-
基于互联网架构演进, 构建秒杀系统
云和安全管理服务专家新钛云服 杨良春原创
系统架构师思考
秒杀活动是指网络商家为促销等目的组织会网上限时抢购活动,这种活动具有瞬时并发量大、库存量少和业务逻辑简单等特点。
设计一个秒杀系统需要考虑的因素很多,比如对现有业务的影响、网络带宽消耗以及超卖等因素。本文会讨论秒杀系统的各个环节可能存在的问题以及解决方案。
四大核心课题思考
一、JVM调优(调优原理,上线调优细节,掌握基本调优参数设置,调优一些经验),GC日志分析,进一步调优
二、数据库调优(连接池调优,数据库常见设计调优,缓存)
三、多级缓存优化(堆内缓存,分布式缓存,openresty内存字典, lua+redis实现接入层缓存)
四、秒杀下单(高并发模式下实现下单操作—满足业务需求)– Lock锁,AOP锁优化,分布式锁优化
高性能架构
以用户为中心,提供快速的网页访问体验。主要参数有较短的响应时间、较大的并发处理能力、较高的吞吐量与稳定的性能参数。
可分为前端优化、应用层优化、代码层优化与存储层优化。
· 前端优化:网站业务逻辑之前的部分;— vue ,react +nodejs – 工程化
· 浏览器优化:减少HTTP请求数,使用浏览器缓存,启用压缩,CSS JS位置,JS异步,减少Cookie传输;CDN加速,反向代理
· 应用层优化:处理网站业务的服务器。使用缓存,异步,集群,架构优化
· 代码优化:多线程,资源复用(对象池,线程池等),良好的数据结构,JVM调优,单例,Cache等
· 存储优化:缓存、固态硬盘、光纤传输、优化读写、磁盘冗余、分布式存储(HDFS)、NoSQL等
总结:
①服务尽量进行拆分(微服务)—- 提高项目吞吐能力
②尽量将请求拦截在上游服务(多级缓存)— 90% —-> 数据库压力非常小,闲庭信步,数据库架构(主从架构)
③代理层:做限速,限流
④服务层:按照业务请求做队列的流量控制(流量削峰)
可伸缩架构
伸缩性是指在不改变原有架构设计的基础上,通过添加/减少硬件(服务器)的方式,提高/降低系统的处理能力。
· 应用层:对应用进行垂直或水平切分。然后针对单一功能进行负载均衡(DNS、HTTP[反向代理]、IP、链路层)
· 服务层:与应用层类似
· 数据层:分库、分表、NoSQL等;常用算法Hash,一致性Hash
云原生:项目运行云端,可以随时动态扩容—K8S
8C+16G : 2000QPS +-
(此数字是估算结果,真实结果受到代码编写数据结构,业务逻辑,架构、rt,以现实测试结果)
可扩展架构
SOA — 微服务 — 业务拆分模块 — 新业务需求 — 根据新业务需求创建新模块服务
可以方便地进行功能模块的新增/移除,提供代码/模块级别良好的可扩展性。
· 模块化、组件化:高内聚,低耦合,提高复用性,扩展性
· 稳定接口:定义稳定的接口,在接口不变的情况下,内部结构可以“随意”变化
· 设计模式:应用面向对象思想,原则,使用设计模式,进行代码层面的设计
· 消息队列:模块化的系统,通过消息队列进行交互,使模块之间的依赖解耦
· 分布式服务:公用模块服务化,提供其他系统使用,提高可重用性,扩展性
安全架构
对已知问题有有效的解决方案,对未知/潜在问题建立发现和防御机制。对于安全问题,首先要提高安全意识,建立一个安全的有效机制,从政策层面,组织层面进行保障,比如服务器密码不能泄露,密码每月更新,每周安全扫描等。
以制度化的方式,加强安全体系的建设。同时,需要注意与安全有关的各个环节。安全问题不容忽视,包括基础设施安全,应用系统安全,数据保密安全等。
· 基础设施安全:
硬件采购,操作系统,网络环境方面的安全。一般采用正规渠道购买高质量的产品,选择安全的操作系统,及时修补漏洞,安装杀毒软件防火墙。防范病毒,后门。设置防火墙策略,建立DDOS防御系统,使用攻击检测系统,进行子网隔离等手段。
· 应用系统安全:
在程序开发时,对已知常用问题,使用正确的方式,在代码层面解决掉。防止跨站脚本攻击(XSS),注入攻击,跨站请求伪造(CSRF),错误信息,HTML注释,文件上传,路径遍历等。还可以使用Web应用防火墙(比如:ModSecurity),进行安全漏洞扫描等措施,加强应用级别的安全。
· 数据保密安全:
存储安全(存储在可靠的设备,实时,定时备份),保存安全(重要的信息加密保存,选择合适的人员复杂保存和检测等),传输安全(防止数据窃取和数据篡改)。
常用的加解密算法(单项散列加密[MD5、SHA],对称加密[DES、3DES、RC]),非对称加密[RSA]等。
一、互联网架构演进思考
1.1 架构演进
单体架构(all in one) à水平拆分/SOA架构à微服务架构 àkubernetes云原生架构(微服务迁移到云原生)à ServiceMesh (服务网格架构,下一代微服务架构,云原生架构:istio) à serverless 架构 (无服务架构)
企业架构转型:数字化转型
传统架构过渡到云原生架构(容器云)
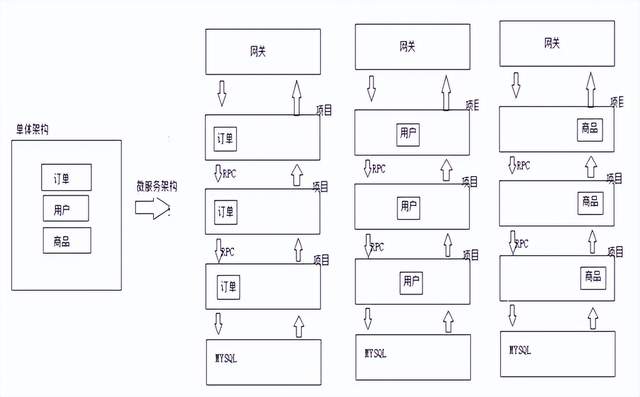
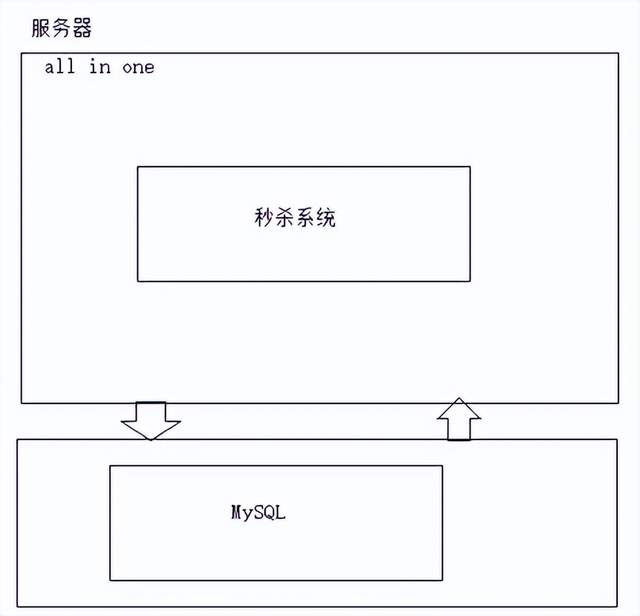
1.2 单体架构
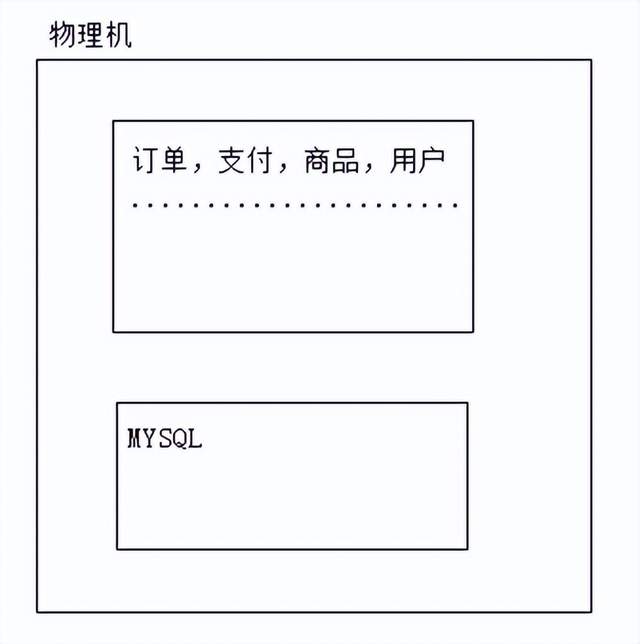
(1)单体架构——所有业务都在同一个应用中,没有进行任何拆分
注意:集中式架构模式,所有的请求都集中在同一个服务上面,对服务压力较大;因此这样的架构适合并发较小的架构;同时 同一个服务器中,数据库,项目都会抢占服务内存,cpu资源,造成服务性能问题;
(2)单体架构优化
· 应用程序 MYSQL分离部署
· 服务集群– 提升性能
· 动态分离(静态资源存储CDN,nginx服务器)
· 隔离术(线程池隔离,进程隔离)
· 队列术 (blockingQueue,disruptor队列,RocketMQ)
· 接入层限流(openresty), 接口限流
· MySQL优化(索引,缓存,表结构,分表分库,数据归档,冷热,SQL语句优化)
· 引入lvs (linux virtual server)
· DNS 解决上层流量瓶颈问题
· 多级缓存
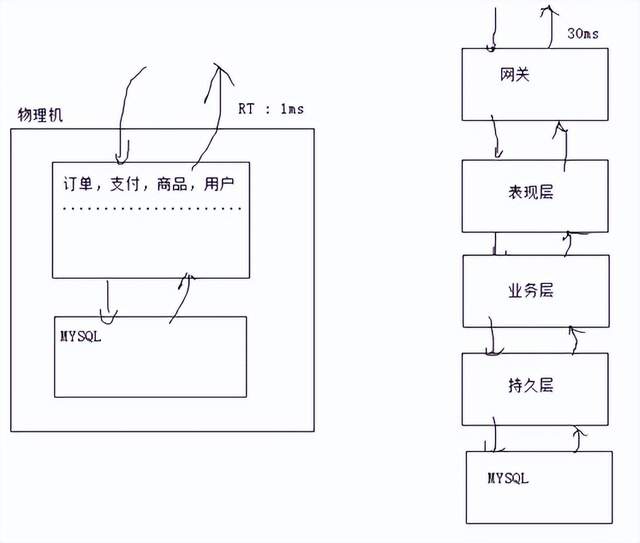
(3)单体架构流量预估(单体架构真的不能承受亿级流量??)
单体架构:中小型企业,创业公司
①传统项目(并发量小,业务简单,需求固定),项目体量比较小
②小程序
③追求极致性能的项目(业务量少)
④互联网项目(中小型企业,创业公司)
需求:
某网站平均一天下单量100w单,根据100w 评估一下系统的流量!!
用户行为:
①产生的时间段:11:00 – 2:00 5:00 – 12:00 ,订单产生时间段:12h
②每下一单会发生多少个请求:50QPS x 3 = 150 QPS
计算流量:
100w / day * 150 QPS = 1.5 亿 —– 亿级流量
计算平均每一秒QPS:
1.5亿/12 h = 1250 QPS / 60min = 20W / 60s = 3400 QPS
(4)单点架构优缺点
单体架构优点:
①部署简单
②开发简单
③测试简单
④集群简单
⑤RT响应时间非常快速 —— 适合一些特点的项目(极端苛刻响应时间)
单体架构问题:
①流量比较集中,所有的请求都集中一个服务中,单体无法应对
②无法实现敏捷开发,业务增大,代码结构越来越臃肿,维护变得非常困难单体架构:war > 1G — IBM unix 高性能服务器 64cpus, 128GB — 1GB
③单体架构牵一发而动全身
④扩展性差
⑤稳定性差
1.3 架构拆分
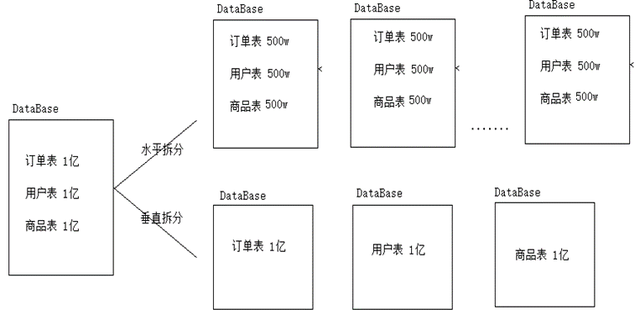
随着业务流量增大,需求的增多,必须对架构进行改进,就需要对项目进行业务拆分;(水平拆分,垂直拆分)
数据库水平拆分,垂直拆分模式:
(1)水平拆分模式
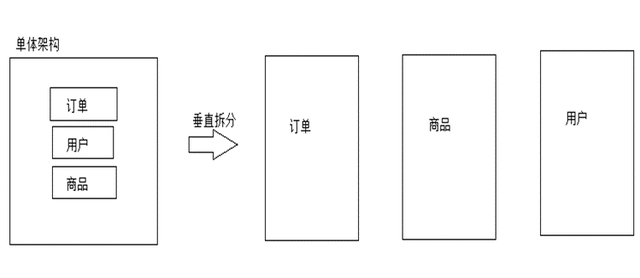
(2)垂直拆分:SOA架构
1.4 微服务架构
注意:微服务架构就是水平拆分和垂直拆分的架构结合,就是微服务架构;
1.5 ServiceMesh架构
ServiceMesh服务网格架构,CNCF把ServiceMesh定义为云原生架构,ServiceMesh落地级实现的成熟框架:Istio框架
问题:为什么要是有ServiceMesh架构??
Spring Cloud alibaba微服务架构存在问题??–ServiceMesh出现就是为了解决微服务架构中存在一些问题??
①服务性能监控(Zabbix,promutheus)2、服务限流(sentinel)
②服务降级(sentinel)
③服务熔断(sentinel)
④链路追踪(skywalking)
⑥日志监控(elk)
⑦服务告警
⑧负载均衡
以上一系列的问题,作为架构师,开发人员都需要全盘的考虑;开发微服务架构在服务治理,服务监控非常困难;
以上的工作和业务没有太多的关系,但是架构人员必须考虑,架构,设计,因此这些配套工作都会大大降低我们的开发效率,提升开发难度,增加开发成本;
1.6 Serverless
Serverless架构体系:无服务架构,面向未来的架构体系,从开发人员来说,不需要关心底层哪些和业务没有关系的代码,只需要开发业务即可;
例如:向CDN上传图片,视频文件;
①不需要上传到哪一个服务器
②不需要关心服务器是如何扩容的
这样的概念,思想就叫做Serverless;
总结:架构选型的时候,必须选择企业合适的架构,而不是采用最新架构;
二、性能调优思考-JVM
2.1 JVM的调优思考
思考题1
项目上线后,是什么原因促使必须进行jvm调优?
答案:调优的目的就是提升服务性能。
(1)jvm 堆内存空间对象太多(Java线程,垃圾对象),导致内存被占满,程序跑不动—性能严重下降
调优:及时释放内存
(2)垃圾回收线程太多,频繁回收垃圾(垃圾回收线程也会占用内存资源,抢占cpu资源),必然会导致程序性能下降;
调优:防止频繁gc
(3)垃圾回收导致stw(stop the world)
调优:尽可能的减少gc次数
思考题2
jvm调优本质是什么?
答案:jvm调优的本质就是(对内存的调优) 及时回收垃圾对象,释放内存空间;让程序性能得以提升,让其他业务线程可以获得更多内存空间;
思考题3
是否可以把JVM内存空设置的足够大(无限大),是不是就不需要垃圾回收呢?
前提条件:内存空间被装满了以后,才会触发垃圾回收器来回收垃圾;
答案:理论上是的,现实情况不行的!
寻址能力:
(是否有这么大的空间)
32位操作系统 === 4GB 内存
64位操作系统 === 16384 PB 内存空间
Jvm堆内存空间大小的设置:
必须设置一个合适的内存空间,不能太大,也不能太小
· 问题1:考虑到寻址速度的问题,寻址一个对象消耗的时间比较长的
· 问题2:一旦触发垃圾回收,将会是一个灾难;(只能重启服务器)
2.2 JVM的调优原则
(1) gc的时间足够小(堆内存设置足够小)
垃圾回收时间足够小,以为着jvm堆内存空间设置小一些,这样的话 垃圾对象寻址的时候消耗的时间就非常短,然后整个垃圾回收非常快速;
(2) gc的次数足够少 (jvm堆内存设置的足够大)
Gc次数足够少,jvm堆内存空间必须设置的足够大;这样垃圾回收触发次数就会相应减少;
注意:原子1 ,原则2 相互冲突的,原则1&&原则2 ,需要进行balance,内存空间既不能设置太大,也不能设置太小;
(3) 发生fullgc 周期足够长 (最好不发生full gc)
· metaspace 永久代空间设置大小合理,metaspace一旦扩容,就会发生fullgc
· 老年代空间设置一个合理的大小,防止full gc
· 尽量让垃圾对象在年轻代被回收(90%)
· 尽量防止大对象的产生,一旦大对象多了以后,就可能发生full gc ,甚至oom
2.3 JVM的调优原理
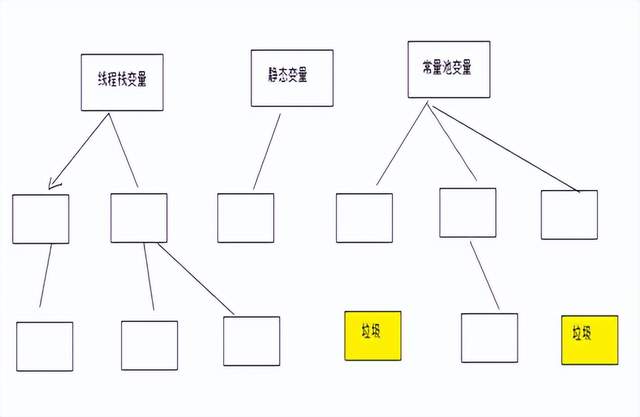
什么是垃圾?
JVM调优的本质:回收垃圾,及时释放内存空间;
但是什么是垃圾?
在内存中间中,哪些没有被引用的对象就是垃圾(高并发模式下,大量的请求在内存空间中创建了大量的对象,这些对象并不会主动消失,因此必须进行垃圾回收,当然Java垃圾回收必须我们自己编写垃圾回收代码,Java提供各种垃圾回收器帮助回收垃圾,JVM垃圾回收是自动进行的)
一个对象的引用消失了,这个对象就是垃圾,因此此对象就必须被垃圾回收器进行回收,及时释放内存空间;
怎么找垃圾?
Jvm提供了2种方式找到这个垃圾对象:
(1)引用计数算法 找垃圾
(2)根可达算法 找垃圾 hotspot 垃圾回收器都是使用这个算法
(1)引用计数算法
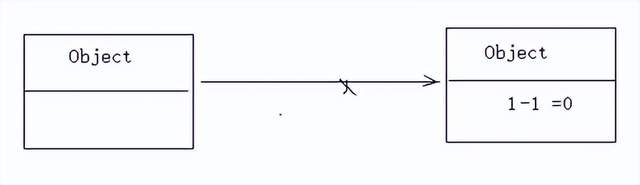
引用计数算法:对每一个对象的引用数量进行一个计数,当引用数为0时,那么此对象就变成了一个垃圾对象;
存在问题:不能解决循环引用的问题,如果存在循环引用的话,无法发现垃圾
这三个对象处于循环引用的状态,引用计数都不为0,因此无法判断这个3个对象是垃圾;
(2)根可达算法
根据根对象向下进行遍历,如果遍历不到的对象就是垃圾。
如何清除垃圾?
JVM提供了3种方式清除垃圾,分别是:
①mark-sweep 标记清楚算法
②copying 拷贝算法
③mark-compact 标记整理(压缩)算法
①第一种算法:mark-sweep 标记清楚算法
①使用根可达算法找到垃圾对象,对垃圾对象进标记 (做一个标记)
②对标记对象进行删除(清除)
优点:简单,高效
缺点:清除的对象都不是一个连续的空间,清除垃圾后,产生很多内存碎片;不利于后期对象内存分配,及寻址;
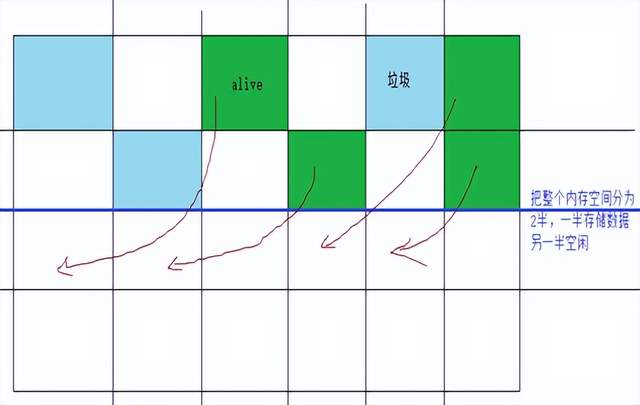
②第二种算法:copying拷贝算法
一开始就把内存控制一份为2,分为2个大小相同的的内存空间,另一半空间展示空闲:
①选择(寻址)存活对象
②把存活对象拷贝到另一半空闲空间中,且是连续的内存空间
③把存储对象拷贝结束后,另一半空间中全是垃圾,直接清除另一半空间即可
优点:简单,内存空间是连续的,不存在内存空间碎片
缺点:内存空间浪费
③第三种算法:mark-compact标记整理(压缩)算法
①选择(寻址)存活对象
②把存活对象拷贝到另一半空闲空间中,且是连续的内存空间
③把存储对象拷贝结束后,另一半空间中全是垃圾,直接清除另一半空间即可
垃圾回收器
Java提供很多的垃圾回收器:10种垃圾回收器;
特点:
1、Serial Serial Old , parNew CMS , Parallel Scavenge Parallel Old 都属于物理分代垃圾回收器;年轻代,老年代分别使用不同的垃圾回收器;
2、G1 在逻辑上进行分代的,进行在使用上非常方便,关于年轻代,老年代只需要使用一个垃圾回收器即可;
3、ZGC ZGC是一款JDK 11中新加入的具有实验性质的低延迟垃圾收集器
4、Shenandoah OpenJDK 垃圾回收器
5、Epsilon 是Debug使用的,调试环境下:验证jvm内存参数设置的可行性
6、Serial Serial Old:串行化的垃圾回收器
7、parNew CMS :并行,并发的垃圾回收器
8、Parallel Scavenge Parallel Old :并行的垃圾回收器
常用的垃圾回收器组合:
1、Serial + Serial Old: 串行化的垃圾回收器,适合单核心的cpu的服务情况
2、parNew + CMS:响应时间优先组合
3、Parallel Scavenge + Parallel Old :吞吐量优先组合
4、g1 :逻辑上分代的垃圾回收器组合
2.4 垃圾回收器原理
Serial+Serial Old
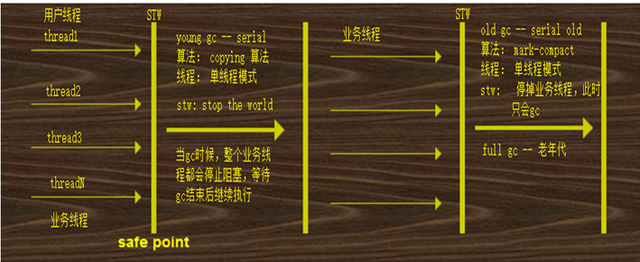
Serial :
年轻代的垃圾回收器,单线程的垃圾回收器;Serial Old是老年代的垃圾回收器,也是一个单线程的垃圾回收器,合适单核心cpu;
注意特点:
1、stw : 当进行gc的时候,整个业务线程都会被停止,如果stw时间过长,或者stw发生次数过多,都会影响程序的性能
2、垃圾回收器线程:多线程,单线程,并发,并行
Parallel Scavenge + Parallel Old
Parallel Scavenge + Parallel Old :
并行的垃圾回收器;吞吐量优先的垃圾回收器组合,是JDK8默认的垃圾回收器;
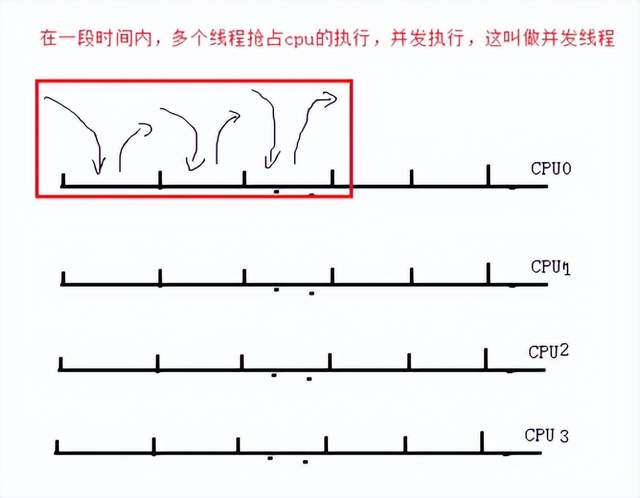
问题 : 什么是并发,并行?
并发:
并行:
PS + PO 回收垃圾的时候,采用的多线程模式回收垃圾。
注意特点:
1、stw : 当进行gc的时候,整个业务线程都会被停止,如果stw时间过长,或者stw发生次数过多,都会影响程序的性能
2、垃圾回收器线程:多线程,单线程,并发,并行
parNew+CMS
parNew : 并行垃圾回收器,年轻代的垃圾回收器
CMS : 并发垃圾回收器,回收老年代的垃圾
年轻代垃圾回收器:parNew:
老年代垃圾回收器:CMS
注意:
任何的垃圾回收器都无法避免 STW ,因此jvm调优实际上就是调整stw的时间;
G1
使用G1收集器时,它将整个Java堆划分成约2048个大小相同的独立Region块,每个Region块大小根据堆空间的实际大小
而定,整体被控制 在1MB到32MB之间,且为2的N次幂,即1MB,2MB,4MB,8MB,16MB,32MB。可以通过-XX:G1HeapRegionsize设定。
所有的Region大小相同,且在JVM生命周期内不会被改变;
2.5 内存分代模型
通过内存分代模型结构:大多数对象都会在年轻代被回收掉(90%+),很多对象都在15次的垃圾回收中被回收掉了,只有超过15次还没被回收掉的才会进入到老年代区域;
垃圾回收触发时机:
1、ps+po : 当堆内存被装满了,才会触发垃圾回收(eden区域满了,触发了垃圾回收,old区域满了,触发垃圾回收)
2、cms 垃圾回收器
①JDK1.5:68% ,当eden区域装对象达到68%时候,就会触发垃圾回收
②JDK1.6+ : 92%才会触发垃圾回收器
一个新对象被创建了,但是这个对象是一个大对象(查询全表),eden区域已经放不下了,此时会发生什么?
2.6 JVM的实战调优
明确:jvm调优本质
1、JVM调优本质就是 gc , 垃圾回收,及时释放内存空间
2、gc次数要少,gc时间少,防止fulllgc — 内存参数设置
典型参数设置
服务器硬件配置:4cpu,8GB内存 — jvm调优内存,考虑内存
1、-Xmx4000m 设置JVM最大堆内存(经验值:3500m – 4000m,内存设置大小,没有一个固定的值,根据业务实际情况来进行设置的,根据压力测试,根据性能反馈情况,去做参数调试)
2、-Xms4000m 设置JVM堆内存初始化的值,一般情况下,初始化的值和最大堆内存值必须一致,防止内存抖动;
3、-Xmn2g 设置年轻代内存对象(eden,s1,s2)
4、-Xss256k 设置线程栈大小,JDK1.5+版本线程栈默认是1MB, 相同的内存情况下,线程堆栈越小,操作系统创建的线程越多;
nohup java -Xmx4000m -Xms4000m -Xmn2g -Xss256k -jar jshop-web-1.0-SNAPSHOT.jar –spring.config.addition-location=application.yaml > jshop.log 2>&1 &
压力测试:查看在此内存设置模式下性能情况:
根据压力测试结果,发现JVM参数设置,和之前没有设置吞吐能力没有太大的变化,因为测试样本不足以造成 gc,fullgc时间上差异;
问题:根据什么标准判断参数设置是否合理呢??根据什么指标进行调优呢?
1、发生几次gc, 是否频繁的发送gc?
2、是否发生fullgc ,full gc发生是否合理
3、gc的时间是否合理
4、oom
2.7 GC的日志输出
输出日志启动指令如下所示:
nohup java -Xmx4000m -Xms4000m -Xmn2g -Xss256k -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar –spring.config.addition-location=application.yaml > jshop.log 2>&1 &
输出日志指令:
-XX:+PrintGCDetails 打印GC详细信息
-XX:+PrintGCTimeStamps 打印GC时间信息
-XX:+PrintGCDateStamps 打印GC日期的信息
-XX:+PrintHeapAtGC 打印GC堆内存信息
-Xloggc:gc.log 把gc信息输出gc.log文件中执行启动指令后,在本地产生gc.log文件:
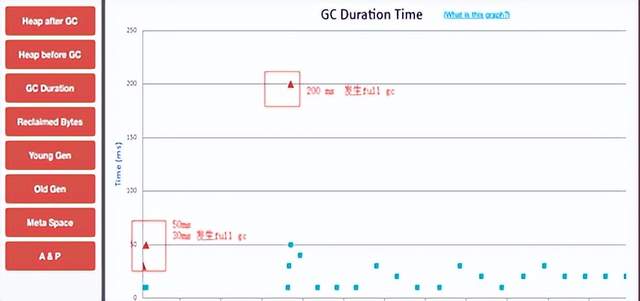
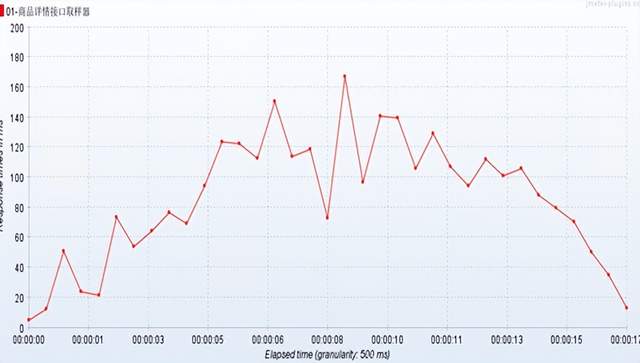
GC日志分析: 使用https://gceasy.io/导入gc.log 进行在线分析即可;
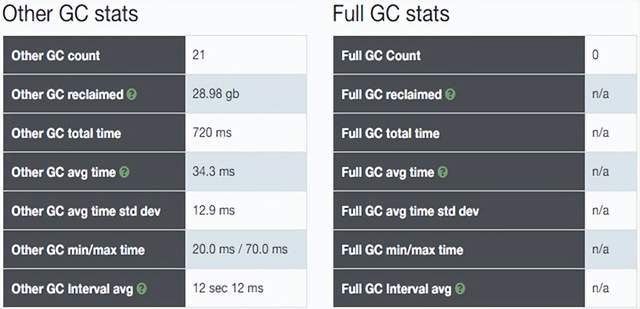
Gc日志分析报告:
总结:可以发现 业务线程执行时间占比达到99%+,说明gc时间在整个业务执行期间所占用的时间非常少,几乎不会影响程序性能;导致业务线程执行时间占比高的原因是:
1、程序样本数不够
2、程序运行的时间不够
3、业务场景不符合要求(查询没有太多的对象数据)
存在问题:发生full gc
GC详细数据分析:
fullgc频繁发生:
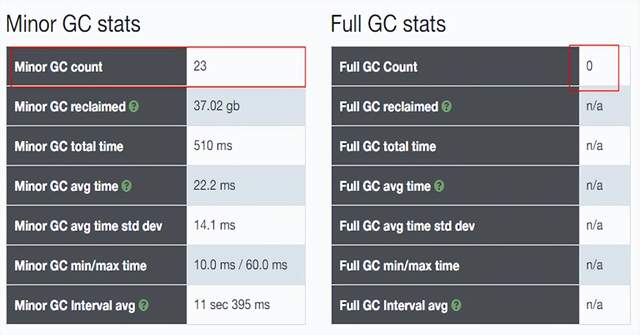
查询gc内存模型:jstat -gcutil PID 查询此进程的内存模型;
Metaspace永久代空间:默认为20m(初始化大小);当metaspace被占满后,就会发生扩容,一旦metaspace发生一次扩容,就会同时发送一次fullgc ;
Sun公司推荐设置:年轻代占整个堆内存 3/8
发现full gc 已经没有发生了;
Yong &old比例
Sun公司推荐设置:整个堆的大小=年轻代 + 老年代 + 永久代(256m)
年轻代占整个堆内存3/8 , -Xmx4000m , 因此整个堆内存设置大小为4000m,也就是说年轻代大小应该设置为1.5G:
①定义年轻代:-Xmn1500m,剩下的空间就是老年代的空间
②参数:-XX:NewRatio = 4 表示年轻代(eden ,s0,s1) 和老年代区域所占比值 1:4
年轻代大小,老年代大小比值根据业务实际情况设置比例,(通过设置相应的比例:减少相应yonggc ,fullgc);
JVM调优的原则中:要求尽量防止fullgc的发生;因此可以把fullgc设置的稍微大一些;以为old区域装载对象很长时间才能装满(或者永远都装不满),发生fullgc概率就非常小;
Eden&s0&s1
官方给定设置:可以设置eden,s区域大小:8:1:1 à -XX:SurvivorRatio = 8
此调优的原理:尽量让对象在年轻代被回收;调大了eden区域的空间,让更多对象进入到eden区域,触发gc时候,更多的对象被回收;
nohup java -Xmx4000m -Xms4000m -Xmn1500m -Xss256k -XX:MetaspaceSize=256m -XX:SurvivorRatio=8 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar –spring.config.addition-location=application.yaml > jshop.log 2>&1 &
可以发现业务占比时间发送提升,说明gc时间更少了;
总结:JVM调优(调整内存大小、比例) 降低 gc次数,减少gc时间,从而提升服务性能;
调优标准:项目上线后,遇到问题,调优
1、gc消耗时间 –业务时间占比
2、频繁发生fullgc – 调优 – stw—程序暂停时间比较长,阻塞,导致整个程序崩溃
3、oom — 调优
2.8 GC组合
吞吐量优先
并行的垃圾回收器:parallel scavenge(年轻代) + parallel old(老年代) —- 是JDK默认的垃圾回收器
nohup java -Xmx4000m -Xms4000m -Xmn1500m -Xss256k -XX:MetaspaceSize=256m -XX:SurvivorRatio=8 -XX:+UseParallelGC -XX:+UseParallelOldGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar –spring.config.addition-location=application.yaml > jshop.log 2>&1 &
显式的配置PS+PO垃圾回收器:-XX:+UseParallelGC -XX:+UseParallelOldGC
响应时间优先
并行垃圾回收器(年轻代),并发垃圾回收器(老年代) :ParNew + CMS (响应时间优先垃圾回收器)
nohup java -Xmx4000m -Xms4000m -Xmn1500m -Xss256k -XX:MetaspaceSize=256m -XX:SurvivorRatio=8 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar –spring.config.addition-location=application.yaml > jshop.log 2>&1 &
显式配置:parNew+CMS垃圾回收器组合:-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
说明:CMS只有再发生fullgc的时候才起到作用,CMS一般情况下不会发生;因此在jvm调优原则中表示尽量防止发生fullgc; 因此CMS在JDK14被已经被废弃;
G1垃圾回收器是逻辑上分代模型,使用配置简单;
nohup java -Xmx4000m -Xms4000m -Xmn1500m -Xss256k -XX:MetaspaceSize=256m -XX:SurvivorRatio=8 -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop-web-1.0-SNAPSHOT.jar –spring.config.addition-location=application.yaml > jshop.log 2>&1 &
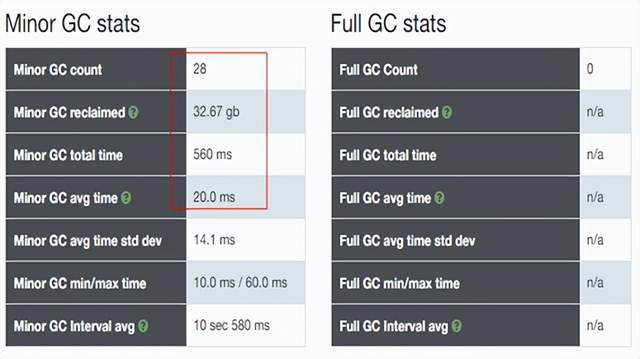
经过测试,发现g1 gc次数减少,由原来的28次减少为21次,但是gc总时长增加很多;时间增加,以为着服务性能就没有提升上去;
三、数据库连接池调优思考
3.1 数据库调优动机何在
1、避免网页出现错误
· Timeout 5xx 错误
· 慢查询导致页面无法加载
· 阻塞导致数据无法提交
2、增加数据库稳定性
很多的数据库问题,都是由于低效的SQL语句造成的(写SQL语句)
3、优化用户体验
· 流畅的业务访问体验
· 良好的网站功能体验
3.2 影响数据库性能的因素
1、低效的SQL语句
2、并发cpu问题(SQL语句不支持多核心的cpu并发计算,也就是说一个SQL只能在一个cpu执行结束)3、连接数:max_connections
4、超高cpu使用率
5、磁盘io性能问题6、大表(字段多,数据多)
7、大事务
数据库数据处理(困难):数据库扩容非常困难—想要通过扩容提升数据库性能
Web服务器扩容是非常简单的,web服务器是无状态服务,可以随时进行扩容;但是数据库不能随意进行扩容,一旦扩容就会影响数据完整性,数据一致性;
项目架构中提升性能:
1、对项目架构、业务,缓存各方面进行优化,真正数据库请求比较少—减少数据库压力
2、数据库设计,架构,优化
大多数企业:数据库采用主从架构解决问题;数据分表,分库,数据归档数据,能热分离
3.3 连接池对性能样例分析(详细IP隐藏)
datasource:
#url: jdbc:mysql://127.0.0.1:3306/shop?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
url: jdbc:mysql://XX.XX.XX.XX:3306/shop?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true&connectionTimeout=3000&socketTimeout=1200
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
druid:
#配置初始化大小、最小、最大
initial-size: 1
min-idle: 5
max-active:10
max-wait: 10000
time-between-eviction-runs-millis: 600000
# 配置一个连接在池中最大空闲时间,单位是毫秒
min-evictable-idle-time-millis:300000
# 设置从连接池获取连接时是否检查连接有效性,true时,每次都检查;false时,不检查
test-on-borrow: true
#设置往连接池归还连接时是否检查连接有效性,true时,每次都检查;false时,不检查
test-on-return: true
# 设置从连接池获取连接时是否检查连接有效性,true时,如果连接空闲时间超过minEvictableIdleTimeMillis进行检查,否则不检查;false时,不检查
test-while-idle: true
# 检验连接是否有效的查询语句。如果数据库Driver支持ping()方法,则优先使用ping()方法进行检查,否则使用validationQuery查询进行检查。(Oracle jdbc Driver目前不支持ping方法)
validation-query: select 1 from dual
keep-alive: true
remove-abandoned: true
remove-abandoned-timeout: 80
log-abandoned: true
#打开PSCache,并且指定每个连接上PSCache的大小,Oracle等支持游标的数据库,打开此开关,会以数量级提升性能,具体查阅PSCache相关资料
pool-prepared-statements:true
max-pool-prepared-statement-per-connection-size:20
# 配置间隔多久启动一次DestroyThread,对连接池内的连接才进行一次检测,单位是毫秒。
#检测时:
#1.如果连接空闲并且超过minIdle以外的连接,如果空闲时间超过minEvictableIdleTimeMillis设置的值则直接物理关闭。
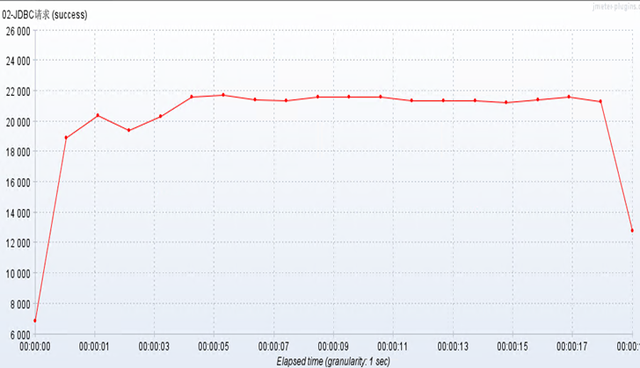
#2.在minIdle以内的不处理。试验:10 connections , 40w个样本进行测 ,TPS = 22000 TPS
经过测试:connection=20, connection=50都进行了测试,发现当connection=20的时候,性能已经下降了,此时TPS=18000 TPS, 当connection=50的时候,TPS = 12000 TPS
经过测试:连接池最合理的连接数量设置:[10-15]
connectionTimeout : 配置建立TCP连接的超时时间 ,客户端和mysql建立连接超时,断开连接(释放连接)
sockettimeout: 配置发送请求后等待响应的超时时间;(客户端和mysql建立连接是socket连接, 一旦发送网络异常,客户端无法感知,一直阻塞状态,一直等待服务端给相应结果,其实由于网络异常,这个链接变成死链接)
# 单位是ms
jdbc:mysql://XX.XX.XX.XX:3306/shop?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
&connectionTimeout=3000&socketTimeout=12003.4 分布式部署
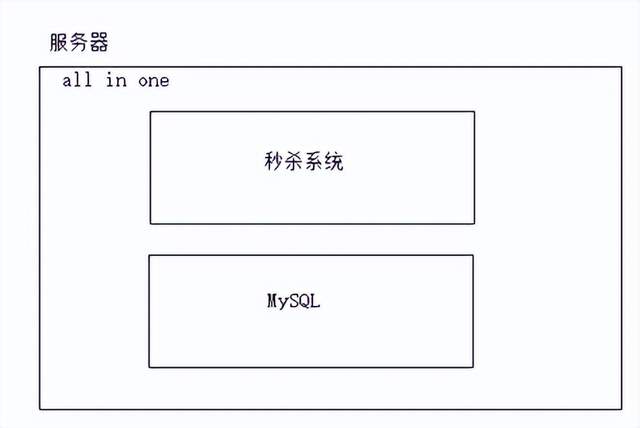
单体架构
秒杀系统,mysql都会抢占同一个服务器cpu资源,内存资源;一旦cpu资源,内存资源出现满负荷状态,就会影响服务性能;
分离部署
通过分离部署后,发现性能提升非常不明显,因为无论是在单机,还是在分布式情况下,机器性能都不是满负荷运作的情况;
分布式部署
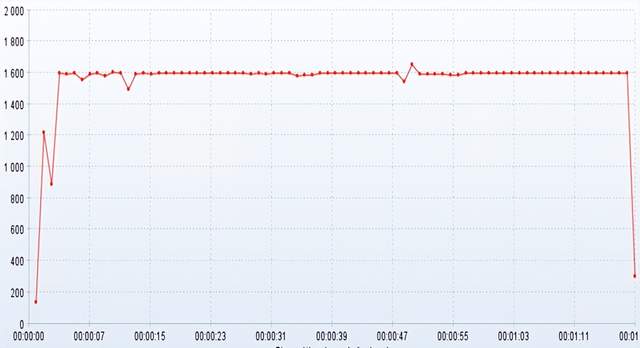
从上往下看:openresty是否会存在性能瓶颈,目前来看性能瓶颈不在openresty, 因为openresty(nginx) 底层使用c语言开发的,吞吐能力5w TPS;
性能瓶颈一定出现在项目,数据库这个位置;
项目优化:扩容,缓存
数据库优化:扩容,数据库其他优化
此时此刻对这个架构进行TPS 预测:TPS = 1600
四、多级缓存思考
主要内容:多级缓存(堆内缓存,分布式缓存,接入层缓存,lua+redis缓存)
4.1 多级缓存
在系统架构设计中,多级缓存非常重要,尤其是构建亿级流量的系统,缓存是必不可少优化选项;因此缓存可以成倍的提升系统性能(吞吐能力),使用了缓存后,尽可能把请求拦截在上游服务器(缓存中:缓存数据命中,直接返回,不在访问后端服务器),因此下游服务器来说,压力就会变小;
在系统架构中应该使用那些缓存:
1、 浏览器缓存
2、 CDN缓存(静态资源:js,css,视频,文件)
3、 接入层nginx/openresty缓存
4、 堆内存缓存(jvm进程级别的缓存)
5、分布式缓存(redis,memcached)
6、数据库缓存(压力非常小)
4.2 缓存架构
在本系统中实现缓存是:
1、堆内存缓存
2、redis分布式缓存
3、openresty内存字典(lua)
4、lua+redis
思考:JVM进程级别的缓存(缓存数据放入jvm堆内存中),存在以下问题?
1、jvm堆内存资源非常宝贵(classloader文件,java对象,对象管理),改如何考量?
2、内存脏数据非常的不敏感(Map: key,value)
3、内存资源分配不可控
答案:
问题1:内存资源非常宝贵,不能放入太多缓存数据,只需要放入热点数据即可,提升服务性能
问题2:定时消耗内存对象数据(定时器),数据有过期时间(定时销毁)–相当麻烦 — GuavaCache
问题3:不可能把所有的资源都放入内存中,只放入热点数据即可
分布式缓存:Redis — AP模型,在海量的缓存数据中,存储一定概率的数据丢失;
接入层缓存:openresty+lua
4.3 本地缓存+分布式缓存
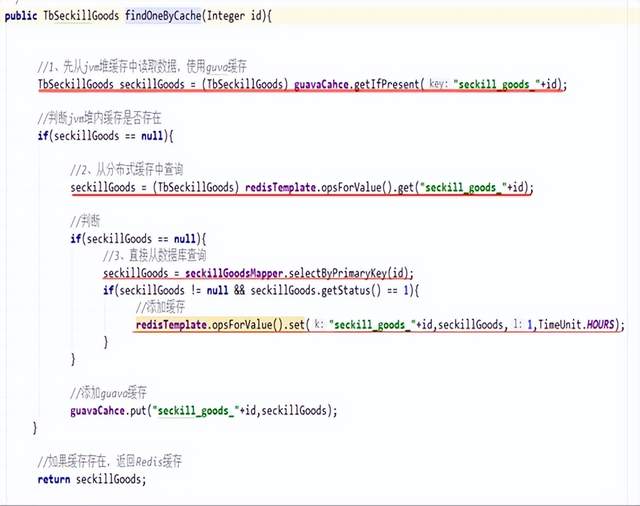
创建一个guavaCache对象:把对象交给spring管理
缓存业务实现:
1、先从jvm堆内存中命中(查询)缓存数据
2、如果缓存不存在,查询redis分布式缓存,如果命中,直接返回数据,放入本地缓存
3、如果分布式缓存也没有数据,查询数据库,同时把数据放入redis缓存
二级缓存(堆内存缓存,redis缓存):对于系统来说性能提升情况如何?
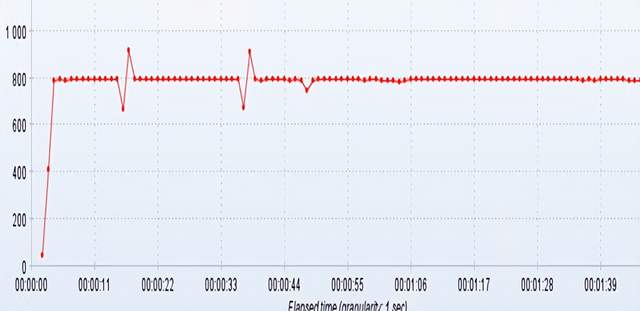
根据压力测试结果显示:TPS吞吐能力提升效果相当显著;
没有缓存:TPS = 800 , 加缓存:TPS = 26000
RT响应时间:100ms左右,基本上满足接口性能需求
4.4 Openresty内存字典
本小节中,探索openresty接入层缓存,使用openresty内存字典来实现接入层缓存;如果缓存数据在接入层命中,后端服务器就不会再收到请求了;
问题
什么样的缓存,性能最好的?— 离请求越近的地方,缓存数据性能越好,以为系统性能越强;
1、openresty接入lua脚本
# 安装openresty:
1、wget https://openresty.org/download/openresty-1.19.3.1.tar.gz
2、tar -zxvf
3、./configure
4、make && make install # 默认被安装到/usr/local/openresty
# content_by_lua 接入lua脚本
location /lua1 {
default_type text/html;
content_by_lua ‘ngx.say(“hello lua!!”)’;
}
# content_by_lua_file 通过文件的方式引入lua脚本
location /lua2 {
default_type text/html;
content_by_lua_file lua/test.lua; # test.java ,test.py
}
# test.lua
local args = ngx.req.get_uri_args() # 获取参数对象
ngx.say(“hello openresty! lua is so easy!===”..args.id) # 获取参数值,组装值:..
# 转发请求
location /lua3 {
content_by_lua_file lua/details.lua;
}
# details.lua
ngx.exec(‘/seckill/goods/detail/1’); # 转发请求lua接入指令:https://www.nginx.com/resources/wiki/modules/lua/#directives
2、内存字典缓存实现方案
(1)开启openresty内存字典
lua_shared_dict ngx_cache 128m; # 在openresty服务器开辟一块128m空间存储缓存数据
(2)lua脚本方式,实现缓存接入
— 基于内存字典实现缓存
— 添加缓存实现
function set_to_cache(key,value,expritime)
— 判断时间是否存在
if not expritime then
expritime = 0
end
— 获取本地内存字典对象
local ngx_cache = ngx.shared.ngx_cache
— 向本地内存字典添加缓存数据
local succ,err,forcibel = ngx_cache:set(key,vlaue,expritime)
return succ
end
— 获取缓存实现
function get_from_cache(key)
— 获取本地内存字典对象
local ngx_cache = ngx.shared.ngx_cache
— 从本地内存字典中获取数据
local value = ngx_cache:get(key)
return value
end
— 利用lua脚本实现一些简单业务
— 获取请求参数对象
local params = ngx.req.get_uri_args()
— 获取参数
local id = params.id
— 先从内存字典获取缓存数据
local goods = get_from_cache(“seckill_goods_”..id)
— 如果内存字典中没有缓存数据
if goods == nil then
— 从后端服务(缓存,数据库)查询数据,完毕在放入内存字典缓存即可
local res = ngx.location.capture(“/seckill/goods/detail/”..id)
— 获取查询结果
goods = res.body
— 向本地内存字典添加缓存数据
set_to_cache(“seckill_goods_”..id,goods,60)
end
— 返回结果
ngx.say(goods)经过内存字典缓存的部署后,发现TPS = 55000
RT响应时间也是非常之快速。
4.5 Lua+redis
Openresty内部集成的lua(lua是一个脚本语言,lua+openresty(集成luaJIT)实现lua脚本解释执行),缓存架构如下所示:
说明:使用lua+redis缓存结构,尽可能把请求拦截在上游服务器,减轻后端服务器压力,提升项目吞吐能力;
Lua脚本:mysql,redis, mongdb, es ……. , 说明可以直接使用lua+openresty构建高并发性能的网站;
OpenResty集成Redis库:使用lua脚本操作Redis,只需要引入Redis库即可实现:
如何使用redis库文件:lua脚本中引入lua库,即可使用lua库中函数方法
开发:lua+redis缓存实现:
总结:之前经过服务器优化实现,jvm优化实现,数据库连接池优化实现,多级缓存优化,部署拓扑结构变化对性能影响—压力测试验证优化结果;— 这些优化操作都是对读操作进行的优化;
系统中:写操作进行优化 — 具体涉及到的业务:下单实现
五、秒杀下单业务分析(AOP锁&分布式锁)
秒杀下单业务分析(业务问题,性能,一致性问题)
解决下单操作业务问题(锁—锁优化)
5.1秒杀业务实现
前提:一系列的验证(身份信息,token,手机号,商品信息是否上架,是否是秒杀商品,商品状态,库存是否ok,活动是否开始…..)
1、检查库存是否存在
2、扣减库存
3、更新库存
4、下单实现
秒杀实现,业务上是非常之简单的,但是在高并发压力下,也面临一系列的挑战
1、如何在高并发情况下,保证库存不会出现超卖现象
2、如果在高并发模式下,解决下单性能问题
3、如果在高并发模式下,保证数据一致性问题
5.2 防止超卖问题
思考题:超卖产生的原因是什么?
请提出
解决方案,如何避免超卖现象的发生呢?
答案:
1、对共享资源(库存)加锁
2、Redis原子操作特性
3、队列 (利用队列的单线程特性)
1、加锁(对象共享资源库存加锁,让共享资源被多个线程互斥访问)
加锁目的:防止多个线程对共享资源的并发修改;一旦加锁,多个线程就进行排队执行,因此在高并发模式,这样的操作是一个灾难;明确:任何的加锁动作,都会导致性能急剧下降;
2、Redis原子特性(Redis单线程服务器,利用单线程的特性)
①扣减库存:hincrement(“seckill_goods_stock_1”,-1) ; 此操作是一个原子操作 — 多个线程也是要排队
②判断库存是否存在说明:以上操作既解决性能问题,又解决库存超卖的问题
3、队列的方式 (Redis队列)
队列的特点:
①队列的长度等于商品个数(pod一个队列,相当于扣减了一个库存,且队列操作是一个原子操作)
②队列中存储的数据是对应商品的ID值
③每一个商品都对应一个队列
5.3超卖问题处理
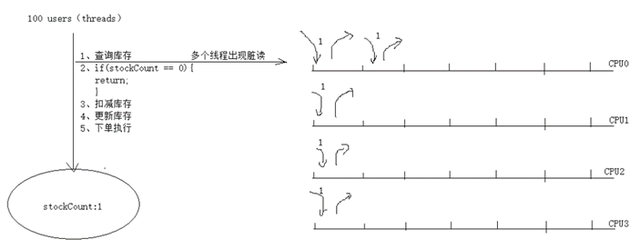
单机锁Lock
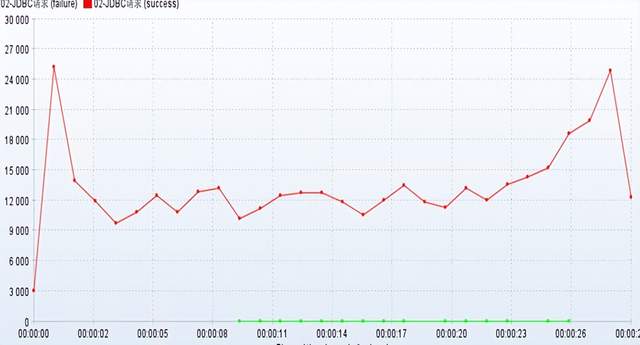
对普通下单:没有上锁的操作,验证库存超卖的现象;超卖现象非常严重,1000个库存,超卖了843个库存。
因此现在加锁:控制共享资源库存防止并发修改。
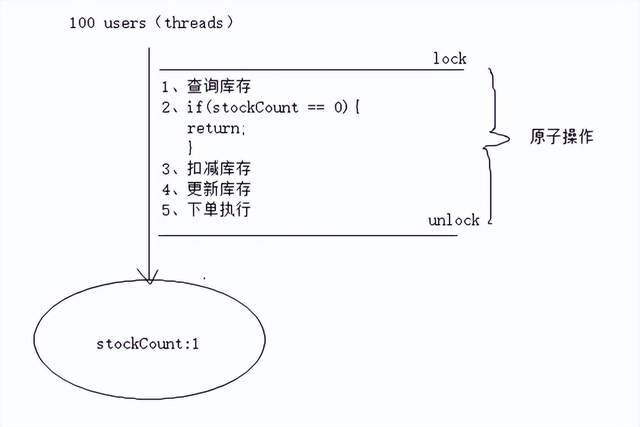
@Transactional @Override public HttpResult startKilled(Long killId, String userId) { try { //实现一个加锁的动作 lock.lock(); // do your business } catch (Exception e) { e.printStackTrace(); }finally { lock.unlock(); } return null; }以上加锁操作无法控制库存, 原因是什么?
经过验证,发现加lock锁,没有控制住库存;
出现以上的原因:锁和事务冲突;导致此时这个锁根本不起作用;
问题:事务何时提交的?
问题:针对于以上问题(锁事务冲突的问题),你的解决方案是什么?
解决方案:锁上移 (表现层,AOP锁(√))
AOP锁实现:
/** * @ClassName ServiceLock * @Description * @Author Ylc * @Date 2022/5/28 23:12 * @Version V1.0 **/ @Target({ElementType.PARAMETER,ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface ServiceLock { String descripiton() default ""; } /** * @ClassName LockAspect * @Description * @Author ylc * @Date 2022/5/28 23:13 * @Version V1.0 **/ @Component @Scope @Aspect @Order(1) public class LockAspect { // 定义锁对象 private static Lock lock = new ReentrantLock(true); // service 切入点 @Pointcut("@annotation(com.sugo.seckill.aop.ServiceLock)") public void lockAspect(){ } @Around("lockAspect()") public Object around(ProceedingJoinPoint joinPoint){ Object obj = null; // 开始加锁-- 方法增强 lock.lock(); try { //执行业务 obj = joinPoint.proceed(); } catch (Throwable throwable) { throwable.printStackTrace(); }finally { // 释放锁 lock.unlock(); } return obj; } }使用1000个样本经过多次测试,发现库存都可以进行完美的控制,因此aop锁可以实现库存控制的,不会出现超卖的问题。
总结
原则上,构建完整一个系统,整体思路上还需考虑压力测试、分布式环境下数据一致性、接口幂等性问题,在此就不赘述。
实现压力测试(及时发现系统的问题,发现系统性能瓶颈),根据压力测试结果对系统进行优化,问题修复,压力测试验证性能是否有提升;服务端优化(tomcat服务器优化,undertow服务器优化),压力测试验证性能提升结果。
另外涉及Kubernetes原生迁移也是一项架构师领域考虑的问题。甚至全局规划人力成本这一计算很复杂的课题,会涉及时间成本、代码量成本、需求管理成本等各类成本。
随着云技术的快速迭代,完成对上述多领域新旧技术的综合架构衡量,对于非互联网企业内部IT团队技能储备已构成不小的挑战,作为云和安全服务商,新钛云服致力于提供一站式二线专家咨询支持到实施部署及代运维。
*部分资料参考:中国信通院、https://gceasy.io/、https://redis.io/、https://openresty.org/、https://www.nginx.com
云和安全管理服务商