
-
Ceph万字总结|如何改善存储性能以及提升存储稳定性

「Ceph – 简介」
Ceph是一个即让人印象深刻又让人畏惧的开源存储产品。通过本文,用户能确定Ceph是否满足自身的应用需求。在本文中,我们将深入研究Ceph的起源,研究其功能和基础技术,并讨论一些通用的部署方案和优化与性能增强方案。同时本文也提供了一些故障场景以及对应的解决思路。背景
Ceph是一个开源的分布式存储解决方案,具有极大的灵活性和适应性。Ceph项目最早起源于Sage就读博士期间的论文(最早的成果于2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。Ceph在2014年被RedHat收购后,一直由RedHat负责维护。Ceph的命名和UCSC(Ceph的诞生地)的吉祥物有关,这个吉祥物是 “Sammy”,一个香蕉色的蛞蝓,就是头足类中无壳的软体动物。这些有多触角的头足类动物,是对一个分布式文件系统高度并行的形象比喻。自从2012年7月3日发布第一个版本的Argonaut以来,随着新技术的整合,Ceph经历了几次开发迭代。借助适用于Openstack和Proxmox的虚拟化平台,Ceph可支持直接将iSCSI存储呈现给虚拟化平台。同时Ceph也拥有功能强大的API。在世界上的各大公司都能发现Ceph的身影——提供块存储,文件存储,对象存储。由于
Ceph是目前唯一提供以下所有功能的存储解决方案,因此Ceph越来越受欢迎,并吸引了许多大型企业的极大兴趣: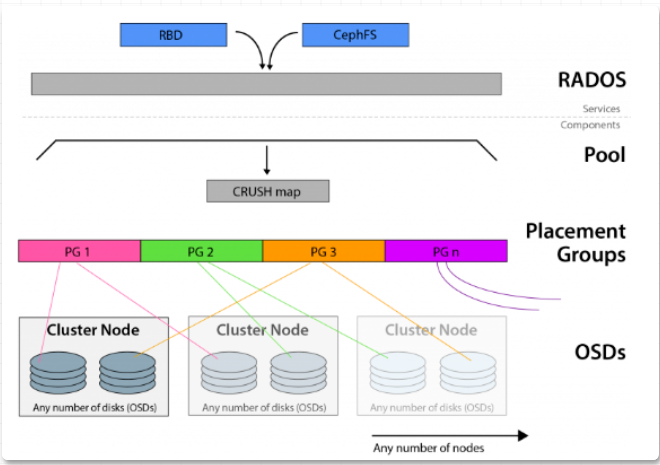
- 「软件定义」:软件定义存储 (
SDS) 是一种能将存储软件与硬件分隔开的存储架构。不同于传统的网络附加存储 (NAS) 或存储区域网络 (SAN) 系统,SDS一般都在行业标准系统或x86系统上运行,从而消除了软件对于专有硬件的依赖性。借助Ceph,还可以为诸如纠错码,副本,精简配置,快照和备份之类的功能提供策略管理。 - 「企业级」 :
Ceph旨在满足大型组织在可用性,兼容性,可靠性,可伸缩性,性能和安全性等方面的需求。它同时支持按比例伸缩,从而使其具有很高的灵活性,并且其可扩展性潜力几乎无限。 - 「统一存储」:
Ceph提供了块+对象+文件存储,从而提供了更大的灵活性(大多数其他存储产品都是仅块,仅文件,仅对象或文件+块;ceph提供的三种混合存储是非常罕见)。 - 「开源」:开源实现技术的敏捷性,通常提供多种解决问题的方法。开源通常也更具成本效益,并且可以更轻松地使组织开始规模更小,规模更大。开源解决方案背后的许多意识形态孕育了一个相互协作且参与度高的专业社区,这些社区反应灵敏且相互支持。更不用说开源是未来的方向。
Web,移动和云解决方案越来越多地建立在开源基础架构上。
「为什么选择Ceph?」
「Ceph 分布式核心组件」
集群文件系统最初始于1990年代末和2000年代初。
Lustre是最早利用可伸缩文件系统实现产品化的产品之一。多年来,出现了其他一些Lustre衍生产品,包括GlusterFS,GPFS,XtreemFS和OrangeFS等。这些文件系统都集中于为文件系统实现符合POSIX的挂载,并且缺乏通用的集成API。Ceph的架构并不需要考虑到需要与POSIX兼容的文件系统——这完全得益于云的时代。利用RADOS,Ceph可以扩展不受元数据约束限制的块设备。这极大地提高了存储性能,但是却使那些寻求基于Ceph的大型文件系统挂载方法的人们望而却步。直到Ceph Jewel(10.2.0)版本发布为止,CephFS已经是稳定且可靠的文件系统——允许部署POSIX挂载的文件系统。Ceph支持块,对象和文件存储,并且具有横向扩展能力,这意味着多个Ceph存储节点(服务器)共同提供了一个可快速处理上PB数据(1PB = 1,000 TB = 1,000,000 GB)的存储系统。利用作为基础的硬件组件,它还可以同时提高性能和容量。Ceph具有许多基本的企业存储功能,包括副本,纠错码,快照,自动精简配置,分层(在闪存和普通硬盘之间缓存数据的能力——即缓存)以及自我修复功能。为了做到这一点,Ceph利用了下面将要探讨的几个组件。从
Ceph Nautilus(v14.2.0)开始,现在有五个主要的守护程序或服务,它们集成在一起以提供Ceph服务的正常运行。这些是:- 「ceph-mon」:
Monitor确实提供了其名称所暗示的功能——监视群集的运行状况。该监视器还告诉OSD在replication期间将数据放置在何处,并保留主CRUSH Map。 - 「ceph-osd」:
OSD是Ceph的基础数据存储单元,它利用XFS文件系统和物理磁盘来存储从客户端提供给它的块数据。 - 「ceph-mds」:
MDS守护程序提供了将Ceph块数据转换为存储文件的POSIX兼容挂载点的功能,就像您使用传统文件系统一样。 - 「ceph-mgr」:
MGR守护程序显示有关群集状态的监视和管理信息。 - 「ceph-rgw」:
RGW守护程序是一个HTTP API守护程序,对象存储网关实际上是调用librados的API来实现数据的存储和读取。而该网关同时提供了兼容AWS S3和OpenStack Swift的对象存储访问接口(API)。
从术语的角度来看,
Ceph需要了解一些重要的知识。Ceph基于CRUSH算法构建, 并支持多种访问方法(文件,块,对象)。CRUSH算法确定对象在OSD上的位置,并且可以将这些相同的块拉出以进行访问请求。Ceph利用了可靠,自治,分布式的对象存储(或RADOS),该对象存储由自我修复,自我管理的存储节点组成。前面讨论的OSD守护程序是RADOS群集的一部分。放置组(
PG)的全称是placement group,是用于放置object的一个载体,所以群集中PG的数量决定了它的大小。pg的创建是在创建ceph存储池的时候指定的,同时跟指定的副本数也有关系,比如是3副本的则会有3个相同的pg存在于3个不同的osd上,pg其实在osd的存在形式就是一个目录。PG可以由管理员设置,新版本中也可以根据集群使用情况自动缩放。RBD即RADOS Block Device的简称,RBD块存储是最稳定且最常用的存储类型。RBD块设备类似磁盘可以被挂载。RBD块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式存储在Ceph集群的多个OSD中。可以在Ceph中用于创建用于虚拟化的镜像块设备,例如KVM和Xen。通过利用与RADOS兼容的API librados,VM的访问不是通过iSCSI或NFS,而是通过存储API来实现的。使用场景
正如我们已经描述的那样,
Ceph是一个非常灵活和一致的存储解决方案。对Ceph存储对象的访问可以通过多种方式来完成,因此Ceph具有其他类似产品所缺乏的大量生产用例。可以将
Ceph部署为S3/Swift对象存储的替代品。通过它的RADOS网关,可以使用http GET请求以及大量可用的Amazon S3 API工具箱访问存储在Ceph中的对象。也可以通过
librados API或iSCSI/NFS在包括VMWare和其他专有虚拟化平台在内的虚拟化环境中直接使用Ceph。可以部署
CephFS为需要访问大型文件系统的操作系统提供POSIX兼容的挂载点。根据以上的这些场景,我们可以利用单个存储平台来满足各种计算和存储需求。
「潜在的部署方案」
常用的
Ceph部署工具主要有:ceph-deploy,ceph-ansible,基于kubernetns的Rook以及新版本基于容器的kubeadm等。当然工具不仅仅是这些。每一种部署方案都有大量的生产实践。以下简单介绍以下这几种常用的部署方式:「Ceph-deply」:该工具可用于简单、快速地部署
Ceph集群,而无需涉及繁杂的手动配置。它在管理节点上通过ssh获取其它Ceph节点的访问权、通过sudo获取其上的管理权限、通过底层Python脚本自动化各节点上的Ceph安装进程。它简单到可以运行在工作站上,不需要服务器、数据库或任何其它的自动化工具。使用ceph-deploy安装和拆除集群非常简单。然而它不是通用部署工具,是专为想快速安装、运行Ceph的人们设计的专用工具,这样的集群只包含必要的的初始配置选项,就没必要安装像Chef、Puppet或Juju这样的部署工具。「Ceph-ansible」:用于部署
Ceph分布式系统的ansible playbook,ceph-ansible是安装和管理完整ceph集群的最灵活的方法,当前大量的生产环境都会使用该安装方式。「Rook」:
Rook是一个编排器,能够支持包括Ceph在内的多种存储方案。Rook简化了Ceph在Kubernetes集群中的部署过程。Rook是一个可以提供Ceph集群管理能力的Operator。Rook使用CRD一个控制器来对Ceph之类的资源进行部署和管理。「Cephadm」:较新的集群自动化部署工具,支持通过图形界面或者命令行界面添加节点,目前不建议用于生产环境。
cephadm的目标是提供一个功能齐全、健壮且维护良好的安装和管理层,可供不在Kubernetes中运行Ceph的任何环境使用。Cephadm通过SSH从manager守护进程连接到主机来部署和管理Ceph集群,以添加、删除或更新Ceph守护进程容器。它不依赖于外部配置或编排工具,如Ansible、Rook或Salt。「结论」
Ceph的性能与功能不断得到提升,存储特性也不断丰富,甚至可以与传统专业存储媲美,完备的存储服务和低廉的投资成本,使得越来越多的企业和单位选用Ceph提供存储服务。大量的生产最佳实践也使得Ceph成为标准SDS的最优解决方案之一。Cephadm管理Ceph集群的整个生命周期,是官方以后力推的部署以及管理Ceph的解决方案。它首先在单个节点(一个监视器和一个管理器)上引导一个很小的Ceph集群,然后使用编排接口扩展集群以包括所有主机并提供所有Ceph守护进程和服务。这可以通过Ceph命令行界面(CLI)或仪表板(GUI)来执行。Cephadm是Octopus发行版中的一个新功能,在生产中的使用有限。社区希望用户尝试cephadm,特别是对于新的集群,但请注意,有些功能仍然很粗糙。当前社区持续在改进以及相应BUG修复中。5种最常见的CEPH失败方案
Ceph是一种广泛使用的存储解决方案,可在整个分布式集群中实现对象级,块级和文件级存储。Ceph是创建不围绕单个故障点进行扩展的高效存储系统的理想选择。但是,如果管理不当,Ceph可能很容易成为失败场景的雷区,这可能是一件难以完全避免的事情。本处,我们将探讨最常见的五种Ceph失败方案。
「Monitor数目不正确」在最新版本的
Ceph中,至少需要三台运行Ceph Mon守护程序的服务器。这些可以是物理服务器(理想情况下)或者也可以是虚拟机。但是,如果您超出了Mon服务器的最小数量,则在Ceph构建中始终保持运行奇数个守护程序非常重要。这个奇数很重要,因为它允许系统正确地建立一个主机来控制CRUSH Map。在确定主服务器时,每台服务器都会“投票”认为最适合维护crush map的服务器。维护奇数个Ceph守护程序可确保永远不会出现投票平局的现象,并且始终会建立一个主服务器。如果没有维护奇数个守护程序,则可能会导致不稳定,并最终导致Ceph崩溃。「OSD数目不正确」
根据在
Ceph集群中所设置的副本数,您将需要足够数量的硬盘(OSD——对象存储设备)。当您计划购买或升级当前Ceph中的OSD前,最重要的是要根据当前状况进行数据量预测,以匹配未来生产的数据量。通常,最好至少提前6到12个月进行估算,并将此存储量乘以所需的对象冗余量(即32TB数据*3(副本数)=96TB所需的存储空间)。通过适当的预测,您可以避免OSD过载,并保持CEPH环境正常运行。「RADOS网关冗余不足」
RADOS(「Reliable, Autonomic Distributed Object Store」) 是Ceph的核心之一,作为Ceph分布式文件系统的一个子项目,特别为Ceph的需求设计,能够在动态变化和异质结构的存储设备集群之上提供一种稳定、可扩展、高性能的单一逻辑对象(Object)存储接口和能够实现节点的自适应和自管理的存储系统。RADOS构成了Ceph集群的核心,并且与Ceph CRUSH Map结合使用时,可以使您在服务器的集群中保持数据一致且可安全的进行数据同步与复制。可以以多种不同方式访问Ceph数据。其中之一是通过称为RADOS网关的HTTP API前端进行的。RADOS网关公开了一个存储API,供外部人员调用。如果通过
RADOS网关访问您的Ceph集群,那么促进API访问的前端服务器必须冗余且能够负载均衡,这一点非常重要。在理想的配置中,多个RADOS服务器将可用于接受请求,并且所有请求都应由一个冗余的负载均衡器进行管理。如果未进行正确配置,则非冗余RADOS网关服务器的故障将导致您完全失去对CEPH群集的API访问权限。您可以使用混合的解决方案,该混合解决方案会利用本地RADOS网关,当发生故障时则会回退到基于云的冗余网关上。这可以最大程度地减少额外的不必要转换,同时保持对存储解决方案的冗余和可靠访问。「硬件配置不足」
为
CEPH集群维护硬件时,最重要的是要确保硬件配置满足实际需求,具体需要考虑的如下:- 「电源」:确保主机的电源模块至少是双路冗余。还要确保每台
CEPH服务器都有一个备用电源,该备用电源的功率足以完全满足服务器的需求。没有适当的冗余,您将面临不可挽回的数据丢失的风险。 - 「CPU」:最佳实践要求在所有
CEPH服务器上使用相同型号相同配置的CPU。这有助于在整个ceph集群中保持一致性以及稳定性。 - 「内存」:与
CPU相似,您使用的内存应在CEPH服务器之间平均分配。理想情况下,存储服务器的品牌和规格应该相同。此外,在发生硬件故障时,还应具有大量可用的冗余内存(备件)。 - 「硬盘」:建议将
SAS磁盘用于OSD。如果有可能的话,使用故障率低于SAS盘的NVMe磁盘则会更为理想。 - 「其他」:如果有可能的话,可以提供一些冷备机器。当存储节点存现故障的时候,极端情况下可以直接进行备机更换(保留物理磁盘)。
「CEPH专业知识」
通常,
CEPH失败的原因是由于缺乏CEPH相关的专业知识。例如,所有CEPH群集中OSD节点都将利用硬盘直通模式来确保性能和可靠性。但是,如果改用RAID的话,则不仅是不推荐的,而且还会因为磁盘阵列故障而导致出现单点故障,最终可能引起大量数据丢失。这种错误很简单,但从长远来看,这样的错误代价高昂,并且可能需要更高级的ceph专家去解决相应的问题。Ceph常规排障
如果Ceph集群崩溃该怎么办
由于
Ceph在软件层就内置了所有可用的冗余和故障保护功能,因此简单的故障不太可能造成灾难性的后果,并且一般的故障相对都是比较容易恢复的。但问题是,当遇到一系列意外事件导致集群停止响应存储请求或使所有VM虚拟机脱机时,那又该怎么办?「保持冷静」
Ceph非常强大,其Crush算法可确保数据的完整性和可用性。记住这一关键事实将有助于您确定中断的原因。最常见的灾难性故障场景之一是群集丢失的
OSD超过维护所需的冗余级别所需的OSD。在这种情况下,快速识别并更换有问题的OSD将使您的群集恢复工作状态。同时也让我们确定其他潜在故障触发因素。「记录和状态」
Ceph在mon(monitor)节点和osd(object storage daemon)节点上提供了多个日志和状态查看命令,您应该首先利用Ceph相关命令行来查看群集的运行状况。要评估
Ceph集群的当前状态,请输入:# ceph status或者使用:
# ceph -s两次命令的结果都应输出类似于以下内容:
cluster b370a29d-9287-4ca3-ab57-3d824f65e339
health HEALTH_OK
monmap e1: 1 mons at {ceph1=10.0.0.8:6789/0}, election epoch 2, quorum 0 ceph1
osdmap e63: 2 osds: 2 up, 2 in
pgmap v41332: 952 pgs, 20 pools, 17130 MB data, 2199 objects
115 GB used, 167 GB / 297 GB avail
1 active+clean+scrubbing+deep
951 active+clean如果您看到健康状况为“
HEALTH_OK”,那就说明集群状态健康。在某些情况下,尤其是与
OSD相关的情况下,将返回HEALTH_WARN或HEALTH_ERR。这可能是由于一些不影响群集整体性能的因素所致,例如OSD重新均衡或存储池的PG的深度清理。这些都可以安全地忽略。在某些情况下,
Ceph的命令行界面可能根本不响应这两个命令。如果您的Ceph的身份验证有问题,或者运行Monitor服务的节点硬件有问题,通常会发生这种情况。在第二种情况下,则需要诊断Monitor节点服务器本身的硬件问题。「mon(Monitor)调试」
当使用多个
Ceph Mon运行时,Ceph则需要仲裁(Quorum)。仲裁是确保一致性的可靠方法,因为群集需要最少的“投票”数才能继续进行replication。可以使用以下几个命令来确定
Ceph Mon的状态。# ceph mon stat上述命令将输出集群中所有
mon的当前状态,例如:e3: 3 mons at {pve1=10.103.6.109:6789/0,pve2=10.103.6.110:6789/0,pve3=10.103.6.111:6789/0}, election epoch 30, leader 0 pve1, quorum 0,1,2 pve1,pve2,pve3上面表示有三个
Ceph Mon已经启动并成功运行。其中有一个仲裁节点,状态显示集群运行正常。您会注意到ceph mon stat的输出中有几条重要的信息,包括选举之间的时间间隔(以秒为单位)。选举在这些时间间隔内发生,以确定哪个监视器应该是集群的“leader”。与使用仲裁作为确保一致性的方法的非技术机构一样,每个节点都有一票表决权。在
Ceph中,最佳实践坚持我们利用大于或等于3的奇数个Ceph Mon节点。这确保了我们的群集在失去一个或者两个仲裁节点的小概率事件中维持仲裁能力和一定程度的冗余。如果我们真的失去了法定人数(
quorum),或者没有赢得法定人数的投票。那么,由于监视器在其Ceph运行中所起的重要作用,则会导致Ceph群集将完全无法响应。从跟踪数据存放位置到维护OSD的实时Map。Ceph Mon节点还提供用于返回“Ceph health”和“Ceph -s”输出功能。如果没有一个正常工作的Ceph Mon仲裁,则所有命令都不会有任何返回值。检查监视器状态的其他有用命令包括:
#dumping the mon map
# ceph mon dump
dumped monmap epoch 3
epoch 3
fsid 4a1dc77a-37f8-4b5b-9476-853f7cace716
last_changed 2020-8-18 10:50:36.846268
created 2020-8-18 10:50:25.571368
0: 10.103.6.109:6789/0 mon.pve1
1: 10.103.6.110:6789/0 mon.pve2
2: 10.103.6.111:6789/0 mon.pve3
# ceph quorum_status --format json-pretty #looking at quorum status
{
"election_epoch": 30,
"quorum": [
0,
1,
2
],
"quorum_names": [
"pve1",
"pve2",
"pve3"
],
"quorum_leader_name": "pve1",
"monmap": {
"epoch": 3,
"fsid": "4a1dc77a-37f8-4b5b-9476-853f7cace716",
"modified": "2020-8-18 10:50:36.846268",
"created": "2020-8-18 10:50:25.571368",
"features": {
"persistent": [
"kraken",
"luminous"
],
"optional": []
},
"mons": [
{
"rank": 0,
"name": "pve1",
"addr": "10.103.6.109:6789/0",
"public_addr": "10.103.6.109:6789/0"
},
{
"rank": 1,
"name": "pve2",
"addr": "10.103.6.110:6789/0",
"public_addr": "10.103.6.110:6789/0"
},
{
"rank": 2,
"name": "pve3",
"addr": "10.103.6.111:6789/0",
"public_addr": "10.103.6.111:6789/0"
}
]
}
}「守护进程套接字(「Daemon Socket」)」
Ceph管理套接字(daemon socket)允许您直接连接到所有正在运行的Ceph守护进程。从OSD到Mon和MGR,Ceph守护程序管理套接字可以提供诊断功能,这些功能在Ceph Mon发生故障并且Ceph客户端停止响应时可能会变得不可用。以下命令可直接连接到
Ceph守护程序,根据需求进行状态查看。# ceph daemon {daemon-name} ##OR
# ceph daemon {path-to-socket-file} ##For Example
# ceph daemon osd.0 help
{
"calc_objectstore_db_histogram": "Generate key value histogram of kvdb(rocksdb) which used by bluestore",
"compact": "Commpact object store's omap. WARNING: Compaction probably slows your requests",
"config diff": "dump diff of current config and default config",
"config diff get": "dump diff get : dump diff of current and default config setting ",
"config get": "config get : get the config value",
"config help": "get config setting schema and descriptions",
"config set": "config set [ ...]: set a config variable",
"config show": "dump current config settings",
"dump_blacklist": "dump blacklisted clients and times",
"dump_blocked_ops": "show the blocked ops currently in flight",
"dump_historic_ops": "show recent ops",
"dump_historic_ops_by_duration": "show slowest recent ops, sorted by duration",
"dump_historic_slow_ops": "show slowest recent ops",
"dump_mempools": "get mempool stats",
"dump_objectstore_kv_stats": "print statistics of kvdb which used by bluestore",
"dump_op_pq_state": "dump op priority queue state",
"dump_ops_in_flight": "show the ops currently in flight",
"dump_pgstate_history": "show recent state history",
"dump_reservations": "show recovery reservations",
"dump_scrubs": "print scheduled scrubs",
"dump_watchers": "show clients which have active watches, and on which objects",
"flush_journal": "flush the journal to permanent store",
"flush_store_cache": "Flush bluestore internal cache",
"get_command_descriptions": "list available commands",
"get_heap_property": "get malloc extension heap property",
"get_latest_osdmap": "force osd to update the latest map from the mon",
"getomap": "output entire object map",
"git_version": "get git sha1",
"heap": "show heap usage info (available only if compiled with tcmalloc)",
"help": "list available commands",
"injectdataerr": "inject data error to an object",
"injectfull": "Inject a full disk (optional count times)",
"injectmdataerr": "inject metadata error to an object",
"log dump": "dump recent log entries to log file",
"log flush": "flush log entries to log file",
"log reopen": "reopen log file",
"objecter_requests": "show in-progress osd requests",
"ops": "show the ops currently in flight",
"perf dump": "dump perfcounters value",
"perf histogram dump": "dump perf histogram values",
"perf histogram schema": "dump perf histogram schema",
"perf reset": "perf reset : perf reset all or one perfcounter name",
"perf schema": "dump perfcounters schema",
"rmomapkey": "remove omap key",
"set_heap_property": "update malloc extension heap property",
"set_recovery_delay": "Delay osd recovery by specified seconds",
"setomapheader": "set omap header",
"setomapval": "set omap key",
"status": "high-level status of OSD",
"trigger_scrub": "Trigger a scheduled scrub ",
"truncobj": "truncate object to length",
"version": "get ceph version"例如,当多个
Ceph monitor守护进程同时失败时,Ceph守护程序可用于更新mon map。这将使您可以将新的mon map更新并导入到无法运行的Ceph Mon节点中,这也是Ceph中非常常见的一个故障解决方案。「规避风险」
用户应该尽量熟悉这两种从
Ceph群集崩溃或意外中断中恢复的重要方法。这些工具功能强大,学习如何利用它们则能尽量减少数据丢失的风险,同时也能够最快,最全的恢复Ceph集群。当然,每一个故障场景都不同,本处仅仅是提供了一些常规的集群崩溃故障以及对应的解决方案。但更复杂的场景需要用户根据自身所遇到的场景进行更加具体的分析以及处理。
Ceph — OSD Flapping(抖动)调试和恢复
下面我们将特别讨论如果当您发现
Ceph OSD因意外而进行peering,出现scrubbing或集群连接断断续续的情况时候该如何进行排查以及解决问题。其实,上述的这些行为也可以称之为抖动(flapping),而且这因多种原因而引起的故障会损害群集的性能和持久性以及稳定性。
「故障」
当一个
OSD或多个OSD开始抖动(flapping)时,您可能首先会注意到读写速度明显下降。这是出于多种原因。当OSD在不停的抖动(flapping)期间停止时,您实际上已经失去了正在抖动(flapping)的所有OSD的总吞吐量,也就是说这些抖动(flapping)OSD不仅不能提供正常的存储能力,还影响了整个集群的性能。尤其是在一个拥有数万IOPS读写的大型集群上,这可能是灾难性的。OSD服务正常后,群集要做的第一件事就是尝试进行恢复。恢复并不是一个非常简单的过程,其中需要对在多个不同主机上的多个OSD中副本的块进行校验和验证,以确保完整性。如果校验和不匹配,则需要重新复制该块。此校验和验证和文件重新传输过程会引起
Ceph集群的大量硬件资源消耗。最直接的体现是:服务器设备耗电量会大幅度增加,群集网络上的网络流量也会急剧增加。如果当前Ceph集群已经处于一个高负载的环境,这种额外的不必要的负载可能会导致性能进一步下降,甚至导致集群停止响应,极端情况会引起Ceph集群的一连串的崩溃。那么,如何查看
Ceph集群的症状,以查看性能问题是否与OSD的抖动(flapping)相关?第一种也是最简单的方法是简单地检查群集的运行状况。这可以通过使用Luminous及更高版本中提供的Ceph仪表板来完成。可通过“https://IPCEPHNODE:7000” (7000为访问端口,在初始化的时候可以根据需求进行自定义)。您还可以在任何启用了ceph-admin的主机上通过命令行查看Ceph群集的状态。可以使用“ceph -s”命令,该命令将输出集群的当前运行状况。如果正在进行修复或OSD当前被标记为down,该命令将向您发出输出警报。「原因和解决方法」
通常,导致
OSD抖动(flapping)的原因与导致OSD失败的原因相似。不良的硬件状况,过多的发热,网络问题以及整个系统的负载都可能导致OSD抖动(flapping)。从硬件的角度来看,底层的存储磁盘可能出现物理故障。所有硬盘都可通过
SMART属性监视其当前状态。这些值提供有关硬盘各种参数的信息,并可提供有关磁盘剩余寿命或任何可能的错误的信息。此外,可以执行各种SMART测试,以确定磁盘上的任何硬件问题。因此,可以利用Smartctl来确定当前环境中的SAS或者SATA磁盘是否处于不健康状态——这可能导致OSD故障并不停重启。通过登录到可能受影响的主机并输入“smartctl -a /dev/sdX”(其中X是设备ID)来定位物理设备,从而检查硬盘驱动器的SMART状态。同时还可以通过grep正则匹配去过滤所需要的参数。通过该方式,不仅将输出硬盘当前的状态,同时会显示即将发生故障。如果可以的话,请及时更换有故障的硬盘!OSD抖动(flapping)的另一个原因可能很简单,比如您的Ceph存储网络接口上的MTU不匹配。MTU或Maximum Transmission Unit,用来通知对方所能接受数据服务单元的最大尺寸,说明发送方能够接受的有效载荷大小,也就是允许接口发送的最大数据包大小——有效地将数据包拆分为较小的块,以适合系统指定的MTU。因为Ceph是一种处理大型数据块的存储技术,所以MTU越大,代表系统以最少的工作量就可以获得更多的吞吐量。如果整个集群中的任何地方的
MTU不匹配,即一台服务器的MTU设置为9000,另一台服务器的MTU设置为1500,你最终会遇到这样的情况:数据传输卡顿,并且Ceph集群的复制也会基本停止。这也可能是Ceph OSD抖动(flapping)的另外一个原因(健康检查与低MTU的竞争带宽)。要检查接口的
MTU,请在命令行上键入“ifconfig”或“ip addr”。将MTU与接口匹配,并比较群集中所有主机接口的MTU配置是否一致。「结论」
Ceph OSD的抖动是存储使用过程中最常见的一种故障,该故障不一定会致命,但往往会对集群性能产生严重的影响。及时发现OSD抖动,合理解决问题,尽量避免对集群产生过多的影响。「Ceph性能优化与增强」
上文介绍了
Ceph的入门背景,讨论了Ceph在云计算和对象存储中的功能和主要组件,并简要概述了其部署工具以及常规的故障现象以及对应的解决思路。下文,我们将研究Ceph的强大的功能,并探索最优的方法来提高存储性能。Ceph是一个非常复杂的存储系统,它具有几种我们可以用来提高性能的方式。幸运的是,Ceph的开箱即用非常好,许多性能设置几乎利用了自动调整和缩放功能。在探索一些性能增强时,了解您的工作负载很重要,这样您就可以选择最适合您的选项。
「配置说明」
Ceph有几种部署方案,其中最常见的是针对虚拟化环境,符合POSIX的文件系统和块存储的组合。这些场景中的每一个都有明显不同的配置要求。例如,在CephFS提出的POSIX文件系统中,将文件系统元数据存储在高速SSD或NVMe驱动器上是非常重要。对于虚拟化环境中使用RBD场景,Ceph的caching tier功能可以使用SSD或NVMe为后端普通廉价的存储提供高速缓存的功能。「通用硬件」
「Hyper-Threading(HT)」基本做云平台的,
VT和HT打开都是必须的,超线程技术(HT)就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高的CPU的运行效率。「关闭节能」关闭节能后,对性能还是有所提升的,所以坚决调整成性能型(
Performance)。当然也可以在操作系统级别进行调整,详细的调整过程请参考链接,但是不知道是不是由于BIOS已经调整的缘故,所以在CentOS 6.6上并没有发现相关的设置。for CPUFREQ in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do [ -f <span class="katex math inline">CPUFREQ ] || continue; echo -n performance></span>CPUFREQ; done「NUMA」简单来说,
NUMA思路就是将内存和CPU分割为多个区域,每个区域叫做NODE,然后将NODE高速互联。node内cpu与内存访问速度快于访问其他node的内存,NUMA可能会在某些情况下影响ceph-osd。解决的方案,一种是通过BIOS关闭NUMA,另外一种就是通过cgroup将ceph-osd进程与某一个CPU Core以及同一NODE下的内存进行绑定。但是第二种看起来更麻烦,所以一般部署的时候可以在系统层面关闭NUMA。CentOS系统下,通过修改/etc/grub.conf文件,添加numa=off来关闭NUMA。kernel /vmlinuz-2.6.32-504.12.2.el6.x86_64 ro root=UUID=870d47f8-0357-4a32-909f-74173a9f0633 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM biosdevname=0 numa=off「RAM」
为
Ceph选择的主机及其基础服务应具有足够的CPU线程,内存和网络设备,以处理群集的预期吞吐量。Ceph建议每1TB OSD原始磁盘空间使用1GB RAM。如果主机具有96TB的原始磁盘空间,则应计划至少需要96GB的RAM。我们建议每个OSD至少使用1个CPU内核。OSD可以定期消耗整个CPU来执行重新平衡操作。「避免使用超融合!」
不建议以超融合方式在
Ceph节点上运行其他应用程序,因为在由于磁盘故障而导致的群集重建过程中,每个OSD的OSD RAM使用量可能远远超过建议的1GB。如果其他应用程序争夺RAM,则重建性能以及随后的Ceph群集本身的读写性能都会受到严重影响。「不要使用硬件RAID控制器!」
让
Ceph为您完成数据处理。使用硬件RAID控制器可能导致Ceph在RAID重建期间未意识到的不一致和性能下降。SAS HBA的价格为$100-$200,高性能的仅占很小的溢价。这将是确保Ceph集群性能的最佳配置。「基础存储OSD」
当构建一个新的
Ceph群集时,其中一个主要的工作是对象存储守护程序(OSD)的底层存储的选择。容量需求可能决定了该解决方案所需要的底层存储。预算可能允许购买大容量的SSD驱动器或NVMe。无论选择了什么样的底层存储,累计底层存储的性能都将直接影响Ceph集群的性能(OSD性能越佳,则Ceph集群性能也越佳)。在需要使多个
10G万兆网络接口的环境中,或者对于读写时延极低的应用程序,选择SSD或NVMe磁盘可能更有意义。这些将为OSD提供企业级磁盘的完整吞吐量,包括在整个群集中的组合IOPS。SATA和SAS类型磁盘确实提供了比SSD和NVMe更大的标准存储容量,但是IOPS与吞吐量有限(受限于OSD所使用的存储介质)。因此,群集中将需要更大的磁盘阵列,以提供与更快的磁盘相似的甚至远超的性能。「缓存层」
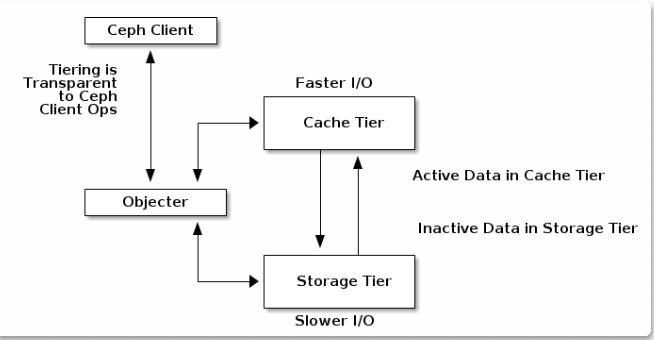
Ceph Luminous中的新增功能,对于出于预算原因或使用大容量磁盘的项目,可以充分提前预估存储容量的用户而言,缓存层(Cache Tier)是一项极佳的性能增强解决方案。构建缓存层(Cache Tier)需要为每个Ceph存储节点提供少数量的SSD或NVMe磁盘,并修改Crush Map映射以创建单独的存储类。最佳实践表明,除非您能够准确预测实际数据量,否则缓存应不小于活动存储池的
1/10到1/8的容量。因此,如果您有100TB的数据池,则应计划为您的缓存层提供大约10TB的存储空间。「Crush Map」
CRUSH算法通过计算数据存储位置来确定如何存储和检索。CRUSH授权Ceph客户端直接连接OSD,而非通过一个集中服务器或代理。数据存储、检索算法的使用,使Ceph避免了单点故障、性能瓶颈、和伸缩的物理限制。CRUSH需要一张集群的Map,且使用CRUSH Map把数据伪随机地、尽量平均地分布到整个集群的OSD里。CRUSH Map包含OSD列表、把设备汇聚为物理位置的“桶”列表、和指示CRUSH如何复制存储池里的数据的规则列表。CRUSH Map负责确保数据最终到达群集中应有的位置,并在将IO请求转换为磁盘位置以进行数据检索中发挥作用。正确的CRUSH Map将考虑设备的适当权重,通常由磁盘大小决定,尽管您可以根据磁盘IOPS等其他因素来修改权重(一般不建议这样做)。「系统调整」
一个经过适当调优的系统将是实现
Ceph预期性能的关键。请特别关注网络和sysctl优化。一些关键参数包括:- 「系统MTU」 :将其设置为
9000以允许大帧。众所周知,存储流量在TCP堆栈上非常频繁,应允许其尽可能多地传输数据而不会造成碎片,以确保您能够充分使用存储网络。 - 「Swappiness」 :通常,使用
swap分区是不太好的。每当您从内存切换到磁盘时,操作系统就会用完执行基本功能所需的内存,并且不得不将其中的某些内存强制降低到速度慢得多的磁盘上。在查看性能时,不能忽略Ceph群集的RAM分配的正确大小。可以在linux系统中配置Sysctl相应的参数,以强制linux停止使用交换分区。我们建议值为1,默认值通常可以在20到40之间。数字越大,内核尝试交换的频率就越高。 - 「“ noatime”」 :在大多数已挂载的文件系统上使用此选项,以跟踪磁盘上文件的上次访问时间。由于这是由
OSD自己单独处理的,因此在速度较慢的磁盘上禁用noatime可以提高性能。
「Ceph架构调整」
关于Ceph的配置以及优化的思路整体涉及如下:
Mon节点对于群集的正常运行至关重要。尝试并使用独立的Mon节点,请确保资源独享;或者,如果它们在共享环境中运行,则需要隔离Mon进程。为了实现冗余,请在Ceph集群中将Mon节点尽量均匀分布。Journal日志因双写缘故,对影响影响较大。理想情况下,您应该在单独的物理磁盘上运行操作系统,OSD数据和OSD日志,以最佳的方式提高整体吞吐量。可以考虑将SSD用作Journal分区来提供读写吞吐量。- 如果使用的是
bluestore而非filestore的话,也请考虑rocksdb与wal的存储使用SSD分区。 - 纠错码是对象存储的一种数据持久性特性。当存储大量一次写入、不经常读取的数据时,请使用纠错码。但是请记住,这是一个折衷方案:纠错码可以大大降低每
GB的成本,但与副本相比,其IOPS性能较低。 - 支持
dentry和inode缓存可以提高性能,尤其是在具有许多较小对象的群集上。 - 使用缓存分层,可以根据需求在热层和冷层之间自动迁移数据,从而提高群集的性能。为了获得最佳性能,请将
SSD用于高速缓存池,并将存储池托管在具有较低延迟的服务器上。 - 部署奇数个
Mon节点(3个或5个)以进行法定投票。添加更多的Mon可使您的群集更持久。但是,这有时会降低性能,因为Mon之间还有更多数据要保持同步。 - 排查群集中的性能问题时,请始终从最低级别(磁盘,网络或其他硬件)开始,然后逐步升级至更高级别(块设备和对象网关)。
PG和PGP数量一定要根据OSD的数量进行调整,不合理的PG数目会导致数据分布不均衡。Ceph OSD存在木桶原理,单个OSD的性能下降可能会影响整个集群的性能,所以要及时发现低性能的OSD,然后更换或者直接踢出集群。
「结论」
根据以上几种方法可以正确实现
Ceph以提供您期望的性能。利用磁盘缓存,缓存分层和适当配置的系统,可以确保磁盘性能不会成为基础架构的瓶颈。写在最后
虽然开源存储对于希望减少集中式商业存储上的用户而言来说是一个福音,但文档和支持可能会受到限制。在没有商业支持的前提下,除了靠社区的支持外,剩下的就靠用户对软件本身的熟悉程度。只有不断的尝试,不断的优化,不断的回馈社区,才能使开源软件发展的更好。
作者:祝祥
参考:
- 「软件定义」:软件定义存储 (
云和安全管理服务专家


