
-
Ceph 使用 NVME 是否可以实现 10k 混合 IOPS ?
最近,ceph subreddit上的一位用户提了一个问题:在一个由 6 个节点组成,每个节点有 2 个 4GB FireCuda NVMe 磁盘的集群中,Ceph是否可以为单个客户端提供10K IOPs的组合随机读/写能力。该用户也想知道是否有人对类似的场景进行过测试并希望能够共享一下测试结果。在 Clyso 项目组中,我们一直在积极努力改进 Ceph 代码以实现更高的性能。我们有自己的测试和配置来评估我们对代码的更改。正好,我们当前有可以匹配该用户测试场景的硬件环境。因此,我们决定花些时间来进行测试以及验证。 用户环境配置 用户的环境包含6个节点,每个节点都有2个4TB希捷FireCuda NVMe驱动器和64GB内存。关于CPU或网络,当前没有明确的信息。但两者都对这次测试可能很重要。因此,我们使用如下的 fio 命令来实现这一需求: fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=test --filename=test --bs=4k --iodepth=64 --size=150G --readwrite=randrw --rwmixread=75虽然我们的实验室中没有FireCuda驱动器,但我们确实有节点具有多个4TB三星PM983驱动器和每个128GB内存。 群集配置 Nodes 10 x Dell PowerEdge R6515 CPU 1 x AMD EPYC 7742 64C/128T Memory 128GiB DDR4 Network 1 x 100GbE Mellanox ConnectX-6 NVMe 6 x 4TB Samsung PM983 OS Version CentOS Stream release 8 Ceph Version 1 Pacific v16.2.13 (built from source) Ceph Version 2 Quincy v17.2.6 (built from source) Ceph Version 3 Reef v18.1.0 (built from source) 为了尽可能匹配用户的环境,我们只使用了集群中的 6 个节点,其中 2 个 OSD 在单个 NVMe 驱动器上运行,每个 OSD 用于 Ceph。其余节点用作客户端节点。所有节点都位于同一Juniper QFX5200 交换机上,并通过单个 100GbE QSFP28 连接。 下面将先部署好 Ceph,并使用 CBT 启动 FIO 测试。基于Intel的系统上一项重要的操作系统级别优化是将 TuneD 配置文件设置为“延迟性能”或“网络延迟”。这主要有助于避免与 CPU C/P 状态转换相关的延迟峰值。基于AMD的系统在这方面并没有太大效果,目前还没有确认调优是否限制了C/P状态转换,但是对于这些测试,调优后的配置文件仍然设置为“网络延迟”。 测试设置 用户的环境包含6个节点,每个节点都有2个4TB希捷 CBT 需要修改几个配置,而不使用是默认的配置来部署 Ceph。每个 OSD 分配 8GB 内存(这是合理的,因为用户的节点有 64GB 内存用于 2 个 OSD)。RBD 卷与 Msgr V1 配合一起使用,并且 cephx 被禁用。 FIO 会先用大写入预填充 RBD 卷,然后进行用户的随机读/写测试。某些后台进程(如scrub, deep scrub, pg autoscaling, 以及 pg balancing)已禁用。PG 以及 PGP 设置为4096 (高于通常推荐的)和 3 副本的 RBD 池。用户仅请求单个 FIO 卷和使用单个 150GB 文件的测试。我们按照要求对此进行了测试,但为了让集群处于负载状态,还运行了 16 个独立的 FIO 进程的测试,这些进程写入分布在 4 个客户端节点上的专用 RBD 卷,每个卷都有一个 16GB 的文件。 为了保证与用户的FIO设置一致,必须将 gtod_reduce选项的支持添加到cbt的FIO基准测试工具中。gtod_reduce可以通过显著减少 FIO 必须进行的 getTimeOfDay(2) 调用次数来提高性能, 但它也禁用了某些功能, 例如在测试期间收集操作延迟信息。为了评估影响,我们在启用和禁用的情况下gtod_reduce运行了测试: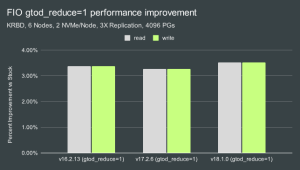
根据结果,我们决定保持 gtod_reduce禁用状态,以便我们也可以观察延迟数据。请注意,启用此 FIO 选项可以提高大约 3-4%性能。除此之外,所有其他选项要么在CBT中可用,要么在FIO中已经默认。CBT YAML 文件的基准测试部分包含单客户端测试的配置内容如下:benchmarks:fio:client_endpoints: 'fiotest'op_size: [4096]iodepth: [64]size: 153600 # data set size per fio instance in KBmode: ['randrw']rwmixread: 75procs_per_endpoint: [1]osd_ra: [4096]log_avg_msec: 100cmd_path: '/usr/local/bin/fio'最终,我们实现了与用户类似的FIO测试案例,但还有一些差异,主要与在测试过程中记录iops/延迟数据有关: fio --ioengine=libaio --direct=1 --bs=4096 --iodepth=64 --rw=randrw --rwmixread=75 --rwmixwrite=25 --size=153600M --numjobs=1 --name=/tmp/cbt/mnt/cbt-rbd-kernel/0/`hostname -f`-0-0 --write_iops_log=/tmp/cbt/00000000/Fio/output.0 --write_bw_log=/tmp/cbt/00000000/Fio/output.0 --write_lat_log=/tmp/cbt/00000000/Fio/output.0 --log_avg_msec=100 --output-format=json,normal > /tmp/cbt/00000000/Fio/output.0单客户端和多客户端IOPS 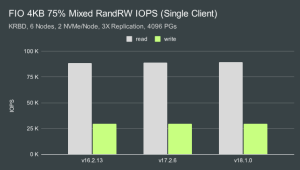
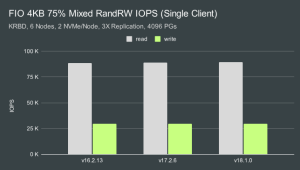
Ceph 不仅能够在这种混合工作负载中实现 10K IOPS,而且在单个客户端测试中速度提高了一个数量级。针对这个小型 12 OSD 集群,我们从单个客户端实现了大约 92K 的随机读取和 31K 的随机写入 IOPS。 另外,我们也运行多客户端测试的原因是为了展示这个小集群在为其他客户端提供服务时有多少空间。在相同的混合工作负载和 16 个客户端下,我们仅用 12 个支持 NVMe 的 OSD 就实现了超过 500K 的随机读取和大约 170K 的随机写入 IOPS。在多客户端测试中,Qunicy 和 Reef 的性能优势分别比 Pacific 高出大约 6% 和 9%。启用 gtod_reduce可将 性能再提高 3-4%。单客户端和多客户端CPU使用率 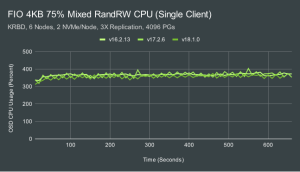
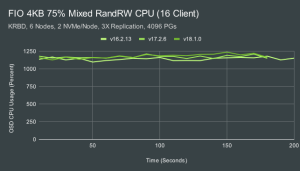
根据以往的测试,我们可以发现一个明显的问题:CPU不足导致NVME的性能无法充分发挥。为了满足单个客户端工作负载,每个 OSD 大约消耗 3-4 个 AMD EPYC 内核。为了满足多客户端工作负载的需求,每个 OSD 消耗大量 11-12 个内核!IE 即使每个节点只有 2 个 OSD,每个节点也需要一个 24 核 EPYC 处理器才能实现这些驱动器的最大性能。更快的驱动器可能需要更大/更快的处理器。什么进程使用了所有这些 CPU? 在以前的文章中,我们得出过如下的结论: Name Count OSD Worker Threads 16 Async Messenger Threads 3 Bluestore KV Sync Thread 1 Bluster “Finisher” Thread 1 在某些情况下,RocksDB 压缩线程也会定期使用 CPU 资源。BlueStore KV Sync 线程很容易成为小型随机写入的瓶颈,尤其是在使用较低性能的 CPU 时。但是,总体 CPU 消耗主要是在 OSD 工作线程和异步信使线程中完成的工作的结果。这是 crc 检查、编码/解码、内存分配等的组合。 单客户端和多客户端cycles/OP 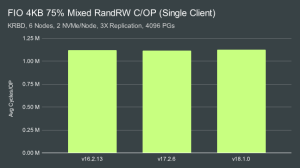
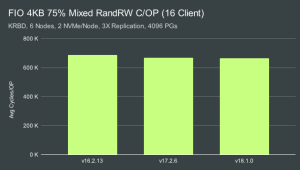
由于cycles/OP 解析代码中的错误,先前的cycles/OP 计数显着增加。这使得 OSD 的效率似乎比实际要低得多。因此,我们计算性能指标的时候,需要使用聚合平均 CPU 消耗和 IOPS 而不是聚合周期和 OPS ,校正后的数值已被验证在预期的 ~14-17% 以内。我们认为,剩余的差异主要是由于cpu速度随时间的变化,以及 collectl 报告的 CPU 消耗方式。 在单客户端和多客户端测试中,性能似乎略有提高。另外,在多客户端测试中,我们发现在高负载下处理数据的效率要高得多,而在单客户端测试中,我们在低负载下处理数据的效率要高得多。
为什么会这样呢?在上一节中,我们讨论了 OSD 中的大部分工作如何由 OSD 工作线程和异步信使线程完成。当 OSD 收到新 IO 时,首先由与相应网络连接关联的异步信使线程处理并移动到用户空间中。然后将其放入给定 OSD 分片的计划程序工作队列中。如果队列之前为空,则与该分片关联的所有线程都会唤醒,并且在分片的工作队列为空之前不会返回睡眠状态。当只有 1 个客户端执行 IO 时,集群上的负载会明显减少,并且每个分片的队列通常会在短时间内为空。线程会不断唤醒并重新进入睡眠状态。当群集负载较重时,队列更有可能有工作要做,因此线程花费更少的睡眠和唤醒时间。相反,他们花更多的时间做实际工作。
单客户端和多客户端平均延迟 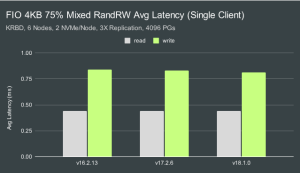
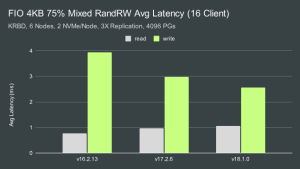
在单客户端测试中,Ceph 能够保持亚毫秒级的平均读取和写入延迟。在多客户端测试中,我们看到了Pacific,Quincy和Reef之间的不同行为。Pacific的读取延迟最低,写入延迟最高,而Reef的读取延迟略有增加,但写入延迟显着降低。Quincy的介于两者之间,但更接近Reef而不是Pacific。 单客户端和多客户端99.9%延迟 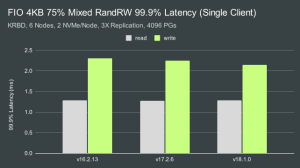
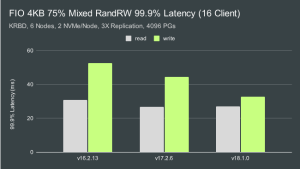
正如预期的那样,99.9% 的延迟略高。我们可以实现不到 1.3 毫秒的读取和大约 2.1-2.3 毫秒的写入,具体取决于版本。多客户端测试中的尾部延迟明显更高,但是在此测试中,Quincy 尤其是 Reef 的写入尾部延迟明显低于 Pacific。 结论 那么我们最后是怎么做的呢?目标是在这个混合读/写 FIO 工作负载中达到 10K IOPS,读取率为 75%,写入率为 25%。我假设这意味着目标是 7500 个读取 IOPS 和 2500 个写入 IOPS。让我们比较一下我们是如何做到的: Single-Client IOPS: 单客户端 IOPS: Release Read Goal Read IOPS Improvement Write Goal Write IOPS Improvement v16.2.13 7500 88540 11.8X 2500 30509 12.2X v17.2.6 7500 89032 11.9X 2500 30644 12.3X v18.1.0 7500 89669 12.0X 2500 30940 12.4X 多客户端 IOPS:
Release Read Goal Read IOPS Improvement Write Goal Write IOPS Improvement v16.2.13 7500 490773 65.4X 2500 163649 65.5X v17.2.6 7500 521475 69.5X 2500 173887 69.6X v18.1.0 7500 535611 71.4X 2500 178601 71.4X 目前,我们完成了所有的测试,同时也满足了要求!另外,如果使用更快的 NVMe 驱动器,结果应该可以进一步改善。 原文: https://ceph.io/en/news/blog/2023/reddit-is-10k-IOPs-achieable-with-NVMes/
云和安全管理服务商


