin bucket stats --bucket bucket1 | grep marker "marker": "7fb0a3df-9553-4a76-938d-d23711e67677.34162.1",
现在我们知道
bucket1的 标记 是7fb0a3df-9553-4a76-938d-d23711e67677.34162.1。让我们将名为file1的对象上传到bucket1:$ aws --endpoint=http://ceph-node02:8080 s3 cp /etc/hosts s3://bucket1/file1 --region default upload: ../etc/hosts to s3://bucket1/file1
让我们在 RADOS 级别检查此桶的桶索引。通过列出桶索引对象上的 omapkeys,我们可以看到一个名为
file1的键,它与上传的对象名称匹配。这里我们正在对 11 个可用分片对象中的一个(本例中为分片 2)执行 listomapkeys。如前所述,对象将在创建过程中分散到不同的分片中。$ rados -p default.rgw.buckets.index listomapkeys .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.2 file1
当我们检查值时,可以看到
bucket1的桶索引分片2omap 对象中的键/值条目大小为 217 字节。在十六进制转储中,我们看到包括对象名称在内的信息。$ rados -p default.rgw.buckets.index listomapvals .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.2 file1 value (217 bytes) : 00000000 08 03 d3 00 00 00 05 00 00 00 66 69 6c 65 31 01 |..........file1.| 00000010 00 00 00 00 00 00 00 01 07 03 5a 00 00 00 01 32 |..........Z....2| 00000020 05 00 00 00 00 00 00 4b ab a1 63 95 74 ba 04 20 |.......K..c.t.. |
当我们向桶中添加更多 S3 对象时,我们看到每个添加到桶可用分片中的新键/值条目。在此示例中,
file1、file2、file4、file10都落在了分片2中:$ rados -p default.rgw.buckets.index listomapkeys .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.2 file1 file2 file4 file10
我们可以确认特定分片(分片
2)的放置位置:$ ceph osd map default.rgw.buckets.index .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.2 osdmap e90 pool 'default.rgw.buckets.index' (9) object '.dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.2' -> pg 9.6fa75bc9 (9.9) -> up ([1,2], p5) acting ([1,2], p5)
此输出显示索引分片在集群中复制并位于特定的 OSD 上。将索引分布在多个 PG(以及因此的 OSD)上可以实现并行性。
为什么索引池看起来是空的
当你查询桶索引池的空间使用情况时,结果常常让不熟悉 Ceph OMAP 架构的工程师感到惊讶:
$ rados df -p default.rgw.buckets.index POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR default.rgw.buckets.index 0 B 11 0 33 0 0 0 208 207 KiB 41 20 KiB 0 B 0 B
甚至检查单个分片对象(分片 2)也显示大小为零:
$ rados -p default.rgw.buckets.index stat .dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.2 default.rgw.buckets.index/.dir.7fb0a3df-9553-4a76-938d-d23711e67677.34162.1.2 mtime 2022-12-20T07:32:11.000000-0500, size 0
尽管包含 11 个 RADOS 对象(分片),但该存储池报告使用了 0 字节。这是因为桶索引列表数据完全作为 OMAP 条目存储在每个 OSD 的 RocksDB 数据库中,而不是作为有效载荷数据存储在 RADOS 对象本身中。这证实了为什么至少为 OSD DB 分区利用快速闪存介质(SSD)对于最大限度地提高桶索引性能至关重要。
通过动态桶重分片管理索引增长
当一个桶扩展到数十万或数百万个 S3 对象时,其索引可能会成为性能瓶颈。默认情况下,单个分片可能会因为积累了太多条目而变得“热点”。每个分片的 S3 对象数量阈值是可配置的,默认为 100,000。每个桶中过多的 S3 对象数量会重新引入分片旨在解决的序列化问题。为了解决这个问题,RGW 引入了一种称为动态桶重分片 (DBR) 的高级自动化机制。
DBR 是一个后台进程,它持续监控每个桶索引分片中的条目数量。当分片增长超出其配置阈值时,DBR 会自动在线触发重分片操作。此过程会创建一组新的索引对象,其中包含更多的分片,然后安全地将现有索引条目从旧的、较小的布局迁移到新的、较大的布局。

在线重分片的演变:最大限度地减少影响
从历史上看,重分片操作需要暂时暂停对桶的写入 I/O。虽然读取操作不受影响,但这种写入暂停在非常活跃的工作负载上可能会很明显且令人痛苦。
然而,在发布的 Tentacle 版本中,一项重大增强功能已大幅减少了这种写入冻结。新的实现使得重分片过程几乎透明,允许写入以最小的干扰进行。这项改进是向前迈出的重要一步,使得动态重分片成为即使是最苛刻的环境也能无缝、生产安全的特性。
不仅是增长,还有收缩:分片合并的力量
动态重分片不仅限于向上扩展。考虑这样一个场景:一个曾经包含数百万个对象的桶,其中大量的对象已被删除。现在这个桶包含许多稀疏填充甚至为空的索引分片。这效率低下,因为列表操作仍然必须检查每个分片,增加了不必要的开销。
为了解决这个问题,DBR 机制也得到了增强以支持分片合并。正如 Ceph 文档和开发跟踪器(例如 BZ#2135354(https://bugzilla.redhat.com/show_bug.cgi?id = 2135354))中所详述的,如果桶中的对象数量显著下降,DBR 可以触发“缩小”重分片操作。它将把许多稀疏分片中的条目迁移到新的、更小、更密集堆叠的索引对象集中。
尽管 DBR 是一个强大的自动化功能,但对于从一开始就知道桶将非常庞大的场景,标准的最佳实践仍然是在创建时预分片桶。通过设置适当的初始分片数量,您可以完全避免第一次动态重分片事件,从而确保从写入第一个对象开始就获得最佳性能。
未来有序:有序分片预览
目前,RGW 的哈希分片针对写入分布进行了优化,但它在按字母顺序列表对象时面临挑战。为了满足分页列表请求,RGW 必须执行“分散-收集”操作,查询所有分片并对合并结果进行排序。对于具有大量分片的桶来说,这可能会成为瓶颈。
为了解决这个问题,一项名为有序分片(或有序桶列表)的重要新功能正在开发中。这一即将到来的演变将改变分片逻辑,将对象根据其字典序名称而非哈希值放置到分片中。
这一变化的影响将是变革性的。列出对象的请求将不再查询所有分片,而是直接定向到包含请求的字母范围的特定分片。这将使分页列表操作显着更快、更高效,特别是对于严重依赖浏览或迭代对象键的工作负载。
通过将动态桶重分片的自动化扩展与有序分片的列表效率相结合,Ceph RGW 正在明确地走向在单个桶内提供几乎无限且高性能的可伸缩性的道路,以满足未来最苛刻的数据湖和 AI/ML 用例。
结论:可伸缩性的引擎
到目前为止,我们已经探索了客户端请求的高性能路径,从 Beast 前端的初始连接,到专门的 RADOS 存储池,再深入到桶索引的复杂机制。您现在了解了 OMAP 如何构成对象列表的骨干,以及动态桶重分片如何充当可伸缩性的引擎,允许单个桶增长到数十亿个对象,同时保持性能。我们已经揭示了以大规模处理对象发现和列表的核心机制。
然而,我们目前的深度解析主要集中在索引,即数据的指针。那么数据本身呢?以及定义用户、账户和管理整个系统的关键控制平面元数据呢?
云和安全管理服务商


