
-
Kubernetes 中的 Java 应用的内存调优

前言 在 Kubernetes 环境中运行 Java 应用程序虽然很常见,但往往也充满各种问题,特别是在管理内存资源时。在本文中,我们将讨论配置应用程序以优化 Kubernetes 环境中的内存使用并避免内存不足问题的一些最佳实践。 OpenJDK 17 中的内存空间 OpenJDK 17 包含 Java 虚拟机 (JVM) 使用的多个内存空间来管理 Java 应用程序的内存。了解这些不同的内存空间可以帮助开发人员针对 Kubernetes 环境优化其 Java 应用程序。 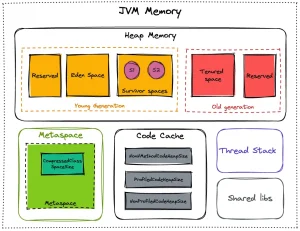
Heap Memory-堆内存 堆内存会在Java运行时分配给对象(Object)或者JRE类。每当我们创建一个对象的时候,在堆内存中就会分配一块储存空间给这个对象。Java的垃圾回收机制就是运行在堆内存上的,用以释放那些没有任何引用指向自身的对象(不可达的对象。注意Java的垃圾回收也会处理几个相互引用但没有任何外部引用的对象)。任何在堆内存中分配的对象都有全局访问权限,可以从应用的任何地方被引用。 堆内存是存储Java应用程序创建的对象的地方。它是Java应用程序最重要的内存空间。在 OpenJDK 17 中,默认堆大小是根据可用物理内存计算的,并设置为可用内存的 1/4。 Young Generation-年轻代 对象被创建时,内存的分配首先发生在年轻代(大对象可以直接被创建在年老代),大部分的对象在创建后很快就不再使用,因此很快变得不可达,于是被年轻代的GC机制清理掉(IBM的研究表明,98%的对象都是很快消亡的),这个GC机制被称为Minor GC或叫Young GC。注意,Minor GC并不代表年轻代内存不足,它事实上只表示在Eden区上的GC。 年轻代上的内存分配是这样的,年轻代可以分为3个区域:Eden区(伊甸园,亚当和夏娃偷吃禁果生娃娃的地方,用来表示内存首次分配的区域,再贴切不过)和两个存活区(Survivor 0 、Survivor 1)。 Old Generation-老一辈 对象如果在年轻代存活了足够长的时间而没有被清理掉(即在几次Young GC后存活了下来),则会被复制到年老代,年老代的空间一般比年轻代大,能存放更多的对象,在年老代上发生的GC次数也比年轻代少。当年老代内存不足时,将执行Major GC,也叫 Full GC。 可以使用-XX:+UseAdaptiveSizePolicy开关来控制是否采用动态控制策略,如果动态控制,则动态调整Java堆中各个区域的大小以及进入老年代的年龄。 如果对象比较大(比如长字符串或大数组),Young空间不足,则大对象会直接分配到老年代上(大对象可能触发提前GC,应少用,更应避免使用短命的大对象)。用-XX:PretenureSizeThreshold来控制直接升入老年代的对象大小,大于这个值的对象会直接分配在老年代上。 可能存在年老代对象引用新生代对象的情况,如果需要执行Young GC,则可能需要查询整个老年代以确定是否可以清理回收,这显然是低效的。解决的方法是,年老代中维护一个512 byte的块——”card table“,所有老年代对象引用新生代对象的记录都记录在这里。Young GC时,只要查这里即可,不用再去查全部老年代,因此性能大大提高。 Metaspace-元空间 非堆空间被 JVM 用于存储元数据和类定义。在旧版本的 Java 中,它也称为永久代 (PermGen)。在 OpenJDK 17 中,PermGen 空间已被新的 Metaspace 取代,其设计更加高效和灵活。 Code Cache-代码缓存 简而言之,JVM Code Cache (代码缓存)是JVM存储编译成本机代码的字节码的区域。我们将可执行本机代码的每个块称为 nmethod。nmethod可能是一个完整的或内联的Java方法。即时(JIT)编译器是代码缓存区的最大消费者。这就是为什么一些开发人员将此内存称为JIT代码缓存。 Thread Stack Space-线程堆栈空间 Java程序中,每个线程都有自己的Stack Space(堆栈)。这个Stack Space不是来自Heap的分配。所以Stack Space的大小不会受到-Xmx和-Xms的影响,这2个JVM参数仅仅是影响Heap的大小。 Stack Space用来做方法的递归调用时压入Stack Frame(栈帧)。所以当递归调用太深的时候,就有可能耗尽Stack Space,爆出StackOverflow的错误。 -Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆 栈大小为1M,以前每个线程堆栈大小为256K。根据应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一 个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。 线程栈的大小是个双刃剑,如果设置过小,可能会出现栈溢出,特别是在该线程内有递归、大的循环时出现溢出的可能性更大,如果该值设置过大,就有影响到创建栈的数量,如果是多线程的应用,就会出现内存溢出的错误。 Shared libs-共享库 Java JVM 中的共享库空间(也称为共享类数据空间)是用于存储共享类元数据和其他数据结构的内存空间。该内存空间在多个 Java 进程之间共享。这允许在同一台机器上运行的各种 Java 应用程序共享类元数据和其他数据结构的相同副本。 共享库空间的目的是通过避免同一类元数据的重复副本来减少内存使用并提高性能。当多个 Java 进程使用相同的类元数据时,它们可以共享该元数据的相同副本,从而减少内存使用并缩短应用程序的启动时间。 为什么要微调JVM的内存设置? JVM 的默认行为会给 Kubernetes 带来很多麻烦。正如我们之前看到的,堆默认设置为可用内存的 1/4。由于 JVM 将考虑 pod 可用的最大内存(有限制),因此堆的大小可能会比我们想要的大。此外,其他默认值将应用于其他空间,例如代码缓存或元空间。 如果从 JVM 的角度来看最大可用内存,它将大于提供给 pod 的最大可用内存。这将导致应用程序出现许多内存不足的情况(在 Kubernetes 部分)。 避免Java应用程序在Kubernetes上出现OOM 大多数时候,都是为了微调 JVM。由于我们看到 JVM 涉及不同的内存空间,因此我们必须为每个空间设置特定的大小。这将帮助我们更精确地计算 pod 的内存限制。 以下是显示每个内存空间可用选项的架构: 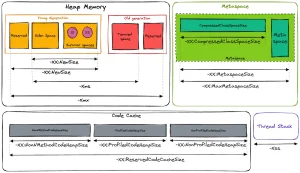
基本公式是: Heap + Metaspace + Code Cache意思是 : -XmX + -XX:MaxMetaspaceSize + -XX:ReservedCodeCacheSize由于线程的数量取决于应用程序的上下文,因此建议为此部分添加一些“缓冲”内存。默认情况下,线程堆栈最大设置为 1MB。 如果想处理来自 JVM 的堆转储,则需要添加堆的大小作为第二次可用的“额外”内存。 最后,设置 pod 限制的公式为: (-XmX * 2) + -XX:MaxMetaspaceSize + -XX:ReservedCodeCacheSize + SomeBuffer缓冲区部分取决于上下文,128 MB 应该可以开始。 Helm模板配置 既然有了公式,我们就可以使用一些 Helm 模板自动计算 pod 的请求和限制。为开发人员提供一个简单的选项来设置不同的参数,而无需担心 Pods 设置,这也是一个好的方式。 以下是默认值的示例: jvm:garbageCollector: -XX:+UseG1GC# values in Mimemory:heap: 128metaspace: 256compressedClassSpaceSize: 64nonMethodCodeHeapSize: 5profiledCodeHeapSize: 48nonProfiledCodeHeapSize: 48buffer: 128使用 Helper 来设置 JAVA_TOOL_OPTIONS : {{/*JVM customisation*/}}{{- define "chart.javaToolOptions" -}}-Xms{{.Values.jvm.memory.heap}}m -Xmx{{.Values.jvm.memory.heap}}m -XX:MetaspaceSize={{.Values.jvm.memory.metaspace}}m -XX:MaxMetaspaceSize={{.Values.jvm.memory.metaspace}}m -XX:CompressedClassSpaceSize={{.Values.jvm.memory.compressedClassSpaceSize}}m -XX:+TieredCompilation -XX:+SegmentedCodeCache -XX:NonNMethodCodeHeapSize={{.Values.jvm.memory.nonMethodCodeHeapSize}}m -XX:ProfiledCodeHeapSize={{.Values.jvm.memory.profiledCodeHeapSize}}m -XX:NonProfiledCodeHeapSize={{.Values.jvm.memory.nonProfiledCodeHeapSize}}m -XX:ReservedCodeCacheSize={{ add .Values.jvm.memory.nonMethodCodeHeapSize .Values.jvm.memory.profiledCodeHeapSize .Values.jvm.memory.nonProfiledCodeHeapSize}}m{{- end -}}在deployment.yaml文件中使用: - name: {{ include "chart.name" . }}image: "{{ .Values.container.image.repository }}:{{ .Values.container.image.tag }}"env:- name: JAVA_TOOL_OPTIONSvalue: {{ include "chart.javaToolOptions" . }}根据提供的参数自动配置内存请求和限制: resources:limits:memory: {{ add .Values.jvm.memory.heap .Values.jvm.memory.heap .Values.jvm.memory.metaspace .Values.jvm.memory.nonMethodCodeHeapSize .Values.jvm.memory.profiledCodeHeapSize .Values.jvm.memory.nonProfiledCodeHeapSize .Values.jvm.memory.buffer | printf "%dMi"}}cpu: {{ .Values.container.resources.limits.cpu }}requests:memory: {{ add .Values.jvm.memory.heap .Values.jvm.memory.metaspace .Values.jvm.memory.nonMethodCodeHeapSize .Values.jvm.memory.profiledCodeHeapSize .Values.jvm.memory.nonProfiledCodeHeapSize | printf "%dMi"}}cpu: {{ .Values.container.resources.requests.cpu }}结论 通过这一设置,我们将 Kubernetes 一侧的 “内存不足”(Out Of Memory)错误数量降至零。现在,JVM 会在自己这边发生 OOM,并生成堆转储,帮助开发人员分析内存。我们会发现是否有一些优化需要推进,或者我们是否需要增加堆大小(或其他内存空间)。 通过微调 JVM 内存配置,我们打破了恶性循环,即每次 OOM 都意味着为 pod 增加内存,以避免未来出现问题。我们能更好地了解每个内存空间,以及如何和何时增加它们。 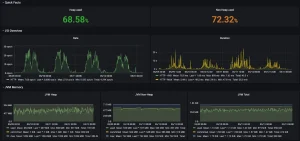
每次调整都需要测试,因此我们建议使用一些工具,例如 Micrometer,来获得有关 JVM 使用情况的一些指标。 而且,最重要的是,我们减少了应用程序的内存需求,并通过减少内存浪费事实上降低了基础设施的成本!
云和安全管理服务商


