
-
Ceph 对象存储多站点复制:第五部分
多站点同步策略介绍
在从 Quincy 开始的 Ceph 版本中,Ceph 对象存储提供了细粒度的存储桶级复制,提供了很多有用的功能。用户可以启用或禁用每个存储桶的同步,从而实现对复制工作流程的精确控制。这支持全区域复制,同时可以排除特定存储桶的复制、将单个源存储桶复制到多目标存储桶,并实现对称和定向数据流配置。下图显示了正在运行的同步策略功能的示例:
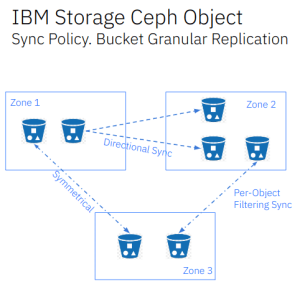
在我们之前的同步模型中,采用的是全区域同步(full zone sync),即所有数据和元数据都会在区域之间同步。而新的同步策略功能为我们提供了更高的灵活性和细粒度控制,允许我们按存储桶(bucket)配置复制。
存储桶同步策略主要应用于归档区域(archive zones)。从归档区域的数据移动是单向的,即所有对象可以从活跃区域(active zone)移动到归档区域,但不能从归档区域移动到活跃区域,因为归档区域是只读的。我们将在博客系列的第六部分详细讨论归档区域。
以下是Quincy和Reef版本中提供的一些功能列表:
Quincy 版本功能:
-
一对一存储桶复制
-
区域组(Zonegroup)级别的策略配置
-
存储桶(Bucket)级别的策略配置
-
可配置的数据流 – 对称模式
-
仅支持全新的多站点部署(Greenfield/New Multisite Deployments)
Reef 版本功能:
-
对象名称过滤
-
从传统的多站点同步(全区域复制)迁移到同步策略(区域组或存储桶级别)
-
归档区域同步策略(按存储桶启用/禁用复制到归档区域)
-
数据流 – 对称或定向模式
-
部分用户 S3 复制 API(GetBucketReplication、PutBucketReplication、DeleteBucketReplication)
-
支持不同存储桶之间的同步(一对一或一对多)
-
目标参数修改:存储类别(Storage Class)、目标所有者转换、用户模式
同步策略的核心概念:
在深入操作之前,我们需要理解以下同步策略的核心概念。同步策略由以下组件构成:
-
组(Groups): 包含一个或多个组,每个组可以包含数据流配置列表。
-
数据流(Data-flow): 定义区域之间复制数据的流向。可以配置为对称数据流(多个区域同步数据),也可以配置为定向数据流(数据从一个区域单向传输到另一个区域)。
-
管道(Pipes): 定义可以使用这些数据流的区域和存储桶及其相关属性。
同步策略组的三种状态:
-
启用(Enabled): 同步被允许并启用。启用后,复制将开始。例如,我们可以启用全区域组同步,然后按存储桶禁用(禁止)同步。
-
允许(Allowed): 同步被允许,但不会自动开始。例如,我们可以将区域组策略配置为“允许”,然后按存储桶启用同步策略。
-
禁止(Forbidden): 该组定义的同步不被允许。
配置级别:
同步策略(组、数据流和管道)可以在区域组和存储桶级别配置。存储桶的同步策略始终是其所属区域组定义策略的子集。例如,如果在区域组级别不允许某种数据流,即使在存储桶级别允许,该数据流也不会生效。更多关于预期行为的详细信息,请参考官方文档。
多站点同步策略配置
以下部分将解释如何使用新的多站点同步策略功能。默认情况下,正如我们在本系列的第一篇文章中设置的那样,多站点复制会将所有元数据和数据在区域组(zonegroup)内的所有区域之间进行复制。在本文的剩余部分中,我们将这种同步方法称为“传统同步”。
正如我们在上一节中解释的那样,同步策略由组(group)、数据流(flow)和管道(pipe)组成。我们首先配置一个非常宽松的区域组策略,允许所有区域上的所有存储桶进行双向流量传输。配置完成后,我们将添加按存储桶的同步策略,这些策略在设计上是区域组策略的子集,并具有更严格的规则集。
添加区域组策略
我们首先创建一个名为
group1的新组,并将其状态设置为“允许”(allowed)。回顾上一节的内容,区域组将允许同步流量流动。策略将被设置为“允许”而非“启用”(enabled)。在“允许”状态下,数据同步不会在区域组级别发生,目的是在按存储桶的基础上启用同步。[root@ceph-node-00 ~]# radosgw-admin sync group create --group-id=group1 --status=allowed --rgw-realm=multisite --rgw-zonegroup=multizg创建对称/双向数据流
接下来,我们创建一个对称/双向数据流,允许数据在
zone1和zone2之间双向同步。[root@ceph-node-00 ~]# radosgw-admin sync group flow create --group-id=group1 --flow-id=flow-mirror --flow-type=symmetrical --zones=zone1,zone2创建管道
最后,我们创建一个管道。在管道中,我们指定要使用的组 ID(
group-id),然后为源和目标存储桶及区域设置通配符*,这意味着所有区域和存储桶都可以作为数据的源和目标进行复制。[root@ceph-node-00 ~]# radosgw-admin sync group pipe create --group-id=group1 --pipe-id=pipe1 --source-zones='*' --source-bucket='*' --dest-zones='*' --dest-bucket='*'更新区域组同步策略
区域组同步策略的修改需要更新周期(period),而存储桶同步策略的修改则不需要更新周期。
[root@ceph-node-00 ~]# radosgw-admin period update --commit提交新周期(period)后,区域组内的所有数据同步将停止,因为我们的区域组策略设置为“允许”。如果将其设置为“启用”,同步将继续以与初始多站点配置相同的方式进行。
区域间的单存储桶双向同步
现在,我们可以按存储桶启用同步。我们将为现有的存储桶
testbucket创建一个存储桶级别的策略规则。请注意,存储桶必须在设置此策略之前存在,并且修改存储桶策略的管理命令必须在主区域(master zone)上运行。不过,存储桶同步策略不需要更新周期。数据流无需更改,因为它继承自区域组策略。存储桶策略的数据流只能是区域组策略中定义的流的子集,管道也是如此。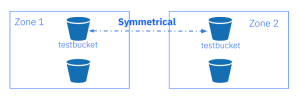
创建存储桶:
[root@ceph-node-00 ~]# aws --endpoint https://s3.zone1.cephlab.com:443 s3 mb s3://testbucket make_bucket: testbucket
创建一个bucket同步组,使用
--bucket参数指定bucket并将状态设置为enabled以便为我们的buckettestbucket启用复制[root@ceph-node-00 ~]# radosgw-admin sync group create --bucket=testbucket --group-id=testbucket-1 --status=enabled无需指定流,因为我们将从 zonegroup 继承流,因此我们只需为存储桶同步策略组定义一个名为
testbucket-1管道。一旦应用此命令,该存储桶的数据同步复制就会开始。[root@ceph-node-00 ~]# radosgw-admin sync group pipe create --bucket=testbucket --group-id=testbucket-1 --pipe-id=test-pipe1 --source-zones='*' --dest-zones='*'[!CAUTION]
注意:您可以安全地忽略以下警告:
WARNING: cannot find source zone id for name=*使用
sync group get命令,可以查看组、流和管道配置。我们在区域组级别运行该命令,我们可以看到状态是allowed。"allowed"我们在存储桶级别运行
sync group get命令并提供--bucket参数。在这种情况下,testbucket的状态为Enabled:[root@ceph-node-00 ~]# radosgw-admin sync group get --bucket testbucket | jq .[0].val.status "Enabled"
另一个有用的命令是
sync info。通过sync info,我们可以预览当前配置将实现的同步复制。因此,例如,在我们当前的区域组同步策略处于allowed状态的情况下,区域组级别不会发生同步,因此同步信息命令将不会显示配置的任何源或目标。[root@ceph-node-00 ~]# radosgw-admin sync info { "sources": [], "dests": [], "hints": { "sources": [], "dests": [] }, "resolved-hints-1": { "sources": [], "dests": [] }, "resolved-hints": { "sources": [], "dests": [] } }
我们还可以在存储桶级别使用
sync info命令,使用--bucket参数,因为我们已经配置了双向管道。我们将使用zone2->zone1作为源,将zone1->zone2作为目的地。这意味着testbucket存储桶上的复制发生在两个方向。如果我们将一个对象从zone1放入testbucket,它将被复制到zone2,如果我们将对象放入zone2它将被复制到zone1。[root@ceph-node-00 ~]# radosgw-admin sync info --bucket testbucket { "sources": [ { "id": "test-pipe1", "source": { "zone": "zone2", "bucket": "testbucket:89c43fae-cd94-4f93-b21c-76cd1a64788d.34553.1" }, "dest": { "zone": "zone1", "bucket": "testbucket:89c43fae-cd94-4f93-b21c-76cd1a64788d.34553.1" }, "params": { "source": { "filter": { "tags": [] } }, "dest": {}, "priority": 0, "mode": "system", "user": "user1" } } ], "dests": [ { "id": "test-pipe1", "source": { "zone": "zone1", "bucket": "testbucket:89c43fae-cd94-4f93-b21c-76cd1a64788d.34553.1" }, "dest": { "zone": "zone2", "bucket": "testbucket:89c43fae-cd94-4f93-b21c-76cd1a64788d.34553.1" }, "params": { "source": { "filter": { "tags": [] } }, "dest": {}, "priority": 0, "mode": "system", "user": "user1" } } ],
因此,例如,如果我们只查看源,可以看到它们会根据运行
radosgw-admin命令的集群而有所不同。例如,从cluster2(ceph-node04) 中,我们将zone1视为源:[root@ceph-node-00 ~]# ssh ceph-node-04 radosgw-admin sync info --bucket testbucket | jq '.sources[].source, .sources[].dest' { "zone": "zone1", "bucket": "testbucket:66df8c0a-c67d-4bd7-9975-bc02a549f13e.45330.2" } { "zone": "zone2", "bucket": "testbucket:66df8c0a-c67d-4bd7-9975-bc02a549f13e.45330.2" }
在
cluster1(ceph-node-00) 中,我们将zone2视为源:[root@ceph-node-00 ~]# radosgw-admin sync info --bucket testbucket | jq '.sources[].source, .sources[].dest' { "zone": "zone2", "bucket": "testbucket:66df8c0a-c67d-4bd7-9975-bc02a549f13e.45330.2" } { "zone": "zone1", "bucket": "testbucket:66df8c0a-c67d-4bd7-9975-bc02a549f13e.45330.2" }
让我们使用 AWS CLI 执行快速测试,以验证配置并确认复制适用于
testbucket。我们将一个对象放入zone1并检查它是否已复制到zone2:[root@ceph-node-00 ~]# aws --endpoint https://s3.zone1.cephlab.com:443 s3 cp /etc/hosts s3://testbucket/firsfile upload: ../etc/hosts to s3://testbucket/firsfile
我们可以检查同步是否已完成
radosgw-admin bucket sync checkpoint命令:[root@ceph-node-00 ~]# ssh ceph-node-04 radosgw-admin bucket sync checkpoint --bucket testbucket 2024-02-02T02:17:26.858-0500 7f3f38729800 1 bucket sync caught up with source: local status: [, , , 00000000004.531.6, , , , , , , ] remote markers: [, , , 00000000004.531.6, , , , , , , ] 2024-02-02T02:17:26.858-0500 7f3f38729800 0 bucket checkpoint complete
检查同步状态的另一种方法是使用
radosgw-admin bucket sync status命令:[root@ceph-node-00 ~]# radosgw-admin bucket sync status --bucket=testbucket realm beeea955-8341-41cc-a046-46de2d5ddeb9 (multisite) zonegroup 2761ad42-fd71-4170-87c6-74c20dd1e334 (multizg) zone 66df8c0a-c67d-4bd7-9975-bc02a549f13e (zone1) bucket :testbucket[66df8c0a-c67d-4bd7-9975-bc02a549f13e.37124.2]) current time 2024-02-02T09:07:42Z source zone 7b9273a9-eb59-413d-a465-3029664c73d7 (zone2) source bucket :testbucket[66df8c0a-c67d-4bd7-9975-bc02a549f13e.37124.2]) incremental sync on 11 shards bucket is caught up with source
我们看到该对象在
zone2中可用。[root@ceph-node-00 ~]# aws --endpoint https://object.s3.zone2.dan.ceph.blue:443 s3 ls s3://testbucket/ 2024-01-09 06:27:24 233 firsfile
由于复制是双向的,我们将一个对象放入
zone2中,并将其复制到zone1:[root@ceph-node-00 ~]# aws --endpoint https://object.s3.zone2.dan.ceph.blue:443 s3 cp /etc/hosts s3://testbucket/secondfile upload: ../etc/hosts to s3://testbucket/secondfile [root@ceph-node-00 ~]# aws --endpoint https://object.s3.zone1.dan.ceph.blue:443 s3 ls s3://testbucket/ 2024-01-09 06:27:24 233 firsfile 2024-02-02 00:40:15 233 secondfile
总结
-
云和安全管理服务商


