-
自建Kafka及运维实战
云和安全管理服务专家 新钛云服刘川川
为什么要自建 Kafka
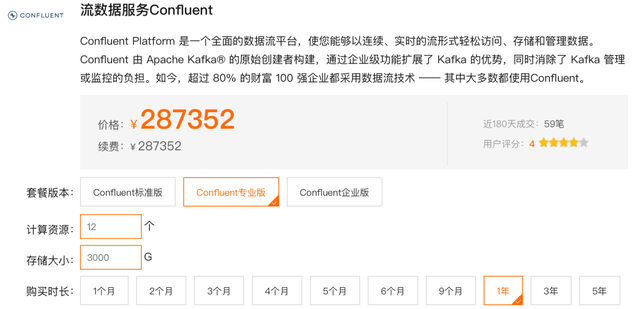
为什么要自建呢?我们先看看商业版的 Kafka 实例的一年费用大概多少。
专业版的一年费用:
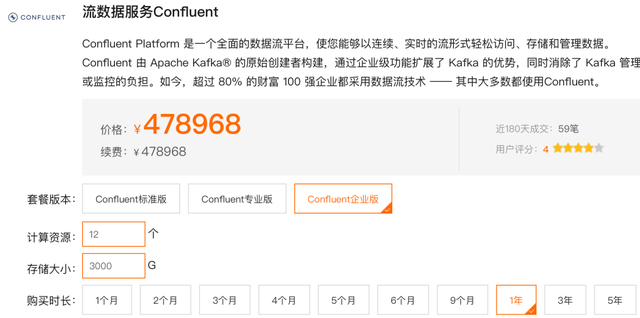
企业版的一年费用:
两者的费用加起来,也就是一年:766,320 元/年。我们用这些钱开一家公司都没有问题,或者用来改善员工福利也未尝不可。我们不愿出那么多的,因此要自建。
Kafka 介绍
Kafka 官方的定义:是一种高吞吐量的分布式发布/订阅消息系统。这样说起来可能不太好理解,我们简单举个例子:现在是个大数据时代,各种商业、社交、搜索、浏览都会产生大量的数据,那么如何快速收集这些数据,如何实时地分析这些数据,是一个必须要解决的问题。
同时,这也形成了一个业务需求模型,即生产者生产(Produce)各种数据,消费者(Consume)消费(分析、处理)这些数据。面对这些需求,如何高效、稳定地完成数据的生产和消费呢?这就需要在生产者与消费者之间,建立一个通信的桥梁,这个桥梁就是消息系统。从微观层面来说,这种业务需求也可理解为不同系统之间如何传递消息。
Kafka 应用场景
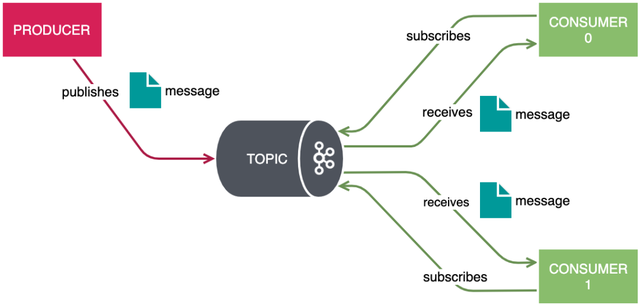
场景1:订阅与发布
这种场景用的应该比较多。
场景2:日志聚合
想必运维小伙伴对上面的拓扑图应该不陌生,有可能我们在公司内部已经做过这样的项目。
场景3:基于事件驱动的 CQRS
CQRS 是命令和查询的职责分离(Command Query Responsibility Segregation)对应的英文名称的首字母缩写。CQRS 中的命令指的是对数据的更新操作,而查询指的是对数据的读取操作,命令和查询的职责分离指的是用不同的模型来分别进行更新和读取操作。
我们通常对数据的操作方式是典型的 CRUD 操作,分别表示对记录的创建(Create)、读取(Read)、更新(Update)和删除(Delete)。在有些时候,还会加上一个列表(List)操作来读取满足条件的多个记录,组成 LCRUD 操作,CRUD 操作使用的是同一个模型。
适合于 CQRS 技术的应用主要有两类:第一类应用的更新模型和查询模型本身就存在很大差异,第二类应用在更新和查询操作时有不同的性能要求。
命令本质上是一种消息。后端实现中通常会使用消息队列或消息中间件来接收命令。
Kafka 架构
Kafka 是一个分布式系统,它有若干核心组件组成。如下:
· Broker 节点:负责处理 I/O 操作及数据持久化。
· ZooKeeper 节点:用来管理 Kafka 控制器的状态、存储集群的元数据信息。
· Producers:客户端程序,用来向 Topic 写入消息。
· Consumers:客户端程序,用来从 Topic 读取消息。
在未来的 Kafka 版本中将不再依赖 Zookeeper**。Kafka 实现了自己的协议 KRaft。**
下图是 Kafka 的组件架构图,描述了组件之间的关系。
消息组成
记录是 Kafka 中最基本的持久性单位。它具有以下属性:
· Key: 记录可以与可选的非唯一键相关联,该键充当一种分类器 – 根据其键对相关记录进行分组。键是完全自由形式的、任何可以表示为字节数组的东西都可以用作记录键。
· Value: 值实际上是记录的信息负载。在业务意义上,该值是记录中最有趣的部分 — 最终描述事件的是记录的值。值是可选的,但很少看到具有 null 值的记录。如果没有值,记录在很大程度上是毫无意义的。所有其他属性在传达值时起着辅助作用。
· Headers: 一组自由格式的键值对,可以选择性地对记录进行批注。Kafka 中的 Header 类似于它们在 HTTP 中的同名标题,它可以认为是 Value 的额外信息补充。
· Partition number: 记录所在的分区的从零开始的索引。记录必须始终只绑定到一个分区;但是,在发布记录时不需要显式指定分区。
· Offset: 一个 64 位有符号整数,用于在其包含的分区内查找记录。记录按顺序存储,偏移量表示记录的逻辑序列号。
· Timestamp: 记录的毫秒级精确时间戳。时间戳可以由创建器显式设置为任意值,也可以由代理在将记录追加到日志时自动分配。
一般情况下,开发人员比较关注的是 Value 这一部分。其实本文的作者也很好奇,我们看一个实际的例子,去一探究竟。代码如下:
# 生产者代码:
(venv392) root@node01:~/kafka# cat kafka-producer-python.py
import json
from kafka import KafkaProducer
conf = {
‘bootstrap_servers’: [“node01:9093″,”node02:9093″,”node03:9093”],
‘topic_name’: ‘python_ssl_topic_name’,
‘ssl_cafile’: ‘/root/mycerts/certificates/CARoot.pem’,
‘ssl_certfile’: ‘/root/mycerts/certificates/certificate.pem’,
‘ssl_keyfile’: ‘/root/mycerts/certificates/key.pem’
}
print(‘start producer’)
producer = KafkaProducer(
bootstrap_servers=conf[‘bootstrap_servers’],
security_protocol=’SSL’,
ssl_check_hostname=False,
ssl_cafile=conf[‘ssl_cafile’],
ssl_certfile=conf[‘ssl_certfile’],
ssl_keyfile=conf[‘ssl_keyfile’])
json_value = {“name”: “tyun tech”, “location”: “zhangjiang”}
key = bytes(“tyun”, encoding=”utf-8″)
headers = [(“Host”, bytes(“www.tyun.cn”, encoding=”utf-8″))]
data = bytes(json.dumps(json_value), encoding=”utf-8″)
producer.send(conf[‘topic_name’], value=data, key=key, headers=headers)
producer.close()
print(‘end producer’)
# 消费者代码:
(venv392) root@node01:~/kafka# cat kafka-consumer-python.py
from kafka import KafkaConsumer
conf = {
‘bootstrap_servers’: [“node01:9093″,”node02:9093″,”node03:9093”],
‘topic_name’: ‘python_ssl_topic_name’,
‘consumer_id’: ‘python_ssl_consumer’,
‘ssl_cafile’: ‘/root/mycerts/certificates/CARoot.pem’,
‘ssl_certfile’: ‘/root/mycerts/certificates/certificate.pem’,
‘ssl_keyfile’: ‘/root/mycerts/certificates/key.pem’
}
print(‘start consumer’)
consumer = KafkaConsumer(conf[‘topic_name’],
bootstrap_servers=conf[‘bootstrap_servers’],
group_id=conf[‘consumer_id’],
security_protocol=’SSL’,
ssl_check_hostname=False,
ssl_cafile=conf[‘ssl_cafile’],
ssl_certfile=conf[‘ssl_certfile’],
ssl_keyfile=conf[‘ssl_keyfile’])
for message in consumer:
print(“{}:{}:{}: key={} value={} headers={} timestamp={}”.format(message.topic,
message.partition,
message.offset,
message.key,
message.value,
message.headers,
message.timestamp))
print(‘end consumer’)代码中使用了 SSL 加密的设置,如果实际情况没有使用 SSL,那么可以把代码中关于 SSL 的配置部分删除即可。
演示效果为:
(venv392) root@node01:~/kafka# python kafka-consumer-python.py
start consumer
python_ssl_topic_name:1:9: key=b’tyun’ value=b'{“name”: “tyun tech”, “location”: “zhangjiang”}’ headers=[(‘Host’, b’www.tyun.cn’)] timestamp=1654139871642
python_ssl_topic_name:1:10: key=b’tyun’ value=b'{“name”: “tyun tech”, “location”: “zhangjiang”}’ headers=[(‘Host’, b’www.tyun.cn’)] timestamp=1654139909527
python_ssl_topic_name:1:11: key=b’tyun’ value=b'{“name”: “tyun tech”, “location”: “zhangjiang”}’ headers=[(‘Host’, b’www.tyun.cn’)] timestamp=1654139911635
python_ssl_topic_name:1:12: key=b’tyun’ value=b'{“name”: “tyun tech”, “location”: “zhangjiang”}’ headers=[(‘Host’, b’www.tyun.cn’)] timestamp=1654139912718
# 我们需要生产者生产数据
(venv392) root@node01:~/kafka# python kafka-producer-python.py
start producer
end producer分区
Kafka 中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区 0 中,要么在分区 1 中。如你所见,Kafka 的分区编号是从 0 开始的,如果 Topic 有 100 个分区,那么它们的分区号就是从 0 到 99。
Kafka 如何持久化数据
Kafka Broker 是如何持久化数据的。总的来说,Kafka 使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机 I/O 操作,改为性能较好的顺序 I/O 写操作,这也是实现 Kafka 高吞吐量特性的一个重要手段。不过如果你不停地向一个日志写入消息,最终也会耗尽所有的磁盘空间,因此 Kafka 必然要定期地删除消息以回收磁盘。怎么删除呢?简单来说就是通过日志段(Log Segment)机制。在 Kafka 底层,一个日志又进一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka 会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka 在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。
Kafka 安装部署
Kafka 安装方式多种多样,我们这里介绍两种方式:
1、单机模式
a.单进程模式
b.Docker Compose 模式
2、集群模式
a. 基于虚拟机的部署方式
b. 基于 Kubernetes 的部署方式
单机模式安装
单进程模式
当我们手头上的机器资源不充足的时候,可以尝试使用单机方式安装。这种方式最简单:
wget -c https://archive.apache.org/dist/kafka/2.6.0/kafka_2.12-2.6.0.tgz
export KAFKA_HOME=opt/kafka_2.12-2.6.0
# 前台启动 Zookeeper
$KAFKA_HOME/bin/zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties
# 后台启动 Zookeeper
$KAFKA_HOME/bin/zookeeper-server-start.sh -daemon $KAFKA_HOME/config/zookeeper.properties
tail -f $KAFKA_HOME/logs/zookeeper.out
# 关闭 Zookeeper
$KAFKA_HOME/bin/zookeeper-server-stop.sh
# 前台启动 Kafka
$KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties
# 后台启动 Kafka
$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
tail -f $KAFKA_HOME/logs/kafkaServer.out
# 关闭 Kafka
$KAFKA_HOME/bin/kafka-server-stop.sh很多人都在使用前台启动方式,然后使用 nohup 放后台执行。为啥不直接使用 **-daemon**选项呢?
Docker Compose 模式安装
我们还可以使用 Docker-Compose 的形式部署 Kafka。下面的配置清单是单个 borker:
version: “3.2”
services:
zookeeper:
image: bitnami/zookeeper:3
ports:
– 2181:2181
environment:
ALLOW_ANONYMOUS_LOGIN: “yes”
kafka:
image: bitnami/kafka:2
ports:
– 9092:9092
environment:
KAFKA_CFG_ZOOKEEPER_CONNECT: zookeeper:2181
ALLOW_PLAINTEXT_LISTENER: “yes”
KAFKA_LISTENERS: >-
INTERNAL://:29092,EXTERNAL://:9092
KAFKA_ADVERTISED_LISTENERS: >-
INTERNAL://kafka:29092,EXTERNAL://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: >-
INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: “INTERNAL”
depends_on:
– zookeeper
kafdrop:
image: obsidiandynamics/kafdrop:latest
ports:
– 9000:9000
environment:
KAFKA_BROKERCONNECT: kafka:29092
depends_on:
– kafka下面的配置清单是多个 borker:
version: “3.2”
services:
zookeeper:
image: bitnami/zookeeper:3
ports:
– 2181:2181
environment:
ALLOW_ANONYMOUS_LOGIN: “yes”
kafka-0:
image: bitnami/kafka:2
ports:
– 9092:9092
environment:
KAFKA_CFG_ZOOKEEPER_CONNECT: zookeeper:2181
ALLOW_PLAINTEXT_LISTENER: “yes”
KAFKA_LISTENERS: >-
INTERNAL://:29092,EXTERNAL://:9092
KAFKA_ADVERTISED_LISTENERS: >-
INTERNAL://kafka-0:29092,EXTERNAL://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: >-
INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: “INTERNAL”
depends_on:
– zookeeper
kafka-1:
image: bitnami/kafka:2
ports:
– 9093:9093
environment:
KAFKA_CFG_ZOOKEEPER_CONNECT: zookeeper:2181
ALLOW_PLAINTEXT_LISTENER: “yes”
KAFKA_LISTENERS: >-
INTERNAL://:29092,EXTERNAL://:9093
KAFKA_ADVERTISED_LISTENERS: >-
INTERNAL://kafka-1:29092,EXTERNAL://localhost:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: >-
INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: “INTERNAL”
depends_on:
– zookeeper
kafka-2:
image: bitnami/kafka:2
ports:
– 9094:9094
environment:
KAFKA_CFG_ZOOKEEPER_CONNECT: zookeeper:2181
ALLOW_PLAINTEXT_LISTENER: “yes”
KAFKA_LISTENERS: >-
INTERNAL://:29092,EXTERNAL://:9094
KAFKA_ADVERTISED_LISTENERS: >-
INTERNAL://kafka-2:29092,EXTERNAL://localhost:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: >-
INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: “INTERNAL”
depends_on:
– zookeeper
kafdrop:
image: obsidiandynamics/kafdrop:latest
ports:
– 9000:9000
environment:
KAFKA_BROKERCONNECT: >-
kafka-0:29092,kafka-1:29092,kafka-2:29092
depends_on:
– kafka-0
– kafka-1
– kafka-2上面的方式都是伪集群模式,可想而知,它们是存在单点故障的。
在生产环境中千万不要使用伪集群模式,这种模式只适合本地测试使用。
接下来介绍高可用模式的集群部署方式。
集群模式安装
环境如下:
(venv392) root@node01:~/kafka# ansible -i hosts 'kafka' -m shell -a "hostname" node01 | CHANGED | rc=0 >> node01.tyun.cn node03 | CHANGED | rc=0 >> node03.tyun.cn node02 | CHANGED | rc=0 >> node02.tyun.cn # 下载所需要的二进制文件 wget -c https://archive.apache.org/dist/kafka/2.6.0/kafka_2.12-2.6.0.tgz wget -c https://archive.apache.org/dist/zookeeper/zookeeper-3.6.1/apache-zookeeper-3.6.1-bin.tar.gz wget -c https://github.com/smartloli/kafka-eagle-bin/archive/v2.1.0.tar.gz这里需要注意:
Kafka 和 ZooKeeper 的版本,默认 Kafka 2.12 版本自带的 ZooKeeper 依赖 jar 包版本为 3.5.7,因此 ZooKeeper 的版本至少在 3.5.7 及以上。
配置ZooKeeper分布式集群
在每个节点上分别操作:
[vagrant@node01 ~]$ cd /opt
[vagrant@node01 opt]$ sudo tar -xf apache-zookeeper-3.6.1-bin.tar.gz
[vagrant@node01 opt]$ sudo ln -sv apache-zookeeper-3.6.1-bin zookeeper修改 zk 配置文件:
[vagrant@node01 conf]$ cp zoo_sample.cfg zoo.cfg [vagrant@node01 conf]$ grep -E -v "^#|^$" zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/data/apps/zookeeper-3.6.1/data clientPort=2181 server.1=node01:2888:3888 server.2=node02:2888:3888 server.3=node03:2888:3888创建数据目录:
[vagrant@node01 conf]$ sudo mkdir -pv /data/apps/zookeeper
除了修改 zoo.cfg 配置文件,集群模式下还要配置一个文件 myid,这个文件 在 dataDir 目录下,这个文件里面就有一个数据就是 id 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是那个 server。
[vagrant@node01 conf]# echo “1” > /data/apps/zookeeper/myid
[vagrant@node02 conf]# echo “2” > /data/apps/zookeeper/myid
[vagrant@node03 conf]# echo “3” > /data/apps/zookeeper/myid启动服务:
[root@node01 conf]# /data/apps/zookeeper-3.6.1/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /data/apps/zookeeper-3.6.1/bin/../conf/zoo.cfg
Starting zookeeper … STARTED
[root@node02 conf]# /data/apps/zookeeper-3.6.1/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /data/apps/zookeeper-3.6.1/bin/../conf/zoo.cfg
Starting zookeeper … STARTED
[root@node03 conf]# /data/apps/zookeeper-3.6.1/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /data/apps/zookeeper-3.6.1/bin/../conf/zoo.cfg
Starting zookeeper … STARTED启动之后检查服务状态:
[root@node01 conf]# /data/apps/zookeeper-3.6.1/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/apps/zookeeper-3.6.1/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
[root@node02 conf]# /data/apps/zookeeper-3.6.1/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/apps/zookeeper-3.6.1/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
[root@node03 conf]# /data/apps/zookeeper-3.6.1/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/apps/zookeeper-3.6.1/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower连接到 zk 集群上看看:
[root@node01 conf]# /data/apps/zookeeper-3.6.1/bin/zkCli.sh -server 127.0.0.1:2181
[zk: 127.0.0.1:2181(CONNECTED) 1] ls /
[zookeeper]
[zk: 127.0.0.1:2181(CONNECTED) 2] ls -R /
/
/zookeeper
/zookeeper/config
/zookeeper/quota配置 Kafka 集群
(venv392) root@node01:~/kafka# cat hosts
[kafka]
node01
node02
node03
[eagle]
node04
(venv392) root@node01:~/kafka# ansible \
-i hosts ‘kafka’ \
-m copy -a “src=kafka_2.12-2.6.0.tgz dest=/data/apps”
# 解压
(venv392) root@node01:~/kafka# ansible \
-i hosts ‘kafka’ \
-m shell -a “tar -xf /data/apps/kafka_2.12-2.6.0.tgz -C /data/apps”
[root@node01 share]# cd /data/apps/
[root@node01 apps]# ln -sv kafka_2.12-2.6.0 kafka
‘kafka’ -> ‘kafka_2.12-2.6.0’
# 创建用户及授权
(venv392) root@node01:~/kafka# ansible -i hosts ‘kafka’ -m shell -a “useradd kafka”
(venv392) root@node01:~/kafka# ansible -i hosts ‘kafka’ -m shell -a “chown -R kafka:kafka /data/apps/kafka*”准备配置 kafka 配置文件:
[root@node01 config]# egrep -v “(^$|^#)” server.properties
broker.id=1
listeners=PLAINTEXT://node01:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/apps/kafka/logs
num.partitions=3
log.retention.hours=60
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=node01:2181,node02:2181,node03:2181
zookeeper.connection.timeout.ms=18000
auto.create.topics.enable=true
delete.topic.enable=true
[root@node02 config]# egrep -v “(^$|^#)” server.properties
broker.id=2
listeners=PLAINTEXT://node02:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/apps/kafka/logs
num.partitions=3
log.retention.hours=60
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=node01:2181,node02:2181,node03:2181
zookeeper.connection.timeout.ms=18000
auto.create.topics.enable=true
delete.topic.enable=true
[root@node03 config]# egrep -v “(^$|^#)” server.properties
broker.id=3
listeners=PLAINTEXT://node03:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/apps/kafka/logs
num.partitions=3
log.retention.hours=60
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=node01:2181,node02:2181,node03:2181
zookeeper.connection.timeout.ms=18000
auto.create.topics.enable=true
delete.topic.enable=true下表为每个配置项的具体含义:
· log.dirs:这是非常重要的参数,指定了 Broker 需要使用的若干个文件目录路径。要知道这个参数是没有默认值的,这说明什么?
这说明它必须由你亲自指定。在线上生产环境中一定要为log.dirs配置多个路径,具体格式是一个 CSV 格式,也就是用逗号分隔的多个路径,比如/home/kafka1,/home/kafka2,/home/kafka3这样。如果有条件的话你最好保证这些目录挂载到不同的物理磁盘上。
· log.retention.hours=168 # 168 小时,默认为一周
· log.segment.bytes=1073741824 # 默认为 1GB
· log.retention.check.interval.ms=300000 # 默认 5 分钟
如果设置了 log.retention.minutes,将会覆盖 log.retention.hours;如果设置了 log.retention.ms,将会覆盖 log.retention.minutes。
时间单位越小的优先级越高。
Kakfa 配置文件修改完成后,接着打包 Kakfa 安装程序,将程序复制到其他两个节点,然后进行解压即可。
注意,在其他两个节点上,broker.id 须要修改,Kafka 集群中 broker.id 不能有相同的。
三个节点的 Kafka 配置完成后,就可以启动了,但在启动 Kafka 集群前,需要确保 ZooKeeper 集群已经正常启动。接着,依次在 Kafka 各个节点上执行如下命令即可:
export KAFKA_HOME=/data/apps/kafka
[root@node01 kafka]# $KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@node01 kafka]# jps
3940 QuorumPeerMain
5045 Jps
4653 Kafka
[root@node02 kafka]# $KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@node02 kafka]# jps
3857 Kafka
4246 Jps
3719 QuorumPeerMain
[root@node03 kafka]# $KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@node03 kafka]# jps
3296 Kafka
3664 Jps
3156 QuorumPeerMain关闭 Kafka 及前后台启动 Kafka:
# 关闭 Kafka
$KAFKA_HOME/bin/kafka-server-stop.sh
# 前台启动 Kafka
$KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties
# 后台启动 Kafka
$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties很多人都在使用前台启动方式,然后使用 nohup 放后台执行。为啥不直接使用 **-daemon**选项呢?
至此,我们已经完成了 Zookeeper 集群及 Kafka 集群的搭建工作。接下来介绍如何使用 Kafka。
Kafka 基本操作
接下来,我们介绍 Kafka 常见的命令行操作。本节需要实际的动手操作。
创建 Topic
root@node01:~# $KAFKA_HOME/bin/kafka-topics.sh \
–bootstrap-server node01:9092,node02:9092,node03:9092 \
–create –partitions 3 –replication-factor 1 \
–topic getting-started–bootstrap-server 选项支持一个或多个 brokers 节点,使用逗号进行分割即可。创建完成,会有如下输出:
Created topic getting-started.
上面的演示命令是有问题的。说它有问题,不是因为它不能执行,而是 –replication-factor 选项设置的不合理。我们 Kafka 集群有三个节点,而我们的副本数却设置了 1。这样是不是会存在丢失数据的风险呢?答案是肯定的。
这个值要设置多少才合理呢?
如果设置的副本数大于集群的节点数量,又会怎样呢?
(venv392) root@node01:~/kafka# $KAFKA_HOME/bin/kafka-topics.sh \
–bootstrap-server node01:9092,node02:9092,node03:9092 \
–create \
–partitions 3 \
–replication-factor 4 \
–topic an-error-topic将会得到如下报错:
Error while executing topic command : Replication factor: 4 larger than available brokers: 3.
[2022-06-01 11:35:51,914] ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 4 larger than available brokers: 3.
(kafka.admin.TopicCommand$)那到底设置副本数多大为最合适?
推荐至少 3 个,但是不能超过集群的节点数量。
发布记录
$KAFKA_HOME/bin/kafka-console-producer.sh \
–broker-list node01:9092,node02:9092,node03:9092 \
–topic getting-started \
–property “parse.key=true” \
–property “key.separator=:”记录通过换行进行分割。key 与 value 通过分号进行分割,其由 key.separator 属性指定。进行如下输入:
foo:first message
foo:second message
bar:first message
foo:third message
bar:second message当完成输入时,按 CTRL+D 组合键进行结束。我们可以在下面的图形化界面上看到相应的信息:
消费记录
root@node01:~# $KAFKA_HOME/bin/kafka-console-consumer.sh \
–bootstrap-server node01:9092,node02:9092,node03:9092 \
–topic getting-started \
–group cli-consumer \
–from-beginning \
–property “print.key=true” \
–property “key.separator=:”终端会有如下输出:
bar:first message
bar:second message
foo:first message
foo:second message
foo:third message由于消费者作为订阅运行,并且具有提供的使用者组,因此输出将在上一条记录上停止。消费者将持续地轮询主题 – 不断轮询新记录并在到达主题时打印它们。若要终止消费者,请按 Ctrl+D 组合键。
如果我们再次执行上述命令,我们将看不到任何记录,consumer 将会 halt,等待新的记录以进行消费。
查看 Topic 列表
root@node01:~# $KAFKA_HOME/bin/kafka-topics.sh \ --bootstrap-server node01:9092,node02:9092,node03:9092 \ --list __consumer_offsets demo_kafka_topic_1 getting-started顾名思义,–exclude-internal 选项从查询结果中排除了内部主题(例如 __consumer_offsets)。
root@node01:~# $KAFKA_HOME/bin/kafka-topics.sh \ --bootstrap-server node01:9092,node02:9092,node03:9092 \ --list --exclude-internal demo_kafka_topic_1 getting-starte查看 Topic 详细信息
root@node01:~# $KAFKA_HOME/bin/kafka-topics.sh \
–bootstrap-server node01:9092,node02:9092,node03:9092 \
–describe –topic getting-started输出如下:
Topic: getting-started PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: getting-started Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: getting-started Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: getting-started Partition: 2 Leader: 3 Replicas: 3 Isr: 3删除 Topic
root@node01:~# $KAFKA_HOME/bin/kafka-topics.sh \
–bootstrap-server node01:9092,node02:9092,node03:9092 \
–topic getting-started –delete查看消费组列表
root@node01:~# $KAFKA_HOME/bin/kafka-consumer-groups.sh \ --bootstrap-server node01:9092,node02:9092,node03:9092 \ --list ssl-test-consumer-group python_ssl_consumer efak.system.group查看消费组信息
root@node01:~# $KAFKA_HOME/bin/kafka-consumer-groups.sh \
–bootstrap-server node01:9092,node02:9092,node03:9092 \
–group cli-consumer \
–describe \
–all-topics输出如下:
# 当还有活动成员时
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
cli-consumer getting-started 0 2 2 0 consumer-cli-consumer-1-f96d0081-f3d0-4766-beb3-7bee1135cb45 /192.168.110.99 consumer-cli-consumer-1
cli-consumer getting-started 1 0 0 0 consumer-cli-consumer-1-f96d0081-f3d0-4766-beb3-7bee1135cb45 /192.168.110.99 consumer-cli-consumer-1
cli-consumer getting-started 2 3 3 0 consumer-cli-consumer-1-f96d0081-f3d0-4766-beb3-7bee1135cb45 /192.168.110.99 consumer-cli-consumer-1
## 当没有活动成员时
Consumer group ‘cli-consumer’ has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
cli-consumer getting-started 1 0 0 0 – – –
cli-consumer getting-started 0 2 2 0 – – –
cli-consumer getting-started 2 3 3 0 – – –查看所有的消费者组:
(venv392) root@node01:~/kafka# $KAFKA_HOME/bin/kafka-consumer-groups.sh \ --bootstrap-server node01:9092,node02:9092,node03:9092 \ --describe \ --all-groups \ --all-topics Consumer group 'efak.system.group' has no active members. GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID efak.system.group python_ssl_topic_name 0 4 4 0 - - - efak.system.group python_ssl_topic_name 1 13 13 0 - - - efak.system.group getting-started 0 412 412 0 - - - efak.system.group python_ssl_topic_name 2 1 1 0 - - - efak.system.group test_producer_perf 0 3322651 3322651 0 - - - efak.system.group ssl_test 0 2 4 2 - - - efak.system.group test_producer_perf 1 3333724 3333724 0 - - - GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID python_ssl_consumer python_ssl_topic_name 0 4 4 0 kafka-python-2.0.2-2ea867d2-b94c-474b-a1ca-7e88410f85fd /192.168.110.99 kafka-python-2.0.2 python_ssl_consumer python_ssl_topic_name 1 13 13 0 kafka-python-2.0.2-2ea867d2-b94c-474b-a1ca-7e88410f85fd /192.168.110.99 kafka-python-2.0.2 python_ssl_consumer python_ssl_topic_name 2 1 1 0 kafka-python-2.0.2-4f462ddf-d99e-4c29-98fe-ea0a13e3f417 /192.168.110.99 kafka-python-2.0.2 Consumer group 'ssl-test-consumer-group' has no active members. GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID ssl-test-consumer-group ssl_test 2 5 5 0 - - - ssl-test-consumer-group ssl_test 1 4 4 0 - - - ssl-test-consumer-group ssl_test 0 4 4 0 - - -删除消费组
(venv392) root@node01:~/kafka# $KAFKA_HOME/bin/kafka-consumer-groups.sh \ --bootstrap-server node01:9092,node02:9092,node03:9092 \ --group cli-consumer --deleteKafka 监控
在企业实际应用中,如果业务比较复杂,那么管理的 Consumer Group 和 Topic 数量也会随之增加,此时如果再使用 Kafka 提供的命令行工具的话,就可能会出现力不从心的感觉。
因此,我们需要一款更加好用的 Kafka 监控系统,目前企业使用比较多的有 Kafka Manager、Kafka Eagle 等。
Kafka Eagle
Kafka Eagle 是国人开发的 Kafka 集群管理工具。
Kafka Eagle 介绍
Kafka Eagle 相比 Kafka Manager 要简单、好用些,所以这里将重点介绍 KafkaEagle 这款可视化管理工具。
Kafka Eagle 是一款用来管理 Kafka 集群的可视化工具,它可以支持管理多个 Kafka 集群,还可以管理 Kafka 的 Topic(查看、删除、创建等),也可以对消费者状态进行监控,并可实现消息阻塞告警、集群健康状态检测等功能。官网地址为:链接(
https://www.kafka-eagle.org/)root@node04:~# tar -xf kafka-eagle-bin-2.1.0.tar.gz -C /opt/ root@node04:~# cd /opt/kafka-eagle-bin-2.1.0/ root@node04:/opt/kafka-eagle-bin-2.1.0# tar -xf efak-web-2.1.0-bin.tar.gz -C /opt root@node04:/opt/kafka-eagle-bin-2.1.0# cd /opt root@node04:/opt# ln -sv efak-web-2.1.0 efakKafka Eagle 安装完成后,还需要配置 Java 环境变量和设置 Kafka Eagle 目录,将下面内容加入 /etc/profile 文件中:
export KE_HOME=/opt/efak
export PATH=$PATH:$KE_HOME/bin配置 Kafka Eagle 监控 Kafka
Kafka Eagle 的配置文件位于 $KE_HOME/conf/ 目录下,配置文件为 system-config.properties,配置完成的文件内容如下:
root@node04:/opt/efak/conf# egrep -v “(^#|^$)” system-config.properties
efak.zk.cluster.alias=cluster1
cluster1.zk.list=node01:2181,node02:2181,node03:2181
cluster1.zk.acl.enable=false
cluster1.zk.acl.schema=digest
cluster1.zk.acl.username=test
cluster1.zk.acl.password=test123
cluster1.efak.broker.size=20
kafka.zk.limit.size=16
efak.webui.port=8048
efak.distributed.enable=false
efak.cluster.mode.status=master
efak.worknode.master.host=localhost
efak.worknode.port=8085
cluster1.efak.jmx.acl=false
cluster1.efak.jmx.user=keadmin
cluster1.efak.jmx.password=keadmin123
cluster1.efak.jmx.ssl=false
cluster1.efak.jmx.truststore.location=/data/ssl/certificates/kafka.truststore
cluster1.efak.jmx.truststore.password=ke123456
cluster1.efak.offset.storage=kafka
cluster1.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
efak.metrics.charts=true
efak.metrics.retain=15
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
efak.topic.token=keadmin
cluster1.efak.sasl.enable=false
cluster1.efak.sasl.protocol=SASL_PLAINTEXT
cluster1.efak.sasl.mechanism=SCRAM-SHA-256
cluster1.efak.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username=”kafka” password=”kafka-eagle”;
cluster1.efak.sasl.client.id=
cluster1.efak.blacklist.topics=
cluster1.efak.sasl.cgroup.enable=false
cluster1.efak.sasl.cgroup.topics=
# 使用的数据库驱动,这里我们为了方便,使用了 SQLite
efak.driver=org.sqlite.JDBC
efak.url=jdbc:sqlite:/opt/kafka-eagle/db/ke.db
efak.username=root
efak.password=www.kafka-eagle.org我们这里为例方便,使用了 SQLite 数据库。
最后一个步骤(可选),需要安装一个数据库,因为 Kafka Eagle 需要数据库的支持,这里我们使用用 MySQL 数据库,版本为 mysql 5.5.65,安装过程省略。安装完成后,需要做如下配置和授权:
mysql> create database ke character set utf8;
mysql> create user ‘kafka’@’localhost’ identified by ‘123456’;
mysql> grant all privileges on ke.* to ‘kafka’@’localhost’;
mysql> flush privileges;如果是在生产环境,建议使用 MySQL 数据库。使用 MySQL 的配置如下:
######################################
# kafka mysql jdbc driver address
######################################
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=123456其中,每个配置项含义如下。
· kafka.eagle.zk.cluster.alias:用来指定需要配置的 Kafka 集群名称,可以配置多个,用逗号分隔。
cluster1.zk.list:用来配置多个 Kafka 集群所对应的 ZooKeeper 集群列表。注意这个写法,这是配置 cluster1 集群,如果有多个集群,依次填写每个 Kafka 集群对应的 ZooKeeper 集群列表即可。
kafka.zk.limit.size:设置 ZooKeeper 客户端最大连接数。
· kafka.eagle.webui.port:设置 Kafka Eagle 的 Web 访问端口,默认是 8048。
· cluster1.kafka.eagle.offset.storage:设置存储消费信息的类型,一般在 Kafka 0.9 版本之前,消费信息会默认存储在 ZooKeeper 中,所以存储类型设置 zookeeper 即可。如果你使用的是 Kafka 0.10 之后的版本,那么,消费者信息默认存储在 Kafka 中,所以存储类型需要设置为 kafka。同时,在使用消费者 API 时,尽量保证客户端 Kafka API 版本和 Kafka 服务端的版本一致。
· efak.metrics.charts:设置是否开启 Kafka Eagle 的监控趋势图,默认是不启用方式,如果需要查看 Kafka 监控趋势图,则需要设置为 true。
· kafka.eagle.metrics.retain:设置数据默认保留时间,这里的 15 表示 15 天。
· kafka.eagle.sql.fix.error:在使用 KSQL 查询 Topic 时,如果遇到错误,可以开启这个属性,默认不开启。
· kafka.eagle.sql.topic.records.max:KSQL 查询 Topic 数据默认是最新的 5000 条,如果在使用 KSQL 查询的过程中出现异常,可以将 kafka.eagle.sql.fix.error 的值设置为 true,Kafka Eagle 会在系统中自动修复错误。
· efak.topic.token:设置在删除 Kafka Topic 时的 Token 令牌,需要记住这个值。
· efak.driver:设置连接数据库的驱动信息。
· efak.url:设置 jdbc 连接 MySQL 数据库的地址。
· efak.username:设置连接到 MySQL 数据库的用户名。
· efak.password:设置连接到 MySQL 数据库的用户密码。
JMX 后面增加三个参数,示例如下:
-Dcom.sun.management.jmxremote.host=0.0.0.0 \
-Dcom.sun.management.jmxremote.local.only=false \
-Djava.rmi.server.hostname=[自定义名称]这里给出一个具体的例子,如:
[root@node03 kafka]# grep node03 bin/kafka-run-class.sh
KAFKA_JMX_OPTS=”-Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.host=0.0.0.0 -Dcom.sun.management.jmxremote.local.only=false -Djava.rmi.server.hostname=node03 “其中这三个选项是新增的:
-Dcom.sun.management.jmxremote.host=0.0.0.0 \
-Dcom.sun.management.jmxremote.local.only=false \
-Djava.rmi.server.hostname=node03Kafka Eagle 使用
需要在 2G 的机器上才可以正常使用。但我们可以修改启动参数,这样就可以适应配置较低的机器。
启动服务
所有配置完成后,就可以启动 Kafka Eagle 服务了,执行如下命令启动服务:
[root@node04 opt]# cd $KE_HOME/bin [root@node04 bin]# ./ke.sh start [2022-05-09 21:24:37] INFO: Starting EFAK( Eagle For Apache Kafka ) environment check ... created: META-INF/ inflated: META-INF/MANIFEST.MF created: WEB-INF/ created: WEB-INF/classes/ created: WEB-INF/classes/messages/ ... inflated: WEB-INF/lib/kafka-eagle-common-2.0.1.jar inflated: WEB-INF/lib/janino-3.0.11.jar inflated: WEB-INF/lib/spring-beans-5.2.0.RELEASE.jar inflated: WEB-INF/lib/aspectjrt-1.8.10.jar inflated: WEB-INF/lib/j2objc-annotations-1.3.jar inflated: WEB-INF/lib/kafka-clients-2.0.0.jar inflated: WEB-INF/lib/commons-beanutils-1.9.4.jar inflated: WEB-INF/lib/kafka-eagle-plugin-2.0.1.jar inflated: media/css/bscreen/font/DS-DIGIT.TTF inflated: media/css/img/glyphicons-halflings.png inflated: media/css/public/images/ui-icons_888888_256x240.png ... [2022-05-09 21:24:49] INFO: Port Progress: [##################################################] | 100% [2022-05-09 21:24:53] INFO: Config Progress: [##################################################] | 100% [2022-05-09 21:24:56] INFO: Startup Progress: [##################################################] | 100% [2022-05-09 21:24:37] INFO: Status Code[0] [2022-05-09 21:24:37] INFO: [Job done!] Welcome to ______ ______ ___ __ __ / ____/ / ____/ / | / //_/ / __/ / /_ / /| | / ,< / /___ / __/ / ___ | / /| | /_____/ /_/ /_/ |_|/_/ |_| ( Eagle For Apache Kafka® ) Version 2.1.0 -- Copyright 2016-2022 ******************************************************************* * EFAK Service has started success. * Welcome, Now you can visit 'http://192.168.110.158:8048' * Account:admin ,Password:123456 ******************************************************************* * <Usage> ke.sh [start|status|stop|restart|stats] </Usage> * <Usage> https://www.kafka-eagle.org/ </Usage> ******************************************************************* [root@node04 bin]# jps 6353 KafkaEagle 6430 Jps服务启动成功后,可以看到有个 KafkaEagle 进程标识,表示启动成功,要查看 Kafka Eagle 启动日志,可访问 Kafka Eagle 的 logs 目录,主要查看 log.log、error.log 及 ke_console.out 三个文件。如果启动失败,文件中会有失败信息及失败原因。
$KE_HOME/bin/ke.sh 支持的命令选项:
无法复制加载中的内容
要关闭 Kafka Eagle 服务,执行“./ke.sh stop”即可。
Kafka Eagle 服务启动后,即可打开 Web 界面,默认 Web 登录用户名为 admin,密码为 123456,登录端口为 8048,访问
http://192.168.110.158:8048 地址即可打开登录界面。登录界面
操作界面
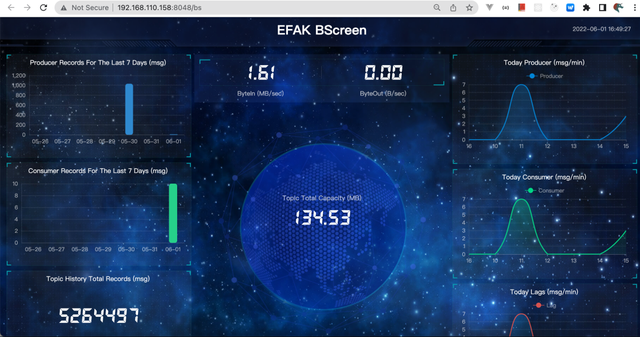
BScreen 界面:
上面这个界面还是有点逼格的。
Dashboard:
Cluster Info:
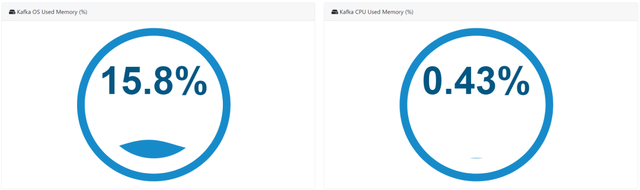
Metrics 监控
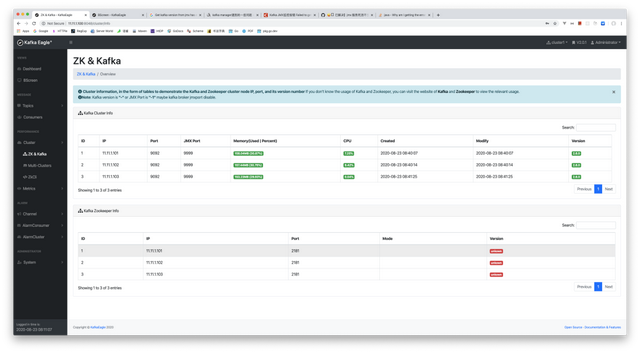
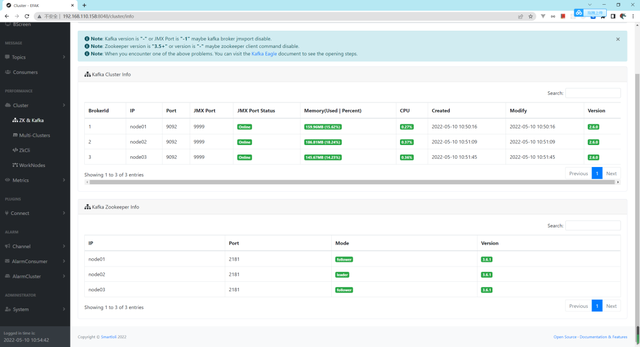
我们查看整个集群的一些监控信息,URL 为:
http://192.168.110.158:8048/cluster/info,由上图可以看到,我们并没有获取到集群的指标信息。需要进行一定的配置,才可以看到这些信息,接下来,我们分配配置 Kafka 及 Zookeeper,使得 Eagle 可以获取它们的指标信息。
配置 Kafka
为了使用 Kafka Eagle 的监控趋势图,因此,还需要开启 Kafka 系统的 JMX 端口,默认 Kafka 没有开启 JMX 端口,可修改 Kafka 启动脚本 kafka-server-start.sh,大约在第 29 行下面添加如下内容:
if [ “x$KAFKA_HEAP_OPTS” = “x” ]; then
export KAFKA_HEAP_OPTS=”-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70″
export JMX_PORT=”9999″ # 增加此行
fi注意,这个 9999 端口可修改为任意其他端口。在 Kafka 集群中所有节点添加这个配置,添加完成后,重启所有 Kafka 集群节点以使配置生效。查看 9999 端口是否可用:
[root@node03 kafka]# lsof -i:9999
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
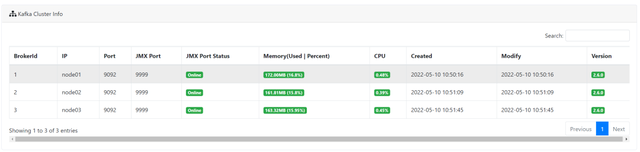
java 27191 root 106u IPv6 56551 0t0 TCP *:distinct (LISTEN)经过上面的配置后,我们就可以看到 Kafka 集群的信息了。如下:
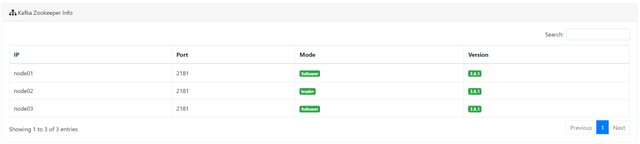
配置 Zookeeper
如果我们使用的 3.5+ 版本,我们需要做如下修改。修改 $ZK_HOME/bin/zkServer.sh 脚本,大约在 77 行的位置,增加如下配置:
vi zkServer.sh # 增加下面一行 ZOOMAIN="-Dzookeeper.4lw.commands.whitelist=* ${ZOOMAIN}"再次查看 Metrics 信息
报警
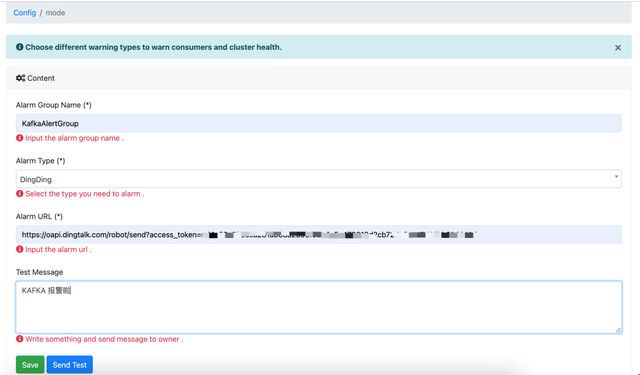
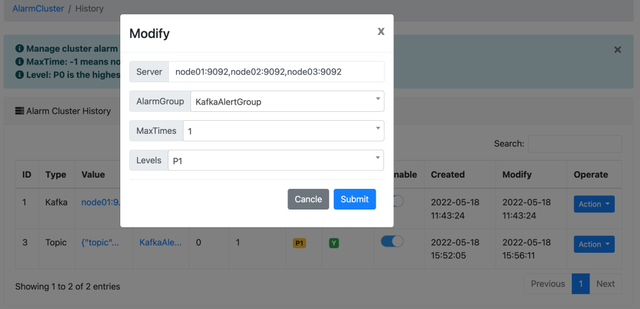
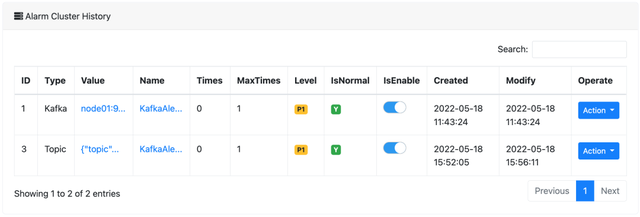
配置报警
从 2.1.0 开始在界面上进行配置。配置界面如下(目前手头上只有钉钉,所以配置了钉钉报警。还可以配置企业微信及邮件报警):
Kafka 节点监控,配置如下:
这里就是我们刚刚配置的两个告警,
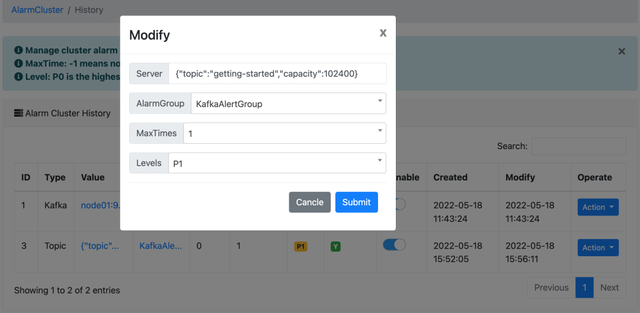
触发报警
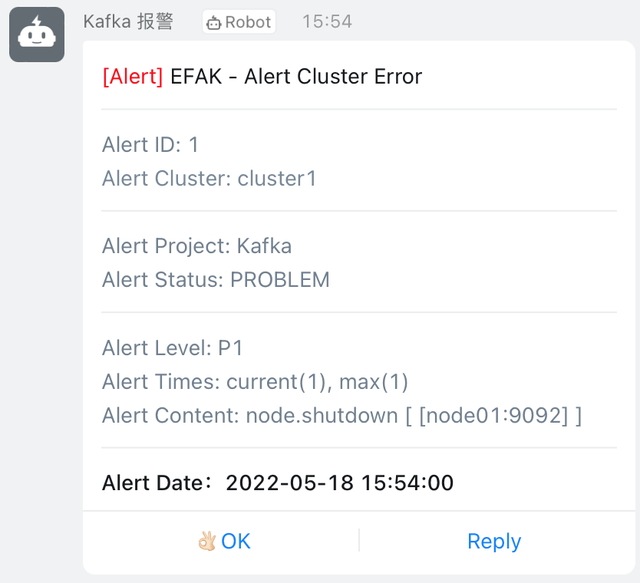
Topic 容量监控,配置如下(名为 getting-started 的 Topic,其容量大于 102400 字节时就报警):
如果设置成功,就会收到如下的报警:
报警如果恢复的话,会有如下恢复的提示:
上面我们仅演示了 EFAK 对 Kafka 的节点及 Topic 进行了监控。它还支持:
· Producer 的监控
· Consumer 的监控
· Zookeeper 的监控
配置还是非常简单的,我们这里就不过多地介绍。如果大家要使用该功能,推荐动手配置一下。
推荐使用 Kafka Eagle 来运维管理及监控 Kafka 集群。简单、好用、符合国人的口味。
有了上面的这些内容,完全可以搭建出一套可用的 Kafka 集群,而且是高可用的集群。但仅仅这些是不够的,默认情况下,Kafka 是不安全的。如果对于安全比较严格的公司,上面的架构及部署可能会审批不通过。
为了让 Kafka 集群更安全,我们继续往下看。
Kafka 安全
Kafka 0.9 之前,Kafka 集群是没有安全机制的。在之后的版本中,Kafka 新增了两种安全机制:
· 身份验证
· 权限控制
默认状态下的 Kafka
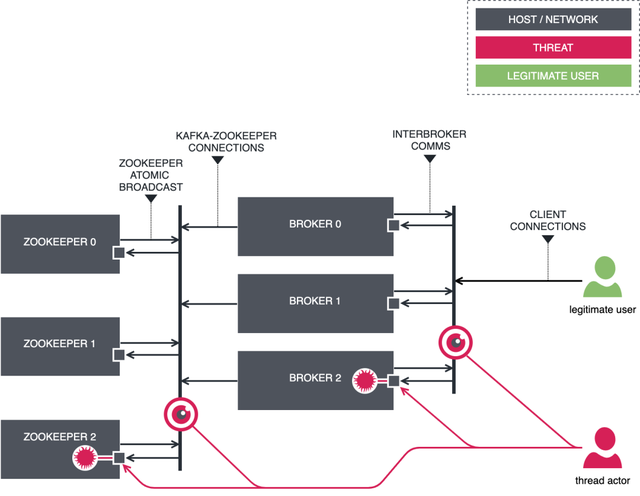
默认的 Kafka 是不安全的,如下图所示:
- 任何客户端可以连接 Zookeeper 或 Kafka 节点:
- 任何人都可以连接这两个常规端口 2181(ZooKeeper)和 9092(Kafka)。ZooKeeper 对于潜在的攻击者来说是一个非常易受攻击的点,因为写入 znodes(用于在ZooKeeper中持久保存状态的内部数据结构)将轻而易举地破坏整个集群。
- 连接 Kafka brokers 是非加密的:
- 连接通过TCP建立,各方通过二进制协议交换数据。有权访问传输网络的第三方可以使用基本的数据包嗅探器来捕获和分析网络流量,从而获得对信息的未经授权的访问。恶意执行组件可能会更改传输中的信息,或者模拟代理或客户端。除了客户端流量之外,默认情况下,跨行流量也是不安全的。
- 连接 Kafka brokers 是未经身份验证的:
- 任何客户端都可以与 borker 建立连接,客户端不必标识自己,也不必证明所提供的身份是真实的。
- 没有授权控制措施:
- 即使启用了身份验证,客户端也可以对 borker 执行任何操作。默认授权策略是 allow-all,让恶意客户端疯狂运行。
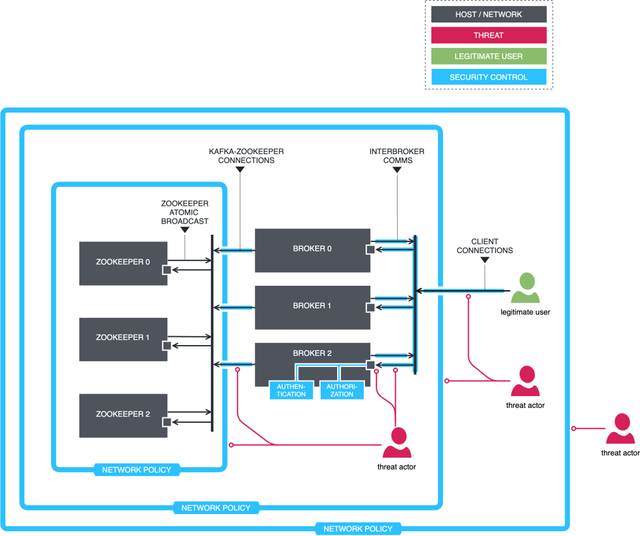
理想状态下的 Kafka
配置 SSL
客户端到 Broker 端加密
在 Kafka 集群中,SSL 协议作为认证机制默认是不启用的。如果需要使用,可以手工开启。创建证书的过程还是挺复杂的,步骤非常多。它的大致步骤如下:
1、为每个 Broker 节点创建秘钥库
2、创建私有证书 CA
3、对证书进行签名、导入 CA 和证书到密钥库
4、配置服务端与客户端
创建私钥
在执行命令之前,我们设置一些环境变量,这样下面演示命令的时候就会简洁很多:
root@node01:~# DNAME=”CN=Tyun Tech, OU=tyun.cn, O=tyun.cn, L=Shanghai, ST=Shanghai, C=CN”
root@node01:~# PASSWORD=changeit12345
root@node01:~# KEY_PASSWORD=$PASSWORD
root@node01:~# STORE_PASSWORD=$PASSWORD
root@node01:~# TRUST_KEY_PASSWORD=$PASSWORD
root@node01:~# TRUST_STORE_PASSWORD=$PASSWORD在其中一个节点(我们这里选择了 node01 节点)执行命令:
# 创建服务端用的秘钥
root@node01:~# keytool \
-keystore $KEY_STORE \
-alias kafka-server \
-validity $DAYS_VALID \
-genkey -keyalg RSA \
-storepass $STORE_PASSWORD \
-keypass $KEY_PASSWORD -dname “$DNAME”
# 创建客户端用的秘钥
root@node01:~# keytool \
-keystore $CLIENT_KEY_STORE \
-alias kafka-client \
-validity $DAYS_VALID \
-genkey -keyalg RSA \
-storepass $STORE_PASSWORD \
-keypass $KEY_PASSWORD -dname “$DNAME”查看密钥库文件:
(venv392) root@node01:~/mycerts/certificates# echo $PASSWORD |keytool -list -v -keystore server.keystore.jks |head -20
Enter keystore password:
***************** WARNING WARNING WARNING *****************
* The integrity of the information stored in your keystore *
* has NOT been verified! In order to verify its integrity, *
* you must provide your keystore password. *
***************** WARNING WARNING WARNING *****************
Keystore type: jks
Keystore provider: SUN
Your keystore contains 2 entries
Alias name: caroot
Creation date: May 30, 2022
Entry type: trustedCertEntry
Owner: OU=”tyun.cn,CN=Tyun Tech”, O=tyun.cn, L=Shanghai, ST=Shanghai, C=CN
Issuer: OU=”tyun.cn,CN=Tyun Tech”, O=tyun.cn, L=Shanghai, ST=Shanghai, C=CN
Serial number: 1b75081359742c8f40980f4450776c56c9fffc6b
Valid from: Mon May 30 15:19:50 CST 2022 until: Tue May 30 15:19:50 CST 2023
Certificate fingerprints:
SHA1: B1:BA:9F:10:83:53:42:EA:4C:17:B8:C4:A3:3B:4F:98:72:AB:07:63
SHA256: F3:F2:3F:B7:04:A4:F5:3F:2F:DD:DB:D3:1E:64:D2:20:76:92:DD:47:F4:12:45:4D:10:9B:71:B0:10:25:0E:A8
Signature algorithm name: SHA256withRSA
Subject Public Key Algorithm: 2048-bit RSA key
Version: 3
(venv392) root@node01:~/mycerts/certificates# echo $PASSWORD |keytool -list -v -keystore client.keystore.jks |head -20创建 CA
root@node01:~# openssl req \ -new -x509 \ -keyout $CERT_OUTPUT_PATH/ca-key \ -out "$CERT_AUTH_FILE" \ -days "$DAYS_VALID" \ -passin pass:"$PASSWORD" \ -passout pass:"$PASSWORD" \ -subj "/C=CN/ST=Shanghai/L=Shanghai/O=tyun.cn/OU=tyun.cn,CN=Tyun Tech"查看已生成的文件:
root@node01:~# ll ca-*
-rw-r–r– 1 root root 1363 May 30 14:19 ca-cert
-rw——- 1 root root 1854 May 30 14:18 ca-key添加 CA 文件到 borker 节点 truststore:
# 添加 CA 文件到 broker truststore root@node01:~# keytool -keystore "$TRUST_STORE" -alias CARoot \ -importcert -file "$CERT_AUTH_FILE" \ -storepass "$TRUST_STORE_PASSWORD" \ -keypass "$TRUST_KEY_PASS" -noprompt # 添加 CA 文件到 client truststore root@node01:~# keytool \ -keystore "$CLIENT_TRUST_STORE" \ -alias CARoot \ -importcert -file "$CERT_AUTH_FILE" \ -storepass "$TRUST_STORE_PASSWORD" \ -keypass "$TRUST_KEY_PASS" -noprompt从 keystore 中导出集群证书:
root@node01:~# keytool \
-keystore “$KEY_STORE” \
-alias kafka-server \
-certreq -file “$CERT_OUTPUT_PATH/server-cert-file” \
-storepass “$STORE_PASSWORD” \
-keypass “$KEY_PASSWORD” -noprompt
root@node01:~# keytool \
-keystore “$CLIENT_KEY_STORE” \
-alias kafka-client \
-certreq -file “$CERT_OUTPUT_PATH/client-cert-file” \
-storepass “$STORE_PASSWORD” \
-keypass “$KEY_PASSWORD” -noprompt使用 CA 签发证书:
root@node01:~# openssl x509 \
-req -CA “$CERT_AUTH_FILE” \
-CAkey $CERT_OUTPUT_PATH/ca-key \
–in “$CERT_OUTPUT_PATH/server-cert-file” \
-out “$CERT_OUTPUT_PATH/server-cert-signed” \
-days “$DAYS_VALID” \
-CAcreateserial -passin pass:”$PASSWORD”
root@node01:~# openssl x509 \
-req -CA “$CERT_AUTH_FILE” \
-CAkey $CERT_OUTPUT_PATH/ca-key \
–in “$CERT_OUTPUT_PATH/client-cert-file” \
-out “$CERT_OUTPUT_PATH/client-cert-signed” \
-days “$DAYS_VALID” \
-CAcreateserial -passin pass:”$PASSWORD”导入 CA 文件到 keystore:
root@node01:~# keytool \
-keystore “$KEY_STORE” \
-alias CARoot \
-import -file “$CERT_AUTH_FILE” \
-storepass “$STORE_PASSWORD” \
-keypass “$KEY_PASSWORD” -noprompt
root@node01:~# keytool \
-keystore “$CLIENT_KEY_STORE” \
-alias CARoot \
-import -file “$CERT_AUTH_FILE” \
-storepass “$STORE_PASSWORD” \
-keypass “$KEY_PASSWORD” -noprompt导入已签发证书到 keystore:
root@node01:~# keytool \
-keystore “$KEY_STORE” \
-alias kafka-server \
-import -file “$CERT_OUTPUT_PATH/server-cert-signed” \
-storepass “$STORE_PASSWORD” \
-keypass “$KEY_PASSWORD” -noprompt
root@node01:~# keytool \
-keystore “$CLIENT_KEY_STORE” \
-alias kafka-client \
-import -file “$CERT_OUTPUT_PATH/client-cert-signed” \
-storepass “$STORE_PASSWORD” \
-keypass “$KEY_PASSWORD” -noprompt上述步骤非常的繁琐,我们这里把上述过程写到了一个脚本中,这样可以方便地生成证书及自签名。脚本如下:
#!/bin/bash
BASE_DIR=/root/mycerts
CERT_OUTPUT_PATH=”$BASE_DIR/certificates”
PASSWORD=changeit12345
KEY_STORE=”$CERT_OUTPUT_PATH/server.keystore.jks”
TRUST_STORE=”$CERT_OUTPUT_PATH/server.truststore.jks”
CLIENT_KEY_STORE=”$CERT_OUTPUT_PATH/client.keystore.jks”
CLIENT_TRUST_STORE=”$CERT_OUTPUT_PATH/client.truststore.jks”
KEY_PASSWORD=$PASSWORD
STORE_PASSWORD=$PASSWORD
TRUST_KEY_PASSWORD=$PASSWORD
TRUST_STORE_PASSWORD=$PASSWORD
CERT_AUTH_FILE=”$CERT_OUTPUT_PATH/ca-cert”
DAYS_VALID=365
DNAME=”CN=Tyun Tech, OU=tyun.cn, O=tyun.cn, L=Shanghai, ST=Shanghai, C=CN”
mkdir -p $CERT_OUTPUT_PATH
echo “1. 产生 key 和证书……”
keytool \
-keystore $KEY_STORE \
-alias kafka-server \
-validity $DAYS_VALID \
-genkey -keyalg RSA \
-storepass $STORE_PASSWORD \
-keypass $KEY_PASSWORD -dname “$DNAME”
keytool \
-keystore $CLIENT_KEY_STORE \
-alias kafka-client \
-validity $DAYS_VALID \
-genkey -keyalg RSA \
-storepass $STORE_PASSWORD \
-keypass $KEY_PASSWORD -dname “$DNAME”
echo “2. 创建 CA……”
openssl req \
-new -x509 \
-keyout $CERT_OUTPUT_PATH/ca-key \
-out “$CERT_AUTH_FILE” \
-days “$DAYS_VALID” \
-passin pass:”$PASSWORD” \
-passout pass:”$PASSWORD” \
-subj “/C=CN/ST=Shanghai/L=Shanghai/O=tyun.cn/OU=tyun.cn,CN=Tyun Tech”
echo “3. 添加 CA 文件到 broker truststore……”
keytool -keystore “$TRUST_STORE” -alias CARoot \
-importcert -file “$CERT_AUTH_FILE” \
-storepass “$TRUST_STORE_PASSWORD” \
-keypass “$TRUST_KEY_PASS” -noprompt
echo “4. 添加 CA 文件到 client truststore……”
keytool \
-keystore “$CLIENT_TRUST_STORE” \
-alias CARoot \
-importcert -file “$CERT_AUTH_FILE” \
-storepass “$TRUST_STORE_PASSWORD” \
-keypass “$TRUST_KEY_PASS” -noprompt
echo “5. 从 keystore 中导出集群证书……”
keytool \
-keystore “$KEY_STORE” \
-alias kafka-server \
-certreq -file “$CERT_OUTPUT_PATH/server-cert-file” \
-storepass “$STORE_PASSWORD” \
-keypass “$KEY_PASSWORD” -noprompt
keytool \
-keystore “$CLIENT_KEY_STORE” \
-alias kafka-client \
-certreq -file “$CERT_OUTPUT_PATH/client-cert-file” \
-storepass “$STORE_PASSWORD” \
-keypass “$KEY_PASSWORD” -noprompt
echo “6. 使用 CA 签发证书……”
openssl x509 \
-req -CA “$CERT_AUTH_FILE” \
-CAkey $CERT_OUTPUT_PATH/ca-key \
–in “$CERT_OUTPUT_PATH/server-cert-file” \
-out “$CERT_OUTPUT_PATH/server-cert-signed” \
-days “$DAYS_VALID” \
-CAcreateserial -passin pass:”$PASSWORD”
openssl x509 \
-req -CA “$CERT_AUTH_FILE” \
-CAkey $CERT_OUTPUT_PATH/ca-key \
–in “$CERT_OUTPUT_PATH/client-cert-file” \
-out “$CERT_OUTPUT_PATH/client-cert-signed” \
-days “$DAYS_VALID” \
-CAcreateserial -passin pass:”$PASSWORD”
echo “7. 导入 CA 文件到 keystore……”
keytool \
-keystore “$KEY_STORE” \
-alias CARoot \
-import -file “$CERT_AUTH_FILE” \
-storepass “$STORE_PASSWORD” \
-keypass “$KEY_PASSWORD” -noprompt
keytool \
-keystore “$CLIENT_KEY_STORE” \
-alias CARoot \
-import -file “$CERT_AUTH_FILE” \
-storepass “$STORE_PASSWORD” \
-keypass “$KEY_PASSWORD” -noprompt
echo “8. 导入已签发证书到 keystore……”
keytool \
-keystore “$KEY_STORE” \
-alias kafka-server \
-import -file “$CERT_OUTPUT_PATH/server-cert-signed” \
-storepass “$STORE_PASSWORD” \
-keypass “$KEY_PASSWORD” -noprompt
keytool \
-keystore “$CLIENT_KEY_STORE” \
-alias kafka-client \
-import -file “$CERT_OUTPUT_PATH/client-cert-signed” \
-storepass “$STORE_PASSWORD” \
-keypass “$KEY_PASSWORD” -noprompt部署私钥及已签名证书到 Broker
root@node01:~/mycerts/certificates# pwd
/root/mycerts/certificates
root@node01:~/mycerts/certificates# ll
total 32
-rw-r–r– 1 root root 1330 May 30 15:19 ca-cert
-rw——- 1 root root 1854 May 30 15:19 ca-key
-rw-r–r– 1 root root 4140 May 30 15:19 client.keystore.jks
-rw-r–r– 1 root root 1004 May 30 15:19 client.truststore.jks
-rw-r–r– 1 root root 4139 May 30 15:19 server.keystore.jks
-rw-r–r– 1 root root 1004 May 30 15:19 server.truststore.jks使用 Ansible 分发服务端相关证书:
(venv392) root@node01:~/mycerts/certificates# ansible \
-i /root/kafka/hosts ‘kafka’ \
-m copy -a ‘src=server.keystore.jks dest=/data/apps/kafka/config/’
(venv392) root@node01:~/mycerts/certificates# ansible \
-i /root/kafka/hosts ‘kafka’ \
-m copy -a ‘src=server.truststore.jks dest=/data/apps/kafka/config/’
# 验证证书是否复制成功
(venv392) root@node01:~/mycerts/certificates# ansible \
-i /root/kafka/hosts ‘kafka’ \
-m shell -a “ls -l /data/apps/kafka/config/*.jks”
node01 | CHANGED | rc=0 >>
-rw-r–r– 1 root root 4139 May 30 15:22 server.keystore.jks
-rw-r–r– 1 root root 1004 May 30 15:22 server.truststore.jks
node02 | CHANGED | rc=0 >>
-rw-r–r– 1 root root 4139 May 30 15:26 server.keystore.jks
-rw-r–r– 1 root root 1004 May 30 15:28 server.truststore.jks
node03 | CHANGED | rc=0 >>
-rw-r–r– 1 root root 4139 May 30 15:26 erver.keystore.jks
-rw-r–r– 1 root root 1004 May 30 15:28 server.truststore.jks证书分发完成,可以重启 Kafka 集群。这里以 node01 举例:
(venv392) root@node01:~# $KAFKA_HOME/bin/kafka-server-stop.s (venv392) root@node01:~# $KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties启动的时候可以看下日志,是否有报错。还真是有报错,如下:
[2022-05-30 16:25:53,362] INFO [SocketServer brokerId=3] Failed authentication with /192.168.110.197 (SSL handshake failed) (org.apache.kafka.common.network.Selector) [2022-05-30 16:25:53,492] INFO [Controller id=3, targetBrokerId=3] Failed authentication with node03/192.168.110.197 (SSL handshake failed) (org.apache.kafka.common.network.Selector) [2022-05-30 16:25:53,493] ERROR [Controller id=3, targetBrokerId=3] Connection to node 3 (node03/192.168.110.197:9093) failed authentication due to: SSL handshake failed (org.apache.kafka.clients.NetworkClient)为什么呢?查了下官网文档,解决办法如下:
ssl.endpoint.identification.algorithm=高版本的 Kafka 启用了主机名验证,它默认会验证服务器端的主机名是否匹配 Broker 端证书里的主机名。我们可以在 server.properties 文件中添加上述行以忽略 SSL 握手错误。
使用 SSL 协议进行创建一个主体。首先准备 Producer 的配置文件:
(venv392) root@node01:~/kafka# cat ssl_producer.properties security.protocol=SSL ssl.truststore.location=/root/mycerts/certificates/client.truststore.jks ssl.truststore.password=changeit12345 ssl.keystore.location=/root/mycerts/certificates/server.keystore.jks ssl.keystore.password=changeit12345 ssl.key.password=changeit12345 ssl.endpoint.identification.algorithm=使用如下命令创建:
(venv392) root@node01:~/kafka# $KAFKA_HOME/bin/kafka-console-producer.sh \ --bootstrap-server=node01:9093,node02:9093,node03:9093 \ --topic ssl_test \ --producer.config ./ssl_p.properties >hello >hello >hello >world >world我们在 ssl_test Topic 下面创建了 5 条消息,可以按 CTRL+D 组合键结束。可以在 EFAK 的 WEB 界面查看该主题的信息:
上面是生产者的验证。接下来我们验证 Consumer 在 SSL 协议下是否可以正常工作。首先准备 Consumer 的配置文件:
(venv392) root@node01:~/kafka# cat ssl_consumer.properties
security.protocol=SSL
group.id=ssl-test-consumer-group
ssl.truststore.location=/root/mycerts/certificates/client.truststore.jks
ssl.truststore.password=changeit12345
ssl.keystore.location=/root/mycerts/certificates/server.keystore.jks
ssl.keystore.password=changeit12345
ssl.key.password=changeit12345
ssl.endpoint.identification.algorithm=接着消费 ssl_test 主题下面的消息:
(venv392) root@node01:~/kafka# $KAFKA_HOME/bin/kafka-console-consumer.sh \ --bootstrap-server=node01:9093,node02:9093,node03:9093 \ --topic ssl_test \ --from-beginning \ --consumer.config ./ssl_consumer.properties hello hello world hello world通过上述输出,我们可以看到 Consumer 通过 SSL 协议可以正常消费消息。至此,SSL 加密及验证已经大功告成。如果是使用 Java 代码,那么生产者的代码大致如下:
public final class SslProducerSample { public static void main(String[] args) throws InterruptedException { final var topic = "getting-started"; final Map<String, Object> config = Map.of(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node01:9093,node02:9093,node03:9093", CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SSL", SslConfigs.SSL_ENDPOINT_IDENTIFICATION_ALGORITHM_CONFIG, "https", SslConfigs.SSL_TRUSTSTORE_LOCATION_CONFIG, "client.truststore.jks", SslConfigs.SSL_TRUSTSTORE_PASSWORD_CONFIG, "changeit12345", ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName(), ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName(), ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true); try (var producer = new KafkaProducer<String, String>(config)) { while (true) { final var key = "myKey"; final var value = new Date().toString(); out.format("Publishing record with value %s%n", value); final Callback callback = (metadata, exception) -> { out.format("Published with metadata: %s, error: %s%n", metadata, exception); }; // publish the record, handling the metadata in the callback producer.send(new ProducerRecord<>(topic, key, value), callback); // wait a second before publishing another Thread.sleep(1000); } } } }消费者的代码大致如下:
public final class SslConsumerSample { public static void main(String[] args) { final var topic = "getting-started"; final Map<String, Object> config = Map.of(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node01:9093,node02:9093,node03:9093", CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SSL", SslConfigs.SSL_ENDPOINT_IDENTIFICATION_ALGORITHM_CONFIG, "https", SslConfigs.SSL_TRUSTSTORE_LOCATION_CONFIG, "client.truststore.jks", SslConfigs.SSL_TRUSTSTORE_PASSWORD_CONFIG, "changeit12345", ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName(), ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName(), ConsumerConfig.GROUP_ID_CONFIG, "basic-consumer-sample", ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest", ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); try (var consumer = new KafkaConsumer<String, String>(config)) { consumer.subscribe(Set.of(topic)); while (true) { final var records = consumer.poll(Duration.ofMillis(100)); for (var record : records) { out.format("Got record with value %s%n", record.value()); } consumer.commitAsync(); } } } }Broker 端加密
启用 Broker 之间通信使用 SSL,需要添加配置到 server.properties,如下:
inter.broker.listener.name=SSL
配置修改完成后,重启每台节点,之后验证是否 9093 端口已经监听:
root@node01:~# $KAFKA_HOME/bin/kafka-server-stop.sh root@node01:~# $KAFKA_HOME/bin/kafka-server-start.sh \ -daemon $KAFKA_HOME/config/server.properties root@node01:~# netstat -an | egrep "9092|9093" tcp6 0 0 :::9092 :::* LISTEN tcp6 0 0 :::9093 :::* LISTEN tcp6 0 0 192.168.110.99:9093 192.168.110.197:44040 ESTABLISHED tcp6 0 0 192.168.110.99:9093 192.168.110.211:54720 ESTABLISHED tcp6 0 0 192.168.110.99:38244 192.168.110.197:9093 ESTABLISHED tcp6 0 0 192.168.110.99:60214 192.168.110.211:9093 ESTABLISHEDBroker 端到 Zookeeper 端加密
Zookeeper 的 SSL 配置
root@node01:/data/apps/zookeeper-3.6.1/conf# cat zoo.cfg
tickTime=2000
initLimit=20
syncLimit=10
quorumListenOnAllIPs=true
dataDir=/data/apps/zookeeper-3.6.1/data
dataLogDir=/data/apps/zookeeper-3.6.1/logs
secureClientPort=2182
serverCnxnFactory=org.apache.zookeeper.server.NettyServerCnxnFactory
ssl.keyStore.location=/data/apps/zookeeper-3.6.1/conf/zkserver.keystore.jks
ssl.keyStore.password=changeit12345
ssl.trustStore.location=/data/apps/zookeeper-3.6.1/conf/zkserver.truststore.jks
ssl.trustStore.password=changeit12345
server.1=node01.tyun.cn:2888:3888
server.2=node02.tyun.cn:2888:3888
server.3=node03.tyun.cn:2888:3888Kafka 连接 Zookeeper 的 SSL 配置
root@node01:/data/apps/kafka/config# cat server.properties
……
# broker to zookeeper use ssl
zookeeper.connect=node01.tyun.cn:2182,node02.tyun.cn:2182,node03.tyun.cn:2182
zookeeper.connection.timeout.ms=18000
zookeeper.ssl.client.enable=true
zookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNetty
zookeeper.ssl.endpoint.identification.algorithm=false
zookeeper.ssl.hostnameVerification=false
zookeeper.ssl.quorum.hostnameVerification=false
zookeeper.ssl.keystore.location=/data/apps/kafka/config/zkclient.keystore.jks
zookeeper.ssl.keystore.password=changeit12345
zookeeper.ssl.truststore.location=/data/apps/kafka/config/zkclient.truststore.jks
zookeeper.ssl.truststore.password=changeit12345创建消息及验证 SSL 通信协议
# 生产记录
root@node01:~/kafka# export KAFKA_HOME=/data/apps/kafka
root@node01:~/kafka# $KAFKA_HOME/bin/kafka-console-producer.sh \
–bootstrap-server node01.tyun.cn:9093,node02.tyun.cn:9093,node03.tyun.cn:9093 \
–topic ssl_test \
–producer.config /root/kafka/ssl_producer.properties
>hello world
>hahh hhhhh
# 消费记录
root@node01:~/kafka# $KAFKA_HOME/bin/kafka-console-consumer.sh \
–bootstrap-server node01.tyun.cn:9093,node02.tyun.cn:9093,node03.tyun.cn:9093 \
–topic ssl_test \
–from-beginning \
–consumer.config /root/kafka/ssl_consumer.properties
hello world
hahh hhhhh如果 Zookeeper 使用了 SSL 加密,那么一些监控工具(Kafka Manager、Kafka Eagle)连接 Zookeeper 时会出现问题。可以考虑使用 SASL 进行加密通信。
Kafka MirrorMaker
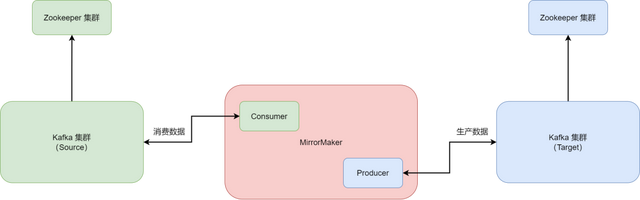
Kakfa MirrorMaker 是 Kafka 官方提供的一个跨数据中心的流数据同步方案。它的实现原理是从一个源 Kafka 集群消费消息,然后在将消息生产到目标 Kafka 集群,其实就是一个普通的生产和消费。
要使用 MirrorMaker,只需要简单地配置一下 MirrorMaker 的 Consumer 和 Producer,然后启动 MirrorMaker,就可以实现两个 Kafka 集群的准实时数据同步。
下图是一个 MirrorMaker 原理架构图:
从图中可以看出,MirrorMaker 位于源 Kafka 集群和目标 Kafka 集群之间,MirrorMaker 从源 Kafka 集群消费数据,此时 MirrorMaker 是一个 Consumer;接着,Kafka 将消费过来的数据直接通过网络传输到目标的 Kafka 集群中,此时 MirrorMaker 是一个 Producer。在实际的使用中,源 Kafka 集群和目标 Kafka 集群可以在不同的网络中,也可以跨广域网,此时的 MirrorMaker 就是一个 Kafka 集群的镜像,实现了数据的实时同步和异地备份。
可以参考:Kafka迁移 (
https://tyun.feishu.cn/wiki/wikcnZY3jQd8yioA32A3jJtRqwd)附录
本章节我们给出了一些列的图形化管理工具,大家可以根据需要进行选择与使用。
图形化及监控工具推荐
KafDrop
KafDrop 是一款轻量级的 Kafka 集群管理界面,它只有一个 Jar 包。它需要 JDK 11 运行环境。其项目地址为:obsidiandynamics/kafdrop: Kafka Web UI (github.com)。
它的部署非常简单,下载已经编译好的 Jar 包即可使用。命令如下:
root@node04:~# /opt/jdk-11.0.9/bin/java -jar kafdrop-3.30.0.jar \
–kafka.brokerConnect=node01:9092,node02:9092,node03:9092其运行界面为:
logiKM
滴滴开源的 Apache Kafka 集群性能指标监控及运维管理工具。其项目地址为:didi/LogiKM: 一站式Apache Kafka集群指标监控与运维管控平台 (github.com) (
https://github.com/didi/LogiKM)。Kafka Manager
如今已经更名为 CMAK (Cluster Manager for Apache Kafka)。Github 仓库地址为:
https://github.com/yahoo/CMAK
最新版的 Kafka Manager 需要使用 JDK11。
root@node04:~# wget -c https://github.com/yahoo/CMAK/releases/download/3.0.0.6/cmak-3.0.0.6.zip
root@node04:~# unzip cmak-3.0.0.6.zip -d /opt/
# 配置 CMAK
root@node04:/opt/cmak# grep cmak.zkhosts conf/application.conf
cmak.zkhosts=”node01:2181,node02:2181,node03:2181″
cmak.zkhosts=${?ZK_HOSTS}
# 如果不想使用硬编码的形式,可以使用环境变量
ZK_HOSTS=”node01:2181,node02:2181,node03:2181″
# 启动服务,默认端口是 9000
root@node04:/opt/cmak# /opt/cmak/bin/cmak
# 可以指定端口,如 8080
root@node04:/opt/cmak# /opt/cmak/bin/cmak \
-Dconfig.file=/opt/cmak/application.conf \
-Dhttp.port=8080
# 可以指定 JDK 版本
root@node04:/opt/cmak# /opt/cmak/bin/cmak \
-java-home /opt/jdk-11.0.9启动之后的界面如下:
参考文献
- Effective Kafka
- Docs (kafka-eagle.org)
- KafkaProducer ‒ kafka-python 2.0.2-dev documentation
- IBM Docs
推荐资料
· 概览& 成长地图分布式消息服务Kafka版华为云
很多云厂商的帮助文档,也是不错的学习资料。
云和安全管理服务商