-
Ceph RocksDB 深度调优
云和安全管理服务专家新钛云服 祝祥翻译
介绍
调优 Ceph 可能是一项艰巨的挑战。在 Ceph、RocksDB 和 Linux 内核之间,实际上有数以千计的选项可以进行调整以提高存储性能和效率。由于涉及的复杂性,比较优的配置通常分散在博客文章或邮件列表中,但是往往都没有说明这些设置的实际作用或您可能想要使用或避免使用它们的原因。这种现象的一个特别常见的例子是调优 Ceph 的 BlueStore RocksDB。
本文档将尝试解释这些选项的实际作用以及您可能想要调整它们或保持它们默认值的原因。同时还将展示基于新版 Ceph 在几种不同配置下的最新性能结果。
历史回溯
在过去的十年中,Ceph 的对象存储守护进程依赖于两个对象存储实现将用户数据写入磁盘。第一个(现已弃用)对象存储是 FileStore。
2016 年,我们开始编写一个名为 BlueStore 的新对象存储。
FileStore 使用现有的文件系统来存储对象数据,而 BlueStore 将对象数据直接存储在块设备上,并将对象元数据存储在 RocksDB 中。
在 BlueStore 开发过程的早期,我们观察到在 RocksDB 中存储元数据的开销会对性能产生巨大影响。
对于小型随机写入尤其如此,其中元数据几乎与对象数据一样大。在 2016 年秋天,我们开始调整 RocksDB,并重点关注对性能和写入放大有很大影响的 3 个设置:
- max_write_buffer_number
- 在 RocksDB 将键值对写入数据库之前,它会将它们写入预写日志,并将它们存储在称为 memtables 的内存缓冲区中。此设置控制可以在内存中累积的最大内存表数。
- 请注意,此设置在整个数据库中不是全局的。相反,它应用于称为”列族“的单独数据库分区。最初编写 BlueStore 时,所有数据都存储在单个列族中。
- 现在我们跨多个列族对数据进行分区,这可能意味着更多的内存缓冲区和数据,除非还应用了全局限制。
- write_buffer_size
- 在将内存表标记为不可变并将数据写入新内存表之前,可以将多少字节数据写入内存表。
- min_write_buffer_number_to_merge
- 在这些内存表被刷新到数据库的级别 0 之前需要填充的最小内存表数。
正如我们在 2016 年(
https://drive.google.com/uc?export=download&id=0B2gTBZrkrnpZRFdiYjFRNmxLblU) 发现的那样,这些设置相互交互的方式对性能和写入放大有巨大影响。为简洁起见,我们将只关注我们运行的一小部分测试用例:大内存表通常比小内存表表现出更低的写入放大。如果使用小型内存表,则必须先累积几个内存表,然后再将它们刷新到数据库。每次刷新聚合大量小型 memtable 会导致性能小幅提升,但与使用大型 memtable 相比,会以额外的写入开销和驱动器磨损为代价。
出于这个原因,我们最终选择使用(最多)4 256MiB 内存表,这些内存表在满时会立即刷新。这些值作为 BlueStore 的 RocksDB 调优的一部分一直保留至今。
当前 Ceph
自从进行了最初的 RocksDB 测试以来,闪存驱动器变得更快了,BlueStore 发生了巨大变化,并且我们了解了更多关于 RocksDB 的使用如何影响性能的信息。
例如,BlueStore 不仅仅将对象元数据写入 RocksDB。它还存储内部 BlueStore 状态。这包括 pglog 更新、extents和磁盘分配等数据。其中一些数据的寿命很短:可能会被写入然后几乎立即删除。
RocksDB 处理这个问题的方式是首先将数据写入内存中的内存表,然后将其附加到磁盘上的预写日志中。当请求删除该数据时,RocksDB 会写入一个列族,指示应删除该数据。
当一次写入和随后的删除同时刷新时,只有最新的更新会保留在数据库中。但是,当这两个操作位于不同的刷新组中时(可能是因为使用了小型内存表),这两个操作可能会持久化到数据库中,从而导致写入放大增加和性能降低。
事实证明,这对我们在最初的 RocksDB 调优中看到更高的性能和更低的写入放大起到了重要作用。
随着时间的推移,其他各种 RocksDB 设置被调整或添加,最终导致 Ceph Pacific 的默认配置如下:
bluestore_rocksdb_options = compression=kNoCompression,max_write_buffer_number=4,min_write_buffer_number_to_merge=1,recycle_log_file_num=4,write_buffer_size=268435456,writable_file_max_buffer_size=0,compaction_readahead_size=2097152,max_background_compactions=2,max_total_wal_size=1073741824附加选项总结如下:
- compression = kNoCompression
- 不压缩数据库。由于担心 CPU 开销和延迟,在 bluestore 的开发过程中很早就被选中。
- *recycle_log_file_num = 4
- 这个选项在 BlueStore 的开发早期就由 Sage Weil 提交给 RocksDB,以提高 WAL 写入的性能。不幸的是,在 2020 年,RocksDB 开发人员发现与他们的许多更强大的恢复模式一起使用并不安全。从RocksDB PR #6351(https://github.com/facebook/rocksdb/pull/6351)开始,RocksDB 本身通常会默认禁用此选项。
- Ceph PR #36579(https://github.com/ceph/ceph/pull/36579)尝试在 RocksDB 中切换到不同的恢复模式以重新启用日志文件的回收,但最终因不安全而被关闭。到目前为止,我们还没有删除这个选项,以防 RocksDB 开发人员找到一种在幕后重新启用它的方法,但现在这似乎不太可能。
- writable_file_max_buffer_size = 0
- 在很旧的 RocksDB 版本中,WritableFileWriter 默认总是分配 64K 的缓冲区。Ceph 不需要或使用此内存,但在将数据写入 BlueFS 时必须复制它。
- RocksDB PR #1628(https://github.com/ceph/ceph/pull/36579)是为 Ceph 实现的,因此可以将初始缓冲区大小设置为小于 64K。
- compaction_readahead_size = 2097152
- 这个选项是在Ceph PR #14932(https://github.com/ceph/ceph/pull/14932)中添加的,以大大提高压缩期间的性能。在设置此选项之前,CompactionIterator 将为每个 Next() 调用发出读取。因为读取是顺序的,所以 2MB 的预读在减少读取开销方面非常有效。
- max_background_compactions = 2
- 这个选项是在Ceph PR #29027(https://github.com/ceph/ceph/pull/29027)中添加的,经过测试表明它不会损害 RBD 或 rados 写入工作负载,同时将繁重的 OMAP 写入工作负载性能提高约 50%。
- 此选项不适用于在级别 0 中发生的压缩,但可能会允许在其他级别中进行并行压缩。RocksDB 现在建议使用max_background_jobs设置来控制压缩和刷新行为。
- max_total_wal_size = 1073741824
- 此选项限制预写日志中数据的总大小。在 RocksDB 列族分片合并后,观察到 RocksDB WAL 消耗的空间显着增加。这几乎可以肯定是因为每个列族最多可以有 4 256MiB 缓冲区,而我们现在有超过 1 个列族。
- 在Ceph PR #35277(https://github.com/ceph/ceph/pull/35277)中添加了此选项,以将整体 WAL 大小限制为 1GB,这是以前使用 4 256MB 缓冲区可以增长到的最大大小。
备用调优
为了尝试提高 NVMe 驱动器上的 OSD 性能,过去几年来 Ceph 邮件列表和博客文章中一直流传着一种常用的 RocksDB 配置:
bluestore_rocksdb_options = compression=kNoCompression,max_write_buffer_number=32,min_write_buffer_number_to_merge=2,recycle_log_file_num=32,compaction_style=kCompactionStyleLevel,write_buffer_size=67108864,target_file_size_base=67108864,max_background_compactions=31,level0_file_num_compaction_trigger=8,level0_slowdown_writes_trigger=32,level0_stop_writes_trigger=64,max_bytes_for_level_base=536870912,compaction_threads=32,max_bytes_for_level_multiplier=8,flusher_threads=8,compaction_readahead_size=2MB除了已经描述的选项之外,备用调整也在调整:
- target_file_size_base
- 这是级别 1 中 sst 文件的基本大小。每个后续级别都会将target_file_size_multiplier的附加乘数应用于此基本文件大小
- level0_file_num_compaction_trigger
- 这控制在触发压缩到级别 1 之前可以在级别 0 中累积的文件数。级别 0 的总大小由以下公式控制: write_buffer_size * min_write_buffer_number_to_merge * level0_file_num_compaction_trigger
- level0_slowdown_writes_trigger
- 在限制写入之前可以在级别 0 中累积的文件数
- level0_stop_writes_trigger
- 在写入停止之前可以在级别 0 中累积的文件数
- max_bytes_for_level_base
- 这是级别 1 的总大小和其他级别的基本大小。根据 RocksDB 调优指南,最好将级别 1 配置为与级别 0 相同的大小。每个后续级别都会将max_bytes_for_level_multiplier的附加乘数应用于此基本级别大小
- max_bytes_for_level_multiplier
- 这是级别 1 之后的后续级别的字节乘数。如果max_bytes_for_level_base = 200MB 且max_bytes_for_level_multiplier = 10,则级别 1 最多可以包含 200MB,级别 2 最多可以包含 2000MB,级别 3 可以包含 20000MB,依此类推
- flusher_threads
- RocksDB 的高优先级池中用于将 memtables 刷新到数据库的线程数。RocksDB 现在建议使用max_background_jobs选项控制压缩和刷新行为
这种交替调整中的一些选项看起来有点可疑。通常 Ceph OSD 最多只使用 6-10 个内核,并且通常配置为使用更少。
这些设置允许 RocksDB 生成多达 32 个低优先级线程用于压缩和 8 个高优先级线程用于刷新。
基于在编写 BlueStore 时执行的初始 RocksDB 测试,具有更频繁刷新的小型 memtable 可能更容易在数据库中产生更高的写入放大。此外,此调整缺少添加到 RocksDB for Ceph 的一些选项以及添加列族分片后引入的全局 WAL 限制。
Ceph Pacific测试 (RBD)
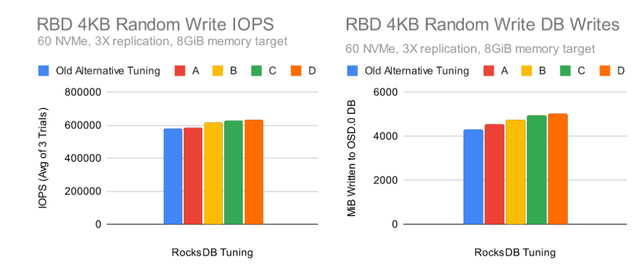
为了测试这种替代的 RocksDB 调优与现有的 BlueStore 选项,在上游 Ceph 社区实验室中使用硬件准备了一个 10 节点的集群,这代表了我们在中等高性能 NVMe 设置中看到的情况:
尽管内存表大小和刷新大小更小(即 1x256MIB 与 2x64MiB 缓冲区),但替代调整显示出更高的性能和略低的写入放大!但是,当我们的初始测试显示小内存表的写入放大明显更高时,为什么会出现这种情况?
要回答这个问题,我们必须单独查看正在更改的选项。让我们看看当我们更改一些 BlueStore 默认调整参数以匹配备用调整使用的内容时会发生什么:
通过仅修改几个选项,我们可以非常接近备用调优的性能。然而,数据库写入开销仍然几乎是原来的两倍。经过几十次额外的测试,最终的难题是
level0_file_num_compaction_trigger和max_bytes_for_level_base。增加这些选项可将数据库中的写入放大量减少到接近库存水平,同时保持性能增益。这可能表明,我们在具有小内存表的数据库中的写入放大的很大一部分是由于删除一直刷新到级别 1,并且增加 L0 和 L1 的大小有助于避免这种行为。
分析 OSD
前面我描述了为什么在某些情况下缩小 memtables 会增加写入放大,但为什么较小的 memtables 会提高性能?首先,重要的是要了解,虽然 BlueStore 有多个工作线程和信使线程,但它只使用一个线程将元数据同步到 RocksDB。当使用闪存存储时,该线程通常会成为限制小随机写入性能的瓶颈。那么为什么较小的内存表会产生性能提升呢?默认情况下,RocksDB 为 memtables 使用 skiplist 数据结构,skiplists 维护存储在其中的元素的顺序。跳过列表越大,维持排序的成本就越高。
sudo unwindpmp -p 916383 -n 10000 -b libdw -v -t 0.1在搜索输出并在 bstore_kv_sync 线程中添加跳过列表开销的实例后,我们得到下表:
请记住,尽管备用调优与默认调优相比性能更高,但这些开销的减少仍在发生。这真的有很大的不同。
新的调优候选
既然我们知道了哪些选项主要负责提高性能,同时还可以降低数据库写入放大,那么让我们尝试根据我们学到的知识来设计一组新的选项。首先,让我们定义一些高级目标:
1、确保 1GB WAL 限制,因为用户已经配置了 WAL 分区。
2、在适用的情况下使用 RocksDB 最佳实践。
使用我们知道对 Ceph 有帮助的选项。
3、停止使用已弃用或无效的选项。
首先,我们将继续将
writable_file_max_buffer_size设置为 0 以减少内存副本。我们还将继续设置 2MB 的压缩预读,因为它在引入时提供了显着的收益。我们将设置适当数量的max_background_jobs并允许 RocksDB 控制细节,而不是设置后台压缩和刷新的数量。一个独立的 RocksDB 实例可能有更高的这个设置,但通常 Ceph OSD 设置为使用 10 个以下的内核,即使对于 NVMe 驱动器也是如此。
允许 8 个文件在级别 0 中累积似乎有助于减少基于早期结果和交替调整的写入放大。由于我们现在让更多数据位于 L0 中,因此我们将遵循RocksDB Tuning Guide (
https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide#level-style-compaction) 的建议,将 L1 的大小调整为与 L0 相似。根据指南,L0 的稳定状态大小可以估计为:write_buffer_size * min_write_buffer_number_to_merge * level0_file_num_compaction_trigger
我们将尝试将刷新(即write_buffer_size *
min_write_buffer_number_to_merge)保持在 128MB,类似于备用调整所做的。使用指南中的公式,基本级别 1 大小应设置为 128MiB * 8 = 1GiB。由于我们显着增加了基本级别的大小,我们还将稍微减少级别字节乘数以进行补偿。最后,我们现在知道,只要我们允许更多文件在 L0 中累积并正确设置 L1 的大小以匹配,我们就可以在没有巨大写入放大损失的情况下使用更小的内存表。虽然我们不知道我们能逃脱多小。
也许我们可以比备用调优中使用的更小?让我们尝试几种组合,使 WAL 的总大小达到 1GB。我们将不再设置recycle_log_file_num但是考虑到该选项不再对我们使用的恢复模式有任何影响。
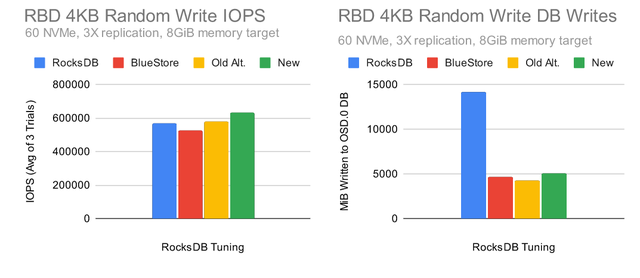
在保持刷新大小不变的情况下使用较小的内存表大小显示出显着的性能提升。写入数据库的数据量也在增长,但这主要是由于测试期间数据写入速度更快。性能一直持续改进到“D”配置,尽管“C”和“D”之间的增益缓慢,表明不太可能有显着的额外改进。
性能比较
让我们看看使用“D”配置的新调优候选者如何在竞争中脱颖而出。这是我们将使用的新调优:
bluestore_rocksdb_options = compression=kNoCompression,max_write_buffer_number=128,min_write_buffer_number_to_merge=16,compaction_style=kCompactionStyleLevel,write_buffer_size=8388608,max_background_jobs=4,level0_file_num_compaction_trigger=8,max_bytes_for_level_base=1073741824,max_bytes_for_level_multiplier=8,compaction_readahead_size=2MB,max_total_wal_size=1073741824,writable_file_max_buffer_size=0与 RocksDB、BlueStore 和旧的备用调优相比:
新配置提供了最高水平的性能,同时保持与其他调整配置大致相同的写入放大减少。
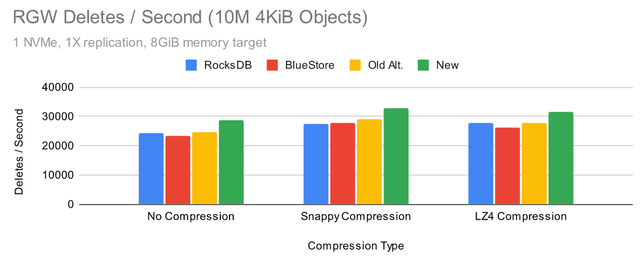
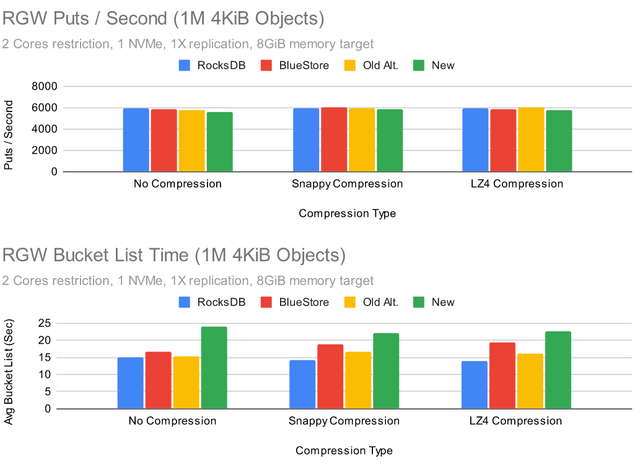
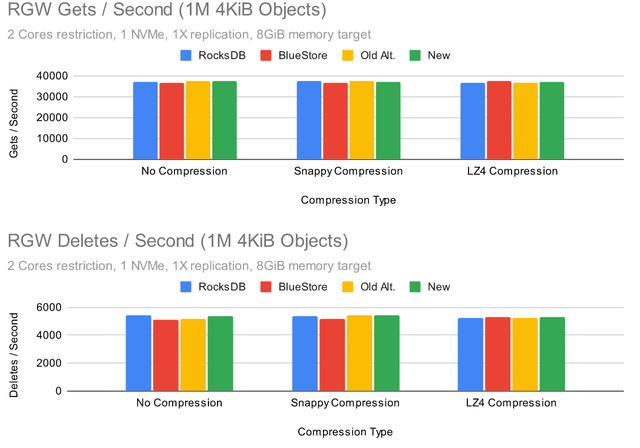
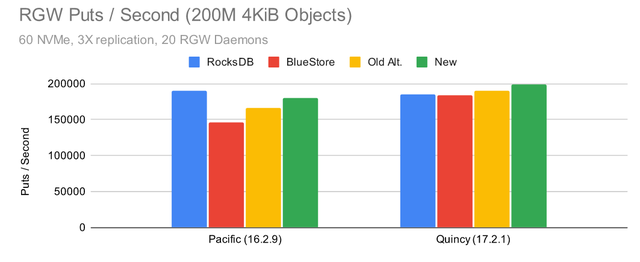
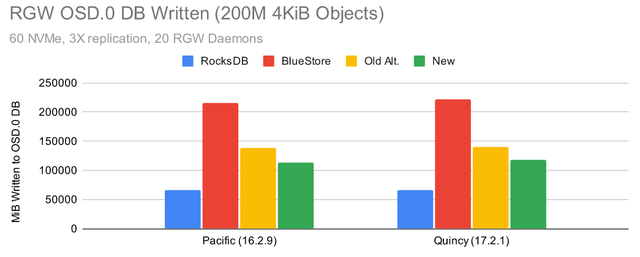
Ceph Pacific 测试 (RGW)
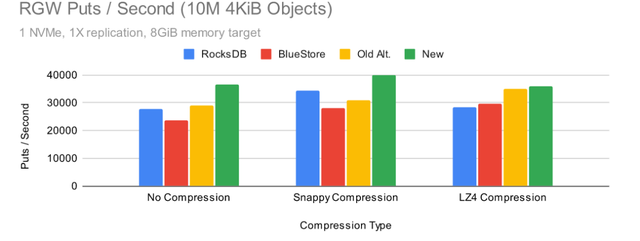
很多用于调整 RocksDB 设置的公开测试结果都集中在 RBD 上,但是 RGW 呢?
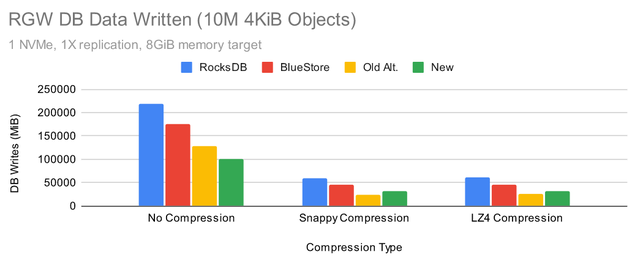
Put 性能相当均衡,但为什么默认的 RocksDB 调优会导致数据库写入流量减少?事实证明,这是由于默认情况下启用了 snappy 压缩,而所有其他配置都关闭了压缩。为了更具体地说明这种效果,让我们看看当我们使用单个 OSD 时会发生什么:
压缩的效果
新的调整显示出最高的写入性能和几乎所有的低写入流量。这里的压缩选项看起来不错,但是我们从测试过这些选项的用户那里得到了反馈,即压缩会影响性能的其他方面,尤其是读取。
打开压缩通常会改善存储桶列表时间。在某些情况下,使用 Snappy 压缩可能会降低性能,但使用 LZ4 压缩显然不会。使用新的调优以及启用 Snappy 或 LZ4 压缩时,删除性能似乎都有所提高。到目前为止,结果看起来还不错,为什么要大惊小怪呢?
限制 CPU 的影响
压缩的另一个问题是它可能会在 CPU 受限的情况下损害性能。为了评估这一点,让我们看一组类似的测试,当我们测试的单个 OSD 被限制为 2 个内核时。
当限制为 2 个内核时,除执行存储桶列表外,所有配置的性能都相当均匀。在这种情况下,所有调整后的配置都显示出不同程度的性能损失,尽管新配置受到的影响最大。结果是可重复的,但是当 OSD 有更多 CPU 可用时,它似乎不会发生。
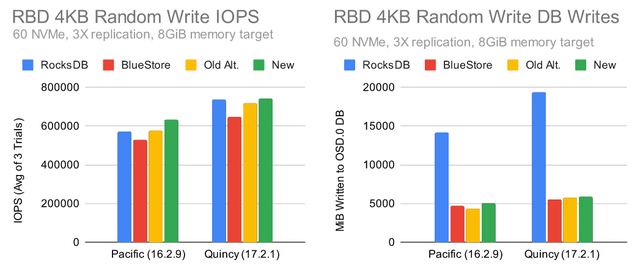
Ceph Quincy 测试
Quincy 是目前最快的 Ceph 版本。除了大量常规改进之外,Red Hat 开发人员 Gabriel Benhanokh 还能够从 RocksDB 中删除 BlueStore 分配信息,以减少写入期间的元数据开销。当 BlueStore 的 KV 同步线程成为瓶颈时,这通常会产生 10-20% 的性能提升。鉴于这些变化,这些替代的 RocksDB 调优在Quincy仍然有意义吗?
Quincy 相对于 Pacific 的写入性能优势在 RBD 和 RGW 测试中都很明显。Quincy 似乎也存在相同的总体调优趋势,较新的调优表现出更好的性能。剩下的唯一问题是是否默认启用压缩。RGW 中的数据库写入放大(以及可能的大小放大)优势是否值得以可能较慢的读取和更高的 CPU 使用率为代价?
结论
调整 Ceph 可能是一项艰巨的挑战。在 Ceph、RocksDB 和 Linux 内核之间,实际上有数以千计的选项可以进行调整以提高性能和效率。在本文中,我们专注于 Ceph 的默认 RocksDB 调优,并将其与其他几个配置进行了比较。
我们研究了这些设置如何影响 NVMe 驱动器上的写入放大和性能,并试图展示不同配置选项之间的交互有多复杂。看来,通过正确的选项组合,可以在不显着增加写入放大的情况下实现更高的性能。在某些情况下,启用压缩可能会减少写入放大,并在某些测试中对性能产生中等影响。在这些测试中,通常性能最高的配置似乎是:
无压缩:
bluestore_rocksdb_options = compression=kNoCompression,max_write_buffer_number=128,min_write_buffer_number_to_merge=16,compaction_style=kCompactionStyleLevel,write_buffer_size=8388608,max_background_jobs=4,level0_file_num_compaction_trigger=8,max_bytes_for_level_base=1073741824,max_bytes_for_level_multiplier=8,compaction_readahead_size=2MB,max_total_wal_size=1073741824,writable_file_max_buffer_size=0LZ4 压缩(较低的 RGW 写入放大器,对存储桶列表的性能影响):
bluestore_rocksdb_options = compression=kLZ4Compression,max_write_buffer_number=128,min_write_buffer_number_to_merge=16,compaction_style=kCompactionStyleLevel,write_buffer_size=8388608,max_background_jobs=4,level0_file_num_compaction_trigger=8,max_bytes_for_level_base=1073741824,max_bytes_for_level_multiplier=8,compaction_readahead_size=2MB,max_total_wal_size=1073741824,writable_file_max_buffer_size=0鉴于这些结果,您是否应该更改默认的 Ceph RocksDB 调优?BlueStore 的默认 RocksDB 调优在大约 5 年的时间里经历了数千小时的 QA 测试。这些非默认配置肯定会更佳,但尚未经过重大测试。在接下来的几个月里,我们将通过 QA 运行这些配置,并可能考虑更改 Ceph 下一版本的默认设置。
后记
写这篇文章的动机之一是检查以前发表的性能文章和博客文章中使用的 RocksDB 调优是否对新版本的 Ceph 产生了影响。也就是说,有三篇文章展示了 Ceph 在 NVMe 驱动器上使用 Alternate RocksDB 调整的性能结果:
不过,除了查看 RocksDB 调优之外,我们还可以从这些文章中了解 Ceph 在 2018/2019 年与我们最近发布的版本的表现。如果我们将这些文章的结果与此处提供的新结果进行比较,我们会得到下表:
我们在这个测试集群中有更多的 NVMe 驱动器,但我们也看到集群范围内的 IOPS 显着提高,尽管使用的是 3X 副本而不是 2X。我发现真正令人兴奋的是,如果在给定 NVMe 驱动器数量和复制因子的情况下标准化每个 NVMe 吞吐量会发生什么:
两篇较早的文章都使用更少、更高密度的服务器。尽管如此,所有设置都有足够的内核,CPU 资源的可用性不太可能成为限制因素。这些收益与我们在内部看到的跨版本的收益相似。
我要指出的最后一点是,在之前的文章中使用了一些我们不建议在实际生产集群中使用的设置。除非您确切知道自己在做什么,否则绝对不应该将 pglog 和tracked dup 条目的数量减少到 10。这样做可以提高基准测试的性能,但可能会对集群恢复产生重大影响。
在某些情况下禁用优先级缓存管理器可能是有益的,但主要是当您已经为 BlueStore 设置了较小的静态缓存大小,并且希望避免在 tcmalloc 中摇摆。调整默认设置可能有好处,但也有危险。请注意,本文的内容在仅作为参考。
原文链接:
https://ceph.io/en/news/blog/2022/rocksdb-tuning-deep-dive/
云和安全管理服务商