
-
Ceph 对象存储分层功能增强:第二部分
简介和功能概述
在本系列的第一部分中,我们探讨了 Ceph 对象存储的基础知识及其基于策略的云/磁带归档功能,该功能能够将数据无缝迁移到远程 S3 兼容的存储类别。这一功能对于将数据存储到经济高效的存储层级(如云存储或基于磁带的系统)至关重要。然而,以往这一过程是单向的。一旦对象被迁移,检索它们需要直接访问云提供商的 S3 存储。这一限制带来了操作上的挑战,尤其是在访问归档或冷存储数据时。
为了弥补这些不足,我们在 Ceph 对象存储生态系统中引入了基于策略的数据检索功能。这一增强功能使管理员和运维团队能够将迁移到云或磁带层级的对象直接检索回 Ceph 集群,从而满足操作效率和数据可访问性的需求。
为什么这很重要?
基于策略的数据检索功能显著提升了 Ceph 中云迁移对象的可用性。无论数据是存储在经济的磁带归档中,还是高延迟/低成本的云层级中,这一功能都确保用户能够无缝访问和管理其对象,而无需依赖外部提供商的 S3 端点。这一能力简化了工作流程,并增强了与操作策略和数据生命周期要求的合规性。
基于策略的数据检索
这一新功能提供了两种方法来检索迁移到远程云/磁带 S3 的对象:
- S3 RestoreObject API 实现:类似于 AWS S3 RestoreObject API,此功能允许用户使用 S3 RestoreObject API 手动检索对象。对象恢复操作可以是永久的或临时的,具体取决于 RestoreObject API 调用中指定的保留期限。
- 直接读取模式(Read-Through Mode):通过引入可配置的
--allow-read-through功能,Ceph 可以处理对云层级存储类别中迁移对象的读取请求。在收到 GET 请求时,系统会异步从云层级检索对象,将其存储在本地,并将数据提供给用户。这消除了之前对云迁移对象遇到的InvalidObjectState错误。
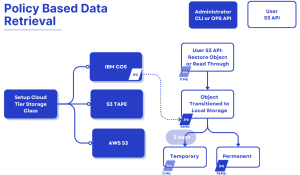
S3 RestoreObject 临时恢复
恢复的数据被视为临时数据,仅在恢复请求中指定的时间段内存在于 Ceph 集群中。一旦指定期限到期,恢复的数据将被删除,对象将恢复为存根(stub),同时保留元数据和云迁移配置。
跳过生命周期迁移规则
在临时恢复期间,对象不受生命周期规则的影响,这些规则可能会将其迁移到其他层级或删除。这确保了在到期日期之前可以无中断地访问数据。
恢复数据的默认存储类别
默认情况下,恢复的对象会写入 Ceph 集群中的
STANDARD存储类别。然而,对于临时对象,x-amz-storage-class标头仍会返回原始的云层级存储类别。这与 AWS Glacier 的语义一致,即恢复对象的存储类别保持不变。S3 RestoreObject API 操作示例
我们使用名为
databucket的存储桶将一个名为2gb的对象上传到本地 Ceph 集群。在本系列博客的第一部分中,我们为databucket配置了一个生命周期策略,该策略会在 30 天后将数据分层/归档到 IBM COS。我们设置了一个名为tiering的 AWS CLI 客户端配置文件,用于与 Ceph 对象网关的 S3 API 端点进行交互。aws --profile tiering --endpoint https://s3.cephlabs.com s3 cp 2gb s3://databucket upload: ./2gb to s3://databucket/2gb我们可以检查本地 Ceph 集群中STANDARD存储类中上传对象的大小:
aaws --profile tiering --endpoint https://s3.cephlabs.com s3api head-object --bucket databucket --key 2gb { "AcceptRanges": "bytes", "LastModified": "2024-11-26T21:31:05+00:00", "ContentLength": 2000000000, "ETag": "\"b459c232bfa8e920971972d508d82443-60\"", "ContentType": "binary/octet-stream", "Metadata": {}, "PartsCount": 60 }30 天后,生命周期转换开始,对象将转换到云层。首先,作为管理员,我们使用radosgw-admin命令检查生命周期 (LC) 处理是否已完成,然后作为用户,我们使用 S3 HeadObject API 调用来查询对象的状态:
# radosgw-admin lc list| jq .[1] { "bucket": ":databucket:fcabdf4a-86f2-452f-a13f-e0902685c655.310403.1", "shard": "lc.23", "started": "Tue, 26 Nov 2024 21:32:15 GMT", "status": "COMPLETE" } # aws --profile tiering --endpoint https://s3.cephlabs.com s3api head-object --bucket databucket --key 2gb { "AcceptRanges": "bytes", "LastModified": "2024-11-26T21:32:48+00:00", "ContentLength": 0, "ETag": "\"b459c232bfa8e920971972d508d82443-60\"", "ContentType": "binary/octet-stream", "Metadata": {}, "StorageClass": "ibm-cos" }作为管理员,我们可以使用radosgw-admin bucket stats命令来检查已使用的空间。我们可以看到rgw.main是空的,我们的rgw.cloudtiered位置是唯一存储数据的位置。
# radosgw-admin bucket stats --bucket databucket | jq .usage { "rgw.main": { "size": 0, "size_actual": 0, "size_utilized": 0, "size_kb": 0, "size_kb_actual": 0, "size_kb_utilized": 0, "num_objects": 0 }, "rgw.multimeta": { "size": 0, "size_actual": 0, "size_utilized": 0, "size_kb": 0, "size_kb_actual": 0, "size_kb_utilized": 0, "num_objects": 0 }, "rgw.cloudtiered": { "size": 1604857600, "size_actual": 1604861952, "size_utilized": 1604857600, "size_kb": 1567244, "size_kb_actual": 1567248, "size_kb_utilized": 1567244, "num_objects": 3 } }现在该对象已转换到我们的 IBM COS Cloud 层,让我们使用 S3 RestoreObject API 调用将其恢复到我们的 Ceph 集群。在此示例中,我们将请求临时恢复并将过期时间设置为三天:
# aws --profile tiering --endpoint https://s3.cephlabs.com s3api restore-object --bucket databucket --key 2gb --restore-request Days=3如果我们尝试获取仍在恢复的对象,我们会收到如下错误消息:
# aws --profile tiering --endpoint https://s3.cephlabs.com s3api get-object --bucket databucket --key 2gb /tmp/2gb An error occurred (RequestTimeout) when calling the GetObject operation (reached max retries: 2): restore is still in progress使用 S3 API,我们可以发出 HeadObject 调用并检查 Restore 属性的状态。在此示例中,我们可以看到从 IBM COS 云端点到 Ceph 的恢复已完成,因为 ongoing-request 设置为 false。由于我们在 RestoreObject 调用中使用了 –restore-request days=30,因此对象有一个到期日期。从输出中还可以检查其他信息:本地 Ceph 集群中对象占用的大小为 2GB,恢复后符合预期。此外,存储类别为 ibm-cos。如前所述,对于临时迁移的对象,即使使用 Ceph RGW 的 STANDARD 存储类别,我们仍会保留 ibm-cos 存储类别。现在对象已恢复,我们可以从客户端发出 S3 GET API 调用来访问该对象。
# aws --profile tiering --endpoint https://s3.cephlabs.com s3api head-object --bucket databucket --key 2gb { "AcceptRanges": "bytes", "Restore": "ongoing-request=\"false\", expiry-date=\"Thu, 28 Nov 2024 08:46:36 GMT\"", "LastModified": "2024-11-27T08:36:39+00:00", "ContentLength": 2000000000, "ETag": "\"\"0c4b59490637f76144bb9179d1f1db16-382\"\"", "ContentType": "binary/octet-stream", "Metadata": {}, "StorageClass": "ibm-cos" } # aws --profile tiering --endpoint https://s3.cephlabs.com s3api get-object --bucket databucket --key 2gb /tmp/2gbS3 RestoreObject 永久恢复
在永久恢复中,恢复的数据将无限期保留在 Ceph 集群中,使其可以作为常规对象访问。与临时恢复不同,永久恢复不定义到期时间,对象在检索后不会恢复为存根。这适用于需要长期访问对象而无需额外重新恢复步骤的场景。
重新应用生命周期迁移规则
一旦永久恢复,对象将被视为 Ceph 集群中的常规对象。所有生命周期规则(例如迁移到云存储或过期策略)将重新应用,恢复的对象将完全集成到存储桶的数据生命周期工作流中。
恢复数据的默认存储类别
默认情况下,永久恢复的对象会写入 Ceph 集群中的
STANDARD存储类别。与临时恢复不同,对象的x-amz-storage-class标头将反映STANDARD存储类别,表明其在集群中的永久驻留状态。S3 RestoreObject API 永久恢复操作示例
通过不为
--restore-request参数提供天数来永久恢复对象:# aws --profile tiering --endpoint https://s3.cephlabs.com s3api restore-object --bucket databucket --key hosts2 --restore-request {}验证恢复的对象:它是STANDARD存储类的一部分。
# aws --profile tiering --endpoint https://s3.cephlabs.com s3api head-object --bucket databucket --key hosts2 { "AcceptRanges": "bytes", "LastModified": "2024-11-27T08:28:55+00:00", "ContentLength": 304, "ETag": "\"01a72b8a9d073d6bcae565bd523a76c5\"", "ContentType": "binary/octet-stream", "Metadata": {}, "StorageClass": "STANDARD" }对象直读(/GET)模式
通过 Read-Through Restore 机制访问的对象会暂时恢复到 Ceph 集群中。当对云转换对象发出
GET请求时,系统会从云层异步检索该对象。它使其在read_through_restore_days值定义的指定持续时间内可用。过期后,恢复的数据将被删除,对象将恢复到其存根状态,保留元数据和转换配置。对象直读 (/GET) 模式测试
在启用直读模式之前,如果我们尝试访问本地 Ceph 集群中已通过基于策略的归档转换到远程 S3 端点的存根对象,我们将收到以下错误消息:
# aws --profile tiering --endpoint https://s3.cephlabs.com s3api get-object --bucket databucket --key 2gb6 /tmp/2gb6 An error occurred (InvalidObjectState) when calling the GetObject operation: Read through is not enabled for this config因此,我们首先启用直读模式。作为 Ceph 管理员,我们需要修改当前的ibm-cos云层存储类并添加两个新的层配置参数: –tier-config=allow_read_through=true,read_through_restore_days=3 :
# radosgw-admin zonegroup placement modify --rgw-zonegroup default \ --placement-id default-placement --storage-class ibm-cos \ --tier-config=allow_read_through=true,read_through_restore_days=3如果之前未执行任何多站点配置,则会创建默认区域和区域组,并且对区域/区域组的更改只有在 Ceph 对象网关(RGW 守护进程)重新启动后才会生效。如果已为多站点创建了领域,则区域/区域组更改将在提交更改后生效 radosgw-admin period update –commit 。在我们的例子中,重新启动 RGW 守护进程以应用更改就足够了:
# ceph orch restart rgw.default Scheduled to restart rgw.default.ceph02.fvqogr on host 'ceph02' Scheduled to restart rgw.default.ceph03.ypphif on host 'ceph03' Scheduled to restart rgw.default.ceph04.qinihj on host 'ceph04' Scheduled to restart rgw.default.ceph06.rktjon on host 'ceph06'一旦启用直读模式,并且当对云层中的对象发出GET请求时重新声明 RGW 服务,该对象将自动恢复到 Ceph 集群并提供给用户。
# aws --profile tiering --endpoint https://s3.cephlabs.com s3api get-object --bucket databucket --key 2gb6 /tmp/2gb6 { "AcceptRanges": "bytes", "Restore": "ongoing-request=\"false\", expiry-date=\"Thu, 28 Nov 2024 08:46:36 GMT\"", "LastModified": "2024-11-27T08:36:39+00:00", "ContentLength": 2000000000, "ETag": "\"\"0c4b59490637f76144bb9179d1f1db16-382\"\"", "ContentType": "binary/octet-stream", "Metadata": {}, "StorageClass": "ibm-cos" }未来工作
Ceph 社区正在通过以下即将推出的增强功能改进基于策略的数据检索特性:
- 磁带/DiamondBack 支持:使用 RestoreObject API 从使用 Glacier API 的 S3 端点获取对象,而不是通过 GET 请求。
- 增强监控的管理命令:包括恢复状态、列出已恢复/进行中的对象,以及为失败操作重新触发恢复。
- 压缩和加密支持:有效恢复压缩或加密的对象。
结 论
Ceph 存储的基于策略的数据检索功能是一项重要的补充,增强了当前对象存储分层的能力。
如有相关问题,请在文章后面给小编留言,小编安排作者第一时间和您联系,为您答疑解惑。
原文: https://ceph.io/en/news/blog/2025/rgw-tiering-enhancements-part2/
云和安全管理服务商


