
-
PostgreSQL for DevOps:生产环境部署与运维实战指南
对于寻求强大、可靠且可扩展的开源数据库的 DevOps 工程师和开发人员来说,PostgreSQL 常常是首选。它不仅以其对 SQL 标准的严格遵循和丰富的功能集而闻名,更因其坚如磐石的稳定性和 ACID 特性而备受赞誉。
本指南专为 DevOps 专业人员设计,旨在提供一个从零开始、逐步深入的实战手册。我们将涵盖从初始安装、关键配置、安全管理到备份恢复、高可用复制和性能调优的全过程。读完本文,你将拥有在生产环境中自信地部署、管理和维护 PostgreSQL 所需的核心知识。
概览:深入理解 PostgreSQL 的核心机制
在深入操作之前,理解 PostgreSQL 的工作原理至关重要,尤其是它的数据写入机制。这不仅能帮助你更好地配置和优化数据库,还能让你明白为什么它如此可靠。
PostgreSQL 是一个关系型数据库,它保证了 ACID 特性 (原子性、一致性、隔离性和持久性) 。以下是它的内部工作原理:
写数据过程
INSERT statement ↓ Write-Ahead Log (WAL) buffer ↓ WAL synced to disk (this is the commitment point) ↓ Data written to shared buffers (in-memory cache) ↓ Background writer flushes to data files ↓ Data persisted关键要点 :PostgreSQL 会先将所有更改写入事务日志(WAL),然后再更新实际的数据文件。这个机制确保了即使在数据库或服务器突然崩溃的情况下,也可以通过重放日志来恢复所有已提交的事务,不会丢失数据。这也是 PostgreSQL 可靠性高的核心原因之一。
安装和初始设置:迈出第一步
现在,让我们从基础开始,在你的系统上安装 PostgreSQL,并学习如何连接和操作它。我将从基础知识讲起,逐步深入到更高级的信息,确保你完全掌握!
安装 PostgreSQL
# Ubuntu/Debian sudo apt-get update sudo apt-get install postgresql postgresql-contrib postgresql-client # macOS brew install postgresql # Verify installation psql --version # Output: psql (PostgreSQL) 16.0 # Check if running sudo systemctl status postgresql # Output: ● postgresql.service - PostgreSQL RDBMS # Loaded: loaded (/lib/systemd/system/postgresql.service) # Active: active (running)
连接到 PostgreSQ
# Connect as postgres superuser sudo -u postgres psql # Or if you have sudo access without password psql -U postgres -h localhost # Verify you're connected postgres=# \conninfo # Output: You are connected to database "postgres" as user "postgres" via socket in "/var/run/postgresql" at port 5432.
PostgreSQL 基本命令
# List all databases \l # Connect to database \c database_name # List all tables \dt # List all schemas \dn # Show table structure \d table_name # Get help \h CREATE TABLE # Exit \q
掌握这些基本命令是与 PostgreSQL 交互的基础。花点时间熟悉它们,你会在后续的管理工作中事半功倍。
初始配置:为生产环境调优 postgresql.conf
PostgreSQL 的默认配置主要为开发和低资源环境设计,远不能满足生产环境的性能和可靠性要求。postgresql.conf文件是你的主控制面板,通过调整其中的参数,我们可以释放数据库的全部潜力。
postgresql.conf 文件用于配置 PostgreSQL 的行为。请查找该
# Find location sudo -u postgres psql -c "SHOW config_file" # Output: /etc/postgresql/16/main/postgresql.conf # View important settings sudo -u postgres psql -c "SHOW port" # Output: 5432 sudo -u postgres psql -c "SHOW data_directory" # Output: /var/lib/postgresql/16/main
生产的基本配置
以下是一份针对生产环境的基础配置建议。请注意,最佳值取决于你的服务器硬件(特别是 RAM)和具体工作负载。这里的建议是一个可靠的起点。
编辑 /etc/postgresql/16/main/postgresql.conf :
# Network settings listen_addresses = '*' # Listen on all interfaces (restrict in production with IP) port = 5432 # Standard PostgreSQL port # Memory configuration shared_buffers = 256MB # 25% of system RAM for dedicated server effective_cache_size = 1GB # 50-75% of total RAM work_mem = 16MB # Per operation memory maintenance_work_mem = 64MB # For maintenance operations # Checkpoint configuration (critical for performance) checkpoint_timeout = 15min # Force checkpoint every 15 minutes checkpoint_completion_target = 0.9 # Spread checkpoint over 90% of interval max_wal_size = 4GB # Size of WAL before forcing checkpoint min_wal_size = 1GB # Don't delete WAL below this # Write-Ahead Logging (WAL) configuration wal_level = replica # Enable replication (critical for backup/failover) max_wal_senders = 10 # Max replication connections wal_keep_size = 1GB # Keep WAL for replication wal_compression = on # Compress WAL # Connections max_connections = 200 # Max client connections superuser_reserved_connections = 10 # Reserve for superuser # Logging logging_collector = on # Enable log file collection log_directory = 'log' # Relative to data_directory log_filename = 'postgresql-%a.log' log_truncate_on_rotation = on # Overwrite old logs # Log slow queries (anything over 1s) log_min_duration_statement = 1000 # Milliseconds log_statement = 'all' # Log all statements (use 'mod' for less noise) log_connections = on log_disconnections = on # Performance synchronous_commit = on # Wait for WAL write (safer but slower) fsync = on # Always fsync to disk (never disable in production)
编辑完成后,需要让 PostgreSQL 加载新的配置。某些参数(如 shared_buffers)需要重启服务才能生效,而其他参数则可以通过重新加载配置文件来动态应用
# Reload without restart (some settings require restart) sudo -u postgres psql -c "SELECT pg_reload_conf()" # Output: pg_reload_conf # --------------- # t # Or restart PostgreSQL (safer for critical changes) sudo systemctl restart postgresql
配置完成后,务必验证关键参数是否已成功应用。
# Verify settings applied sudo -u postgres psql -c "SHOW shared_buffers" # Output: 256MB
用户和数据库管理:建立安全边界
在生产环境中,直接使用 `postgres` 超级用户来连接应用程序是极其危险的做法。最佳实践是遵循“最小权限原则”,为每个应用程序或服务创建专用的数据库和用户,并仅授予其完成任务所必需的最小权限。
创建数据库和用户
Connect as superuser sudo -u postgres psql # Create database CREATE DATABASE production_app; # Create user with password CREATE USER app_user WITH ENCRYPTED PASSWORD 'secure_password_123'; # Grant privileges to user GRANT CONNECT ON DATABASE production_app TO app_user; GRANT USAGE ON SCHEMA public TO app_user; GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO app_user; GRANT ALL PRIVILEGES ON ALL SEQUENCES IN SCHEMA public TO app_user; # Give default privileges for future tables ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT ALL ON TABLES TO app_user; ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT ALL ON SEQUENCES TO app_user; # Verify permissions \du # Lists all roles and their attributes # Exit \q
应用程序的连接字符串
你的应用程序将使用连接字符串(也称为 DSN,Data Source Name)来连接到数据库。请确保将这些凭证作为机密信息妥善管理,例如使用环境变量或专门的秘密管理工具。
# PostgreSQL connection string (DSN) postgresql://app_user:secure_password_123@localhost:5432/production_app # Test connection from command line psql postgresql://app_user:secure_password_123@localhost:5432/production_app -c "SELECT 1" # Output: ?column? # -------- # 1
创建表和索引:构建高效的数据结构
良好的数据库性能始于合理的表结构和高效的索引策略。一个精心设计的模式不仅可以确保数据完整性,还能在数据量增长时保持查询速度。
创建符合最佳实践的模式
-- Connect as app_user \c production_app app_user -- Create table CREATE TABLE users ( id SERIAL PRIMARY KEY, email VARCHAR(255) NOT NULL, username VARCHAR(100) NOT NULL, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, is_active BOOLEAN DEFAULT true ); -- Add indexes for common queries CREATE UNIQUE INDEX idx_users_email ON users(email); CREATE UNIQUE INDEX idx_users_username ON users(username); CREATE INDEX idx_users_created_at ON users(created_at); CREATE INDEX idx_users_is_active ON users(is_active); -- View table structure \d users -- View indexes \di users* -- Check index size SELECT schemaname, tablename, indexname, pg_size_pretty(pg_relation_size(indexrelid)) as size FROM pg_indexes WHERE tablename = 'users' ORDER BY pg_relation_size(indexrelid) DESC;添加约束
约束是数据库层面保证数据质量的重要工具。除了主键和唯一索引,我们还可以使用 CHECK 约束和外键来强制执行业务规则。
-- Add constraint to ensure valid email ALTER TABLE users ADD CONSTRAINT check_valid_email CHECK (email ~* '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}$'); -- Add foreign key to another table CREATE TABLE posts ( id SERIAL PRIMARY KEY, user_id INTEGER NOT NULL REFERENCES users(id) ON DELETE CASCADE, title VARCHAR(255) NOT NULL, content TEXT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ); -- View constraints \d posts监控所需的基本查询:洞察数据库状态
作为 DevOps 工程师,你需要像飞行员关心仪表盘一样关注数据库的健康状况。主动监控可以帮助你在小问题演变成大故障之前发现并解决它们。以下是一些你需要定期执行的关键查询。
检查数据库健康状况
-- Current connections SELECT datname, count(*) as connections, max(extract(epoch from (now() - query_start))) as longest_query_seconds FROM pg_stat_activity GROUP BY datname ORDER BY connections DESC; -- Long-running queries (over 5 minutes) SELECT pid, usename, query_start, extract(epoch from (now() - query_start)) as duration_seconds, query FROM pg_stat_activity WHERE query_start < now() - interval '5 minutes' ORDER BY query_start; -- Kill long-running query (DANGER: use carefully) SELECT pg_terminate_backend(pid);检查数据库大小
-- Total database size SELECT datname, pg_size_pretty(pg_database_size(datname)) as size FROM pg_database WHERE datname NOT IN ('template0', 'template1') ORDER BY pg_database_size(datname) DESC; -- Size per table SELECT schemaname, tablename, pg_size_pretty(pg_total_relation_size(schemaname||'.'||tablename)) as size FROM pg_tables WHERE schemaname NOT IN ('pg_catalog', 'information_schema') ORDER BY pg_total_relation_size(schemaname||'.'||tablename) DESC LIMIT 20; -- Unused indexes (wasting space and slowing writes) SELECT schemaname, tablename, indexname, idx_scan, pg_size_pretty(pg_relation_size(indexrelid)) as size FROM pg_stat_user_indexes WHERE idx_scan = 0 ORDER BY pg_relation_size(indexrelid) DESC;检查慢查询
慢查询是数据库性能的头号杀手。配置 PostgreSQL 记录执行时间超过特定阈值的查询,是定位和优化性能瓶颈的第一步。
首先,请确保已配置日志记录:
# Check log file location sudo -u postgres psql -c "SHOW log_directory" # Output: log # View recent logs sudo tail -f /var/lib/postgresql/16/main/log/postgresql-*.log | grep "duration:" # Output example: # LOG: duration: 2534.123 ms statement: SELECT * FROM large_table;
pg_stat_statements 是一个非常有用的扩展,它能跟踪服务器上执行的所有 SQL 语句的统计信息,让你轻松找出最耗时、最频繁或 I/O 最多的查询。
-- Queries taking longest (requires pg_stat_statements extension) CREATE EXTENSION IF NOT EXISTS pg_stat_statements; SELECT query, calls, total_time, mean_time, max_time FROM pg_stat_statements ORDER BY mean_time DESC LIMIT 10; -- Clear stats SELECT pg_stat_statements_reset();分析查询性能
当你发现一个慢查询后,EXPLAIN 命令是你最好的朋友。它能揭示 PostgreSQL 的查询优化器为执行该查询所选择的计划。通过分析这个计划,你可以判断是否缺少索引、是否进行了全表扫描,或者连接顺序是否最优。
EXPLAIN 显示了查询计划,但不会实际执行查询。而 EXPLAIN ANALYZE 则会执行查询并返回带有实际执行时间和行数的详细计划,这对于诊断问题更为精确。
-- EXPLAIN shows query plan WITHOUT executing EXPLAIN SELECT * FROM users WHERE email = 'test@example.com'; -- Output: -- QUERY PLAN -- ───────────────────────────────────────────── -- Index Scan using idx_users_email on users -- Index Cond: (email = 'test@example.com') -- EXPLAIN ANALYZE executes and shows actual performance EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'test@example.com'; -- Output includes actual timing and row counts -- ───────────────────────────────────────────── -- Index Scan using idx_users_email on users -- Index Cond: (email = 'test@example.com') -- Planning Time: 0.123 ms -- Execution Time: 0.456 ms -- Complex query analysis EXPLAIN (ANALYZE, BUFFERS) SELECT u.username, COUNT(p.id) as posts FROM users u LEFT JOIN posts p ON u.id = p.user_id GROUP BY u.id ORDER BY posts DESC;
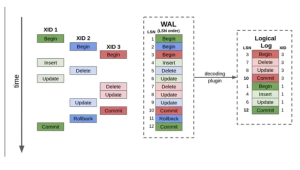
预写日志(WAL):PostgreSQL 的安全网
现在我们来深入了解一下之前提到的预写日志(Write-Ahead Log, WAL)。WAL 是 PostgreSQL 实现数据持久性和可靠性的核心机制,同时也是实现备份和复制等高级功能的基础。
WAL 是 PostgreSQL 的事务日志,它保证了 PostgreSQL 的可靠性。
理解 WAL
# Check WAL directory ls -lah /var/lib/postgresql/16/main/pg_wal/ # Output: # -rw------- 1 postgres postgres 16M Nov 15 10:23 000000010000000000000001 # -rw------- 1 postgres postgres 16M Nov 15 10:25 000000010000000000000002 # -rw------- 1 postgres postgres 16M Nov 15 10:27 000000010000000000000003 # Each WAL file is 16MB # Files are named sequentially # Older files are deleted after checkpoint (unless archiving is enabled)
配置 WAL 归档(用于备份)
默认情况下,PostgreSQL 在完成检查点后会回收旧的 WAL 文件。但为了实现时间点恢复(Point-in-Time Recovery, PITR),我们需要将这些 WAL 文件在被回收前归档到安全的位置
# Create archive directory sudo mkdir -p /backup/wal_archive sudo chown postgres:postgres /backup/wal_archive sudo chmod 700 /backup/wal_archive # Edit postgresql.conf sudo nano /etc/postgresql/16/main/postgresql.conf # Add these lines: # wal_level = replica # archive_mode = on # archive_command = 'cp %p /backup/wal_archive/%f' # archive_timeout = 300 # Force archiving every 5 minutes
配置完成后,PostgreSQL 将在每次 WAL 文件写满时,或在 archive_timeout 设定的时间内,调用 archive_command 将 WAL 段复制到指定目录。
编辑后:
# Reload configuration sudo -u postgres psql -c "SELECT pg_reload_conf()" # Force a checkpoint to start archiving sudo -u postgres psql -c "CHECKPOINT" # Verify WAL files are being archived ls -la /backup/wal_archive/ # Output: WAL files copied here
监测 WAL
-- Check WAL level SHOW wal_level; -- Output: replica -- Check WAL stats SELECT count(*) as wal_files, pg_size_pretty(sum(size)) as total_size FROM ( SELECT pg_wal_lsn_diff(pg_current_wal_lsn(), '0/0')::bigint as size ) as t; -- Current WAL position SELECT pg_current_wal_lsn(); -- Output: 0/17AB3F0备份策略:你的终极保障
如果说 WAL 是安全网,那么备份就是你的降落伞。在数据丢失或损坏的灾难性场景下,一个可靠且经过测试的备份是让你能够恢复业务的唯一希望。为避免最糟糕的情况发生,制定备份策略是必要的。以下是一些我们可以采用的方法。
策略 一:pg_dump(最适合中小型数据库)
pg_dump 是一个简单而强大的工具,用于创建数据库的逻辑备份。它生成一个包含 SQL 命令或归档格式的文件,可以用于在任何地方重建数据库。它非常适合日常备份、迁移和开发环境的搭建。
# Simple backup of one database pg_dump -U postgres -d production_app -F c -f backup.dump # Backup with compression pg_dump -U postgres -d production_app \ -F c \ -f production_app_$(date +%Y%m%d_%H%M%S).dump # Backup all databases pg_dumpall -U postgres -f all_databases.sql # Custom format (recommended for large DBs) pg_dump -U postgres -d production_app \ -F c \ --verbose \ -f backup.dump # Backup with jobs (parallel, faster) pg_dump -U postgres -d production_app \ -F d \ -j 4 \ -f backup_directory/ # Show backup size ls -lh backup.dump策略二:从备份恢复
拥有备份只是成功了一半,能够快速准确地恢复才是关键。pg_restore 是与 pg_dump 配套的恢复工具。
# Restore from custom format dump pg_restore -U postgres -d production_app -F c backup.dump # List what's in the dump before restoring pg_restore -l backup.dump | head -20 # Restore specific table pg_restore -U postgres -d production_app -F c \ -t users backup.dump # Restore with progress pg_restore -U postgres -d production_app \ -F c -j 4 --verbose backup.dump策略 三:持续归档 + 时间点恢复(PITR)
对于关键的生产数据库,仅有每日备份是不够的。如果数据库在两次备份之间发生故障,你会丢失这期间的所有数据。时间点恢复(Point-in-Time Recovery, PITR)结合了完整的基础备份和持续归档的 WAL 日志,允许你将数据库恢复到故障前一刻的任意时间点,最大限度地减少数据丢失。
这是最可靠的备份策略:
# 1. Full backup pg_basebackup -h localhost -U postgres -D /backup/base_backup -Fp -Pv # 2. WAL archiving runs continuously (configured in postgresql.conf) # 3. To restore to specific point in time: # Stop PostgreSQL sudo systemctl stop postgresql # Move current data directory sudo mv /var/lib/postgresql/16/main /var/lib/postgresql/16/main.old # Restore base backup sudo cp -r /backup/base_backup /var/lib/postgresql/16/main sudo chown -R postgres:postgres /var/lib/postgresql/16/main # Create recovery.signal to enable recovery sudo touch /var/lib/postgresql/16/main/recovery.signal # Configure recovery settings sudo nano /var/lib/postgresql/16/main/postgresql.conf # Add: # restore_command = 'cp /backup/wal_archive/%f %p' # recovery_target_timeline = 'latest' # recovery_target_time = '2024-01-15 14:30:00' # Start PostgreSQL (it will replay WAL) sudo systemctl start postgresql # Verify recovery sudo -u postgres psql -c "SELECT now()"
策略四:自动备份脚本
手动执行备份容易出错且不可持续。在生产环境中,所有备份任务都应该自动化。下面是一个简单的 bash 脚本示例,用于执行每日备份并清理旧文件。
#!/bin/bash # backup.sh BACKUP_DIR="/backup/postgresql" DB_USER="postgres" RETENTION_DAYS=30 # Create backup directory mkdir -p $BACKUP_DIR # Full backup daily at 2 AM BACKUP_FILE="$BACKUP_DIR/db_$(date +%Y%m%d_%H%M%S).dump" echo "Starting backup..." pg_dump -U $DB_USER -d production_app -F c -f $BACKUP_FILE if [ $? -eq 0 ]; then echo "✓ Backup successful: $BACKUP_FILE" # Verify backup pg_restore -U $DB_USER -d production_app -F c -l $BACKUP_FILE > /dev/null if [ $? -eq 0 ]; then echo "✓ Backup verified" fi else echo "✗ Backup failed" exit 1 fi # Remove old backups (older than RETENTION_DAYS) find $BACKUP_DIR -type f -name "*.dump" -mtime +$RETENTION_DAYS -delete echo "✓ Cleanup completed" # Optional: Copy to remote storage # scp $BACKUP_FILE remote_server:/remote/backup/将此脚本配置到 cron 中,即可实现无人值守的自动化备份。
安排一下:
# Add to crontab crontab -e # Add line (runs daily at 2 AM) 0 2 * * * /home/postgres/backup.sh >> /var/log/pg_backup.log 2>&1 # List cron jobs crontab -l
如何设置流复制:实现高可用与读扩展
流复制是 PostgreSQL 内置的高可用和负载均衡解决方案。它通过将主服务器上的 WAL 实时传输到一个或多个副本服务器来实现。这不仅提供了热备份(hot standby)以实现快速故障转移,还可以将读请求分流到副本,从而扩展读取能力。
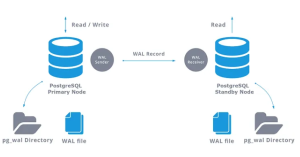
主服务器(生产环境):
# Edit postgresql.conf sudo nano /etc/postgresql/16/main/postgresql.conf # Add: wal_level = replica max_wal_senders = 10 wal_keep_size = 1GB hot_standby = on # Edit pg_hba.conf for replication user sudo nano /etc/postgresql/16/main/pg_hba.conf # Add (allow replica connection): host replication replica_user 192.168.1.0/24 md5 # Create replication user sudo -u postgres psql -c "CREATE USER replica_user WITH REPLICATION ENCRYPTED PASSWORD 'replica_password';" # Restart sudo systemctl restart postgresql
副本服务器(备用):
# Stop replica if running sudo systemctl stop postgresql # Clear old data directory sudo rm -rf /var/lib/postgresql/16/main/* # Take base backup from primary pg_basebackup -h 192.168.1.100 -U replica_user -D /var/lib/postgresql/16/main -Fp -Pv # Create standby.signal (tells PostgreSQL this is standby) sudo touch /var/lib/postgresql/16/main/standby.signal # Configure replica postgresql.conf sudo nano /var/lib/postgresql/16/main/postgresql.conf # Add: primary_conninfo = 'host=192.168.1.100 port=5432 user=replica_user password=replica_password' hot_standby = on # Set correct permissions sudo chown -R postgres:postgres /var/lib/postgresql/16/main sudo chmod 700 /var/lib/postgresql/16/main # Start replica sudo systemctl start postgresql # Verify replication is working sudo -u postgres psql -c "SELECT * FROM pg_stat_replication;" # On replica: sudo -u postgres psql -c "SELECT * FROM pg_last_wal_receive_lsn();"
监控复制状态
设置好复制后,持续监控其健康状况至关重要。你需要确保副本没有远远落后于主库,否则在故障转移时可能会丢失数据。
-- On Primary: Check replica lag SELECT client_addr, state, sent_lsn, write_lsn, flush_lsn, replay_lsn, sync_state FROM pg_stat_replication; -- On Replica: Check replication status SELECT pg_last_wal_receive_lsn() as receive_lsn, pg_last_wal_replay_lsn() as replay_lsn, pg_is_wal_replay_paused() as is_paused; -- Calculate replication lag (in bytes) SELECT pg_wal_lsn_diff(sent_lsn, replay_lsn) as lag_bytes FROM pg_stat_replication;将副本提升为主副本:故障转移
如果主服务器发生故障,你需要手动或通过自动化工具将一个健康的副本“提升”为新的主服务器,以恢复写服务。
# On replica sudo -u postgres psql -c "SELECT pg_promote();" # Verify it's now primary sudo -u postgres psql -c "SELECT pg_is_in_recovery();" # Output: f (false = it's primary now)
一些性能调优和日志分析
数据库性能调优是一个持续的过程,而不是一次性的任务。随着应用程序负载的变化,新的性能瓶颈可能会出现。定期分析慢查询日志和数据库统计信息是保持系统健康的关键。
# Enable query logging sudo -u postgres psql -c "ALTER SYSTEM SET log_min_duration_statement = 1000;" sudo -u postgres psql -c "SELECT pg_reload_conf();" # View logs tail -f /var/lib/postgresql/16/main/log/postgresql-*.log | grep "duration:" # Parse and analyze grep "duration:" /var/lib/postgresql/16/main/log/postgresql-*.log | \ awk '{print $NF}' | sort -rn | head -20如有需要,我们可以优化常见问题:
autovacuum 是 PostgreSQL 的一个内置进程,用于自动执行 VACUUM 和 ANALYZE 命令。VACUUM 回收已删除或已更新行所占用的空间,防止表膨胀;ANALYZE 则更新统计信息,以帮助查询规划器做出更好的决策。确保它已启用并正确配置。
-- 1. Add missing indexes -- Query to find queries without indexes: SELECT query FROM pg_stat_statements WHERE query LIKE '%WHERE%' LIMIT 5; -- Add index after analyzing with EXPLAIN CREATE INDEX idx_posts_user_id_created_at ON posts(user_id, created_at DESC); -- 2. Analyze table statistics ANALYZE users; ANALYZE posts; -- 3. Vacuum (reclaim space, update statistics) VACUUM ANALYZE; -- 4. Check for table bloat SELECT schemaname, tablename, pg_size_pretty(pg_total_relation_size(schemaname||'.'||tablename)) as total_size, pg_size_pretty(pg_total_relation_size(schemaname||'.'||tablename) - pg_relation_size(schemaname||'.'||tablename)) as indexes_size FROM pg_tables ORDER BY pg_total_relation_size(schemaname||'.'||tablename) DESC LIMIT 10; -- 5. Enable auto-vacuum (maintenance) SHOW autovacuum; ALTER SYSTEM SET autovacuum = on; SELECT pg_reload_conf();监控和警报:建立你的仪表盘
仅仅记录指标是不够的,你需要建立一个自动化的监控和警报系统,以便在关键指标超出正常阈值时立即得到通知。这能让你在用户报告问题之前就采取行动。
# 1. Check active connections sudo -u postgres psql -c "SELECT count(*) FROM pg_stat_activity;" # 2. Check cache hit ratio (should be > 99%) sudo -u postgres psql << EOF SELECT sum(heap_blks_read) as heap_read, sum(heap_blks_hit) as heap_hit, sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) as ratio FROM pg_statio_user_tables; EOF # 3. Check disk usage df -h /var/lib/postgresql # 4. Check transaction ID age (prevent wraparound) sudo -u postgres psql -c "SELECT datname, age(datfrozenxid) FROM pg_database;" # 5. Check replication lag (if using replication) sudo -u postgres psql -c "SELECT pg_wal_lsn_diff(pg_current_wal_lsn(), '0/0')/1024/1024 as lag_mb;"创建监控警报脚本
下面这个简单的 shell 脚本可以作为你自定义监控系统的起点。它可以检查连接数、缓存命中率和磁盘使用情况,并在超出阈值时打印警告或严重警报。你可以将其与 Nagios、Zabbix 等监控系统或简单的邮件/Slack 通知集成。
#!/bin/bash # pg_monitor.sh DB_USER="postgres" DB_NAME="production_app" WARNING_CONNECTIONS=150 CRITICAL_CONNECTIONS=180 # Check connections CONNECTIONS=$(sudo -u $DB_USER psql -d $DB_NAME -t -c "SELECT count(*) FROM pg_stat_activity;") if [ "$CONNECTIONS" -gt "$CRITICAL_CONNECTIONS" ]; then echo "CRITICAL: PostgreSQL connections: $CONNECTIONS/$MAX_CONNECTIONS" # Send alert (email, PagerDuty, Slack) elif [ "$CONNECTIONS" -gt "$WARNING_CONNECTIONS" ]; then echo "WARNING: PostgreSQL connections: $CONNECTIONS" fi # Check cache hit ratio CACHE_HIT=$(sudo -u $DB_USER psql -d $DB_NAME -t -c "SELECT round(sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) * 100, 2) FROM pg_statio_user_tables;") if (( $(echo "$CACHE_HIT < 95" | bc -l) )); then echo "WARNING: Low cache hit ratio: $CACHE_HIT%" fi # Check disk usage DISK_USED=$(df /var/lib/postgresql | awk 'NR==2 {print $5}' | sed 's/%//') if [ "$DISK_USED" -gt 80 ]; then echo "CRITICAL: Disk usage: $DISK_USED%" fi我使用 crontab 来安排监控:
# Add to crontab (check every 5 minutes) */5 * * * * /home/postgres/pg_monitor.sh >> /var/log/pg_monitor.log 2>&1
灾难恢复检查清单:为最坏情况做准备
灾难恢复计划的价值在于演练,而不仅仅是文档。当真正的灾难来临时,你不会有时间去思考,只能依赖肌肉记忆和清晰的步骤。
灾难发生之前
# 1. Verify backups work pg_restore -U postgres -d test_db -F c /backup/database.dump # 2. Document recovery procedure # Create recovery_procedure.txt with all steps # 3. Test failover # Promote replica to primary # 4. Document connection strings # Primary: postgresql://user:pass@primary-ip:5432/db # Replica: postgresql://user:pass@replica-ip:5432/db # 5. Monitor backup age find /backup -name "*.dump" -type f -mtime +1 -exec ls -la {} \;当灾难来袭
# 1. Assess the damage sudo systemctl status postgresql sudo journalctl -n 50 -u postgresql # 2. Check data directory integrity sudo -u postgres pg_controldata /var/lib/postgresql/16/main | head -20 # 3. Try recovery first (don't restore unless necessary) sudo systemctl restart postgresql sudo tail -f /var/lib/postgresql/16/main/log/postgresql-*.log # 4. If corrupted, restore from backup # Follow "Strategy 3: Continuous Archiving" section above # 5. Verify data after recovery sudo -u postgres psql -c "SELECT count(*) FROM users;"
常用命令快速参考
这是一个常用 PostgreSQL 命令的备忘单,可以作为你日常工作的快速参考。
# Connection & Authentication psql -U postgres -h localhost -d postgres psql postgresql://user:password@host:5432/dbname # Database Operations \l # List databases \c dbname # Connect to database CREATE DATABASE name; DROP DATABASE name; # Table Operations \dt # List tables \d tablename # Show table structure \di # List indexes \dn # List schemas # User Management \du # List users CREATE USER name WITH PASSWORD 'pass'; DROP USER name; GRANT ALL ON DATABASE db TO user; # Backup & Restore pg_dump -U user -d db -F c -f backup.dump pg_restore -U user -d db -F c backup.dump pg_basebackup -U user -D /path -Fp -Pv # Monitoring SELECT * FROM pg_stat_activity; SELECT datname, pg_size_pretty(pg_database_size(datname)) FROM pg_database; EXPLAIN ANALYZE SELECT ...; # Performance VACUUM ANALYZE; REINDEX TABLE tablename; ALTER TABLE tablename SET (fillfactor=80); # Replication SELECT * FROM pg_stat_replication; SELECT pg_promote();
生产部署检查清单
在将新的 PostgreSQL 数据库投入生产之前,请使用此清单进行最后一次检查,确保没有遗漏任何关键步骤。
☐ postgresql.conf tuned (shared_buffers, wal_level, etc.) ☐ pg_hba.conf restricted (only necessary IPs) ☐ Users created with appropriate privileges ☐ Backup strategy implemented and tested ☐ WAL archiving configured ☐ Monitoring and alerting in place ☐ Replication configured (if high availability needed) ☐ Connection pooling configured (in application) ☐ Slow query logging enabled ☐ Regular VACUUM ANALYZE scheduled ☐ Cache hit ratio verified (>99%) ☐ Disk space monitored ☐ Recovery procedure documented ☐ Disaster recovery tested ☐ pg_stat_statements extension installed ☐ SSL/TLS configured for remote connections
总结:DevOps 之旅
通过本指南,我们一起研究了在生产环境中部署和运维 PostgreSQL 的关键方面。现在大家应该已经掌握了:
- PostgreSQL 如何通过 WAL 可靠地写入数据。
- 如何使用 pg_dump 和持续归档来安全地备份数据。
- 如何利用时间点恢复(PITR)从灾难中恢复。
- 如何通过流复制实现高可用和读扩展。
- 如何通过监控、索引和调优来优化性能。
请记住,这并非成为 DBA 的全部知识,但它为你提供了作为一名优秀的 DevOps 工程师所需的坚实基础,让你足以在生产环境中自信、安全地运行 PostgreSQL。持续学习和实践,你将成为团队中不可或缺的数据库专家。
如有相关问题,请在文章后面给小编留言,小编安排作者第一时间和您联系,为您答疑解惑。
云和安全管理服务商


